Pearson(皮尔逊)相关系数及MATLAB实现
转自:http://blog.csdn.net/wsywl/article/details/5727327
由于使用的统计相关系数比较频繁,所以这里就利用几篇文章简单介绍一下这些系数。
相关系数:考察两个事物(在数据里我们称之为变量)之间的相关程度。
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
Pearson(皮尔逊)相关系数
1、简介
皮尔逊相关也称为积差相关(或积矩相关)是英国统计学家皮尔逊于20世纪提出的一种计算直线相关的方法。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:
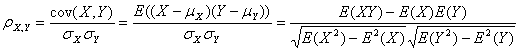
公式二:

公式三:
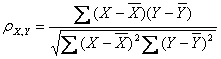
公式四:

以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
2、适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
3、Matlab实现
皮尔逊相关系数的Matlab实现(依据公式四实现):
- function coeff = myPearson(X , Y)
- % 本函数实现了皮尔逊相关系数的计算操作
- %
- % 输入:
- % X:输入的数值序列
- % Y:输入的数值序列
- %
- % 输出:
- % coeff:两个输入数值序列X,Y的相关系数
- %
- if length(X) ~= length(Y)
- error('两个数值数列的维数不相等');
- return;
- end
- fenzi = sum(X .* Y) - (sum(X) * sum(Y)) / length(X);
- fenmu = sqrt((sum(X .^2) - sum(X)^2 / length(X)) * (sum(Y .^2) - sum(Y)^2 / length(X)));
- coeff = fenzi / fenmu;
- end %函数myPearson结束
也可以使用Matlab中已有的函数计算皮尔逊相关系数:
- coeff = corr(X , Y);
4、参考内容
Pearson(皮尔逊)相关系数及MATLAB实现的更多相关文章
- Pearson(皮尔逊)相关系数
Pearson(皮尔逊)相关系数:也叫pearson积差相关系数.衡量两个连续变量之间的线性相关程度. 当两个变量都是正态连续变量,而且两者之间呈线性关系时,表现这两个变量之间相关程度用积差相关系数, ...
- np.corrcoef()方法计算数据皮尔逊积矩相关系数(Pearson's r)
上一篇通过公式自己写了一个计算两组数据的皮尔逊积矩相关系数(Pearson's r)的方法,但np已经提供了一个用于计算皮尔逊积矩相关系数(Pearson's r)的方法 np.corrcoef() ...
- pandas通过皮尔逊积矩线性相关系数(Pearson's r)计算数据相关性
皮尔逊积矩线性相关系数(Pearson's r)用于计算两组数组之间是否有线性关联,举个例子: a = pd.Series([1,2,3,4,5,6,7,8,9,10]) b = pd.Series( ...
- 皮尔逊(Pearson)系数矩阵——numpy
一.原理 注意 专有名词.(例如:极高相关) 二.代码 import numpy as np f = open('../file/Pearson.csv', encoding='utf-8') dat ...
- 皮尔逊相似度计算的例子(R语言)
编译最近的协同过滤算法皮尔逊相似度计算.下顺便研究R简单使用的语言.概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 由于这里每一个数都是等概率的.所以就当做是数 ...
- 皮尔逊残差 | Pearson residual
参考:Pearson Residuals 这些概念到底是写什么?怎么产生的? 统计学功力太弱了!
- Spark Mllib里的如何对两组数据用皮尔逊计算相关系数
不多说,直接上干货! import org.apache.spark.mllib.stat.Statistics 具体,见 Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mlli ...
- 从欧几里得距离、向量、皮尔逊系数到http://guessthecorrelation.com/
一.欧几里得距离就是向量的距离公式 二.皮尔逊相关系数反应的就是线性相关 游戏http://guessthecorrelation.com/ 的秘诀也就是判断一组点的拟合线的斜率y/x ------- ...
- Python基于皮尔逊系数实现股票预测
# -*- coding: utf-8 -*- """ Created on Mon Dec 2 14:49:59 2018 @author: zhen "&q ...
随机推荐
- js日期比较
alert(EDate< new Date().format("yyyy-MM-dd hh:mm:ss")); Date.prototype.format = functio ...
- 简易的IOS位置定位服务
有时一些小的需求,其实只是需要得知当前IOS APP使用的地点,有些只是想精确到城市级别,并不需要任何地图. 有了以下的简易实现: @interface MainViewController ()&l ...
- nodejs模块——fs模块
fs模块用于对系统文件及目录进行读写操作. 一.同步和异步 使用require('fs')载入fs模块,模块中所有方法都有同步和异步两种形式. 异步方法中回调函数的第一个参数总是留给异常参数(exce ...
- linux下yum命令出现Loaded plugins: fastestmirror
yum install的时候提示:Loaded plugins: fastestmirror fastestmirror是yum的一个加速插件,这里是插件提示信息是插件不能用了. 不能用就先别用呗,禁 ...
- 还是不想改报告,伊阿忆啊哟-Linux基础继续
hi 虽然今天是最最美好的周六(前不着工作日后不着工作日),但老子还要来改报告,但额就是不想改,你拿我有啥办法啊... 争取完结Linux基础 一.Linux常用命令(三) 4.帮助命令 4.1 帮助 ...
- 应用程序Cache对象到高性能Memcached学习之路
来源:微信公众号CodeL 以下是个人学习之路的简单分享,不足之处欢迎大神们批评指正! 在网站开发的初期,我们没有考虑更多的东西,也没有对缓存进行系统的设计,而是直接使用了应用程序缓存对象Cache, ...
- 在ubunt14.04(linux)下利用cmake编译运行opencv程序
今天在电脑上安装好了opencv环境,迫不及待的想写个程序来测试一下.但是在windows下我们用vs等集成开发工具.可是在linux下我们应该怎么办呢? 这里我们用了opencv推荐的cmake来编 ...
- Zygote进程【1】——Zygote的诞生
在Android中存在着C和Java两个完全不同的世界,前者直接建立在Linux的基础上,后者直接建立在JVM的基础上.zygote的中文名字为"受精卵",这个名字很好的诠释了zy ...
- 适配ipone5
PROJECT和TARGETS都需要设置
- row_number()over(partition by 字段 order by 字段)ID,修改重复行的字段值。
案例分析: 现在要查询一个表单里面的运费结果,但是他还有分录,为了显示分录,必须把表头显示出来,问题是,他要查询运费的合计, 但是这样就会导致重复行也加进去了,这样显然数据不准,为此,可以把重复的行设 ...