Python多进程实现并行化随机森林
文章目录
1. 前言
Python其实已经实现过随机森林, 而且有并行化的参数n_jobs 来设置可以使用多个可用的cpu核并行计算。
n_jobs : int or None, optional (default=None)
The number of jobs to run in parallel for both fit and predict. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
当然我们使用的是多进程来实现并行化, 和scikit-learn有些不同
2. 随机森林原理
随机森林是一种集成算法(Ensemble Learning),它属于Bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。其可以取得不错成绩,主要归功于“随机”和“森林”,一个使它具有抗过拟合能力,一个使它更加精准。
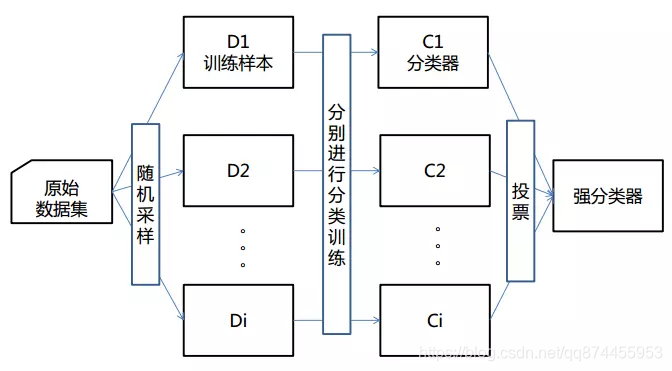
Bagging
Bagging也叫自举汇聚法(bootstrap aggregating),是一种在原始数据集上通过有放回抽样重新选出k个新数据集来训练分类器的集成技术。它使用训练出来的分类器的集合来对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签。此类算法可以有效降低bias,并能够降低variance。
3.实现原理
3.1并行化训练
由于随机森林是 通过bagging方法分成多个数据集,然后在生成的数据集上训练生成多个决策树, 因为每个决策树是相互独立的, 则可以在开启多个进程,每个进程都生成决策树, 然后把生成的决策树放到队列,用于训练
3.1.1训练函数
首先平均分出每个线程应该生成几颗决策树, 然后生成进程, 进行训练, 把训练生成的决策树加入到决策树队列(决策树森林)中, 这里用的决策树是直接调用的库决策树,若有兴趣,可以单撸一个决策树出来。
注意这里我选择让每个进程生成的决策树的个数相同, 所以 参数输入的决策树个数可能不是实际生成的决策树个数,例如 100颗决策树 8个进程, 则每个进程只会生成 int(100/8) = 12颗决策树
def fit(self, X, Y):
# 分出每个线程 应该生成几颗决策树
job_tree_num = int ( self.n_estimators / self.n_jobs)
processes = list()
#随机森林的决策树参数
dtr_args = {
"criterion": self.criterion,
"max_depth": self.max_depth,
"max_features": self.max_features,
"max_leaf_nodes": self.max_leaf_nodes,
"min_impurity_decrease": self.min_impurity_decrease,
"min_impurity_split": self.min_impurity_split,
"min_samples_leaf": self.min_samples_leaf,
"min_samples_split": self.min_samples_split,
"min_weight_fraction_leaf": self.min_weight_fraction_leaf,
"random_state": self.random_state,
"splitter": self.splitter
}
# 生成N个进程
for i in range(self.n_jobs):
# 参数
#job_forest_queue 为决策树队列 每个进程生成的决策树将加入到此队列 这是随机森林对象的一个属性
#i 为进程号
#job_tree_num 表示该进程需要生成的决策树
#X Y 表示训练数据 和结果数据
#dtr_args 表示传入的决策树参数
p = Process(target=signal_process_train, args=(self.job_forest_queue, i,job_tree_num , X, Y, dtr_args))
print ('process Num. ' + str(i) + " will start train")
p.start()
processes.append(p)
for p in processes:
p.join()
print ("Train end")
3.1.2 单进程训练函数
生成数据集模块——生成部分数据集
首先生成一个index, 长度为原来数据集的0.7倍,然后将其打乱,按照打乱的index加入数据,即可生成打乱的数据集, 大小为原来数据集的0.7倍
len = int(Y.shape[0] * 0.7)
indexs = np.arange(len)
np.random.shuffle(indexs)
x = []
y = []
for ind in indexs:
x.append(X.values[ind])
y.append(Y.values[ind])
单进程训练函数代码
循环生成决策树, 并且把生成的决策树加入到队列中
#单进程训练函数
def signal_process_train(job_forest_queue,process_num,job_tree_num,X, Y, dtr_args):
#循环生成决策树, 并且把生成的决策树加入到job_forest_queue 队列中
for i in range(0, job_tree_num):
# 使用bootstrap 方法生成 1个 训练集
len = int(Y.shape[0] * 0.7)
indexs = np.arange(len)
np.random.shuffle(indexs)
x = []
y = []
for ind in indexs:
x.append(X.values[ind])
y.append(Y.values[ind])
# 对这个样本 进行训练 并且根据传入的决策树参数 生成1棵决策树
dtr = DecisionTreeRegressor(n_job=1 ,criterion=dtr_args['criterion'], max_depth=dtr_args['max_depth'],
max_features=dtr_args['max_features'],max_leaf_nodes=dtr_args['max_leaf_nodes'],
min_impurity_decrease=dtr_args['min_impurity_decrease'],
min_impurity_split=dtr_args['min_impurity_split'],
min_samples_leaf=dtr_args['min_samples_leaf'], min_samples_split=dtr_args['min_samples_split'],
min_weight_fraction_leaf=dtr_args['min_weight_fraction_leaf'],
random_state=dtr_args['random_state'], splitter=dtr_args['splitter'])
dtr.fit(x,y)
if (i% int(job_tree_num/10 or i<10) == 0):
print ('process Num. ' + str(process_num) + " trained " + str(i) + ' tree')
# 决策树存进森林(决策树队列)
job_forest_queue.put(dtr)
print('process Num. ' + str(process_num) + ' train Done!!')
3.2 并行化预测
同理, 生成多个进程,每个进程在随机森林里得到树来进行预测, 每个进程返回这个进程处理的所有决策树的预测结果的平均值, 然后将每个进程返回的平均值再一次进行平均,则得到结果
3.2.1 预测函数
def predict(self, X):
result_queue = Manager().Queue()
processes = list()
# 分出每个线程 应该预测几颗决策树
job_tree_num = int(self.n_estimators / self.n_jobs)
# 生成N个进程
for i in range(self.n_jobs):
# 参数
# job_forest_queue 为决策树队列 这是随机森林对象的一个属性
# i 为进程号
# job_tree_num 表示该进程需要生成的决策树
# X 表示待预测数据
# result_queue 表示用于存放预测结果的数据
p = Process(target=signal_process_predict, args=(self.job_forest_queue, i, job_tree_num, X, result_queue))
print('process Num. ' + str(i) + " will start predict")
p.start()
processes.append(p)
for p in processes:
p.join()
result = np.zeros(X.shape[0])
#把每个进程的平均结果再一次加起来求平均, 得到最终结果
for i in range(result_queue.qsize()):
result = result + result_queue.get()
result = result / self.n_jobs
print("Predict end")
return result
3.2.2 单进程预测函数
每一次去除一棵树, 预测结果,然后将结果加起来,最后进程结束时, 把预测结果求平均,进行返回
#单进程预测函数
def signal_process_predict(job_forest_queue,process_num,job_tree_num,X,result_queue):
# 生成结果矩阵
result = np.zeros(X.shape[0])
for i in range(job_tree_num):
# 从队列中取出一颗树 进行预测
tree = job_forest_queue.get()
result_single = tree.predict(X)
# 将得出的结果加到总结果中
result = result +result_single
# 算出平均结果 放入结果队列中
result = result / job_tree_num
result_queue.put(result)
print('process ' + str(process_num) + ' predict Done!!')
4. 并行化结果分析
可以发现当进程数增加时, 训练时间会减少,并行化成功
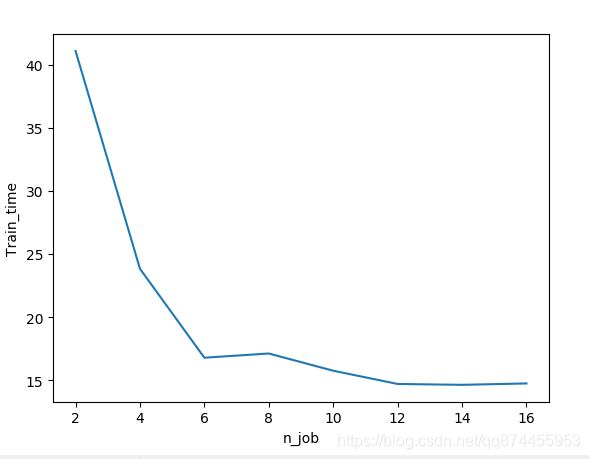
但是当进程数到一定大小后, 进程间的调度可能会消耗更多时间, 减少也不明显了
5. 源码
完整github地址如下: 若有错误,欢迎指正!
https://github.com/wangjiwu/parallel_random_forest
参考资料
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
https://www.jianshu.com/p/a779f0686acc
https://docs.python.org/3.7/library/multiprocessing.html#multiprocessing.Queue
https://www.cnblogs.com/shixisheng/p/7119217.html
Python多进程实现并行化随机森林的更多相关文章
- 如何在Python中从零开始实现随机森林
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 决策树可能会受到高度变异的影响,使得结果对所使用的特定测试数据而言变得脆弱. 根据您的测试数据样本构建多个模型(称为套袋)可以减少这种差异,但是 ...
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 随机森林random forest及python实现
引言想通过随机森林来获取数据的主要特征 1.理论根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系 ...
- sklearn_随机森林random forest原理_乳腺癌分类器建模(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 决策树--------------------------------------------- ...
- Python 实现的随机森林
随机森林是一个高度灵活的机器学习方法,拥有广泛的应用前景,从市场营销到医疗保健保险. 既可以用来做市场营销模拟的建模,统计客户来源,保留和流失.也可用来预测疾病的风险和病患者的易感性. 随机森林是一个 ...
- Python中随机森林的实现与解释
使用像Scikit-Learn这样的库,现在很容易在Python中实现数百种机器学习算法.这很容易,我们通常不需要任何关于模型如何工作的潜在知识来使用它.虽然不需要了解所有细节,但了解机器学习模型是如 ...
随机推荐
- 测试人员应该掌握的oracle知识体系
闲来无事,总结了一下,软件测试人员应该掌握的基本的oracle数据库知识体系 1.安装 1.1 oracle安装 1.2 oracle升级 1.3 oracle补丁 2.管理 2.1数据库创建(dbc ...
- Ethical Hacking - NETWORK PENETRATION TESTING(11)
Securing your Network From the Above Attacks. Now that we know how to test the security of all known ...
- 关于ES6的let和const
变量 var存在的问题 可以重复声明 无法限制修改 没有块级作用域 (在全局范围内有效) 存在变量提升 const/let 不可以重复声明 let a = 1; let a = 2; var b = ...
- Java Web(3)-XML
一.XML简介 1. 什么是xml? xml 是可扩展的标记性语言 2. xml的作用? 用来保存数据,而且这些数据具有自我描述性 它还可以做为项目或者模块的配置文件 还可以做为网络传输数据的格式(现 ...
- Robot Framework 使用常见问题汇总
一 安装过程 windows可以使用pip命令进行一系列安装,一定要使用管理员打开cmd窗口进行安装,不然可能后续会有很多自定义库无法使用的问题. 1 ride安装后打不开 解决方案 https:/ ...
- Redis服务之常用配置(二)
上一篇博客我们聊了下redis的INCLUDE.NETWORK.GENERAL配置段相关配置和说明,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/133831 ...
- statsmodels 示例
Statsmodels 示例 https://www.statsmodels.org/stable/examples/index.html
- C/C++编程笔记:C语言NULL值和数字 0 值区别及NULL详解
在学习C语言的时候,我们常常会碰到C语言NULL值和数字 0 ,很多小伙伴搞不清楚他们之间的一个区别,今天我们就了解一下他们之间的区别,一起来看看吧! 先看下面一段代码输出什么: 输出<null ...
- 记502 dp专练
趁着503的清早 我还算清醒把昨天老师讲的内容总结一下,昨天有点迷了 至使我A的几道题都迷迷糊糊的.(可能是我太菜了) 这道题显然是 数字三角形的变形 好没有经过认真思考然后直接暴力了 这是很不应该的 ...
- Java主类的装载
在JavaMain()函数中调用LoadMainClass()函数加载Java主类.LoadMainClass()函数的实现如下: /* * Loads a class and verifies th ...