【原创】大数据基础之Chronos

官方:https://mesos.github.io/chronos/
mesos集群中替换crontab
Chronos
A fault tolerant job scheduler for Mesos which handles dependencies and ISO8601 based schedules
简介
Chronos is a replacement for cron. It is a distributed and fault-tolerant scheduler that runs on top of Apache Mesos that can be used for job orchestration. It supports custom Mesos executors as well as the default command executor. Thus by default, Chronos executes sh (on most systems bash) scripts.
Chronos can be used to interact with systems such as Hadoop (incl. EMR), even if the Mesos slaves on which execution happens do not have Hadoop installed. Chronos is also natively able to schedule jobs that run inside Docker containers.
Chronos has a number of advantages over regular cron. It allows you to schedule your jobs using ISO8601 repeating interval notation, which enables more flexibility in job scheduling. Chronos also supports the definition of jobs triggered by the completion of other jobs. It supports arbitrarily long dependency chains.
工作过程
Internally, the Chronos scheduler main loop is quite simple. The pattern is as follows:
- Chronos reads all job state from the state store (ZooKeeper)
- Jobs are registered within the scheduler and loaded into the job graph for tracking dependencies.
- Jobs are separated into a list of those which should be run at the current time (based on the clock of the host machine), and those which should not.
- Jobs in the list of jobs to run are queued, and will be launched as soon as a sufficient offer becomes available.
- Chronos will sleep until the next job is scheduled to run, and begin again from step 1.
chronos通过zk来维护任务状态,任务会随机分配到一个mesos slave节点运行
安装
前提是已经部署好zk和mesos
$ docker run --net=host -e PORT0=8080 -e PORT1=8081 mesosphere/chronos:v3.0.0 --zk_hosts $zk_ip:2181 --master zk://$zk_ip:2181/mesos
其中第一个端口是http端口
使用
访问 http://localhost:8080
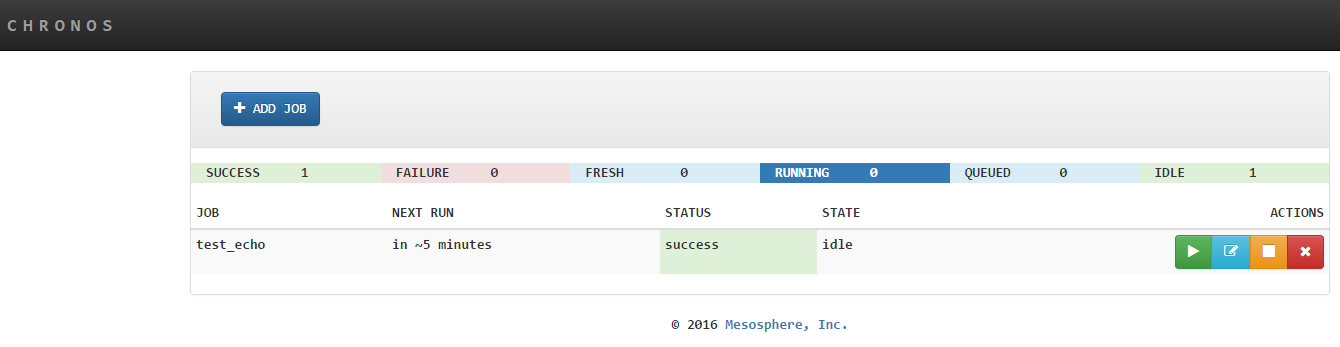
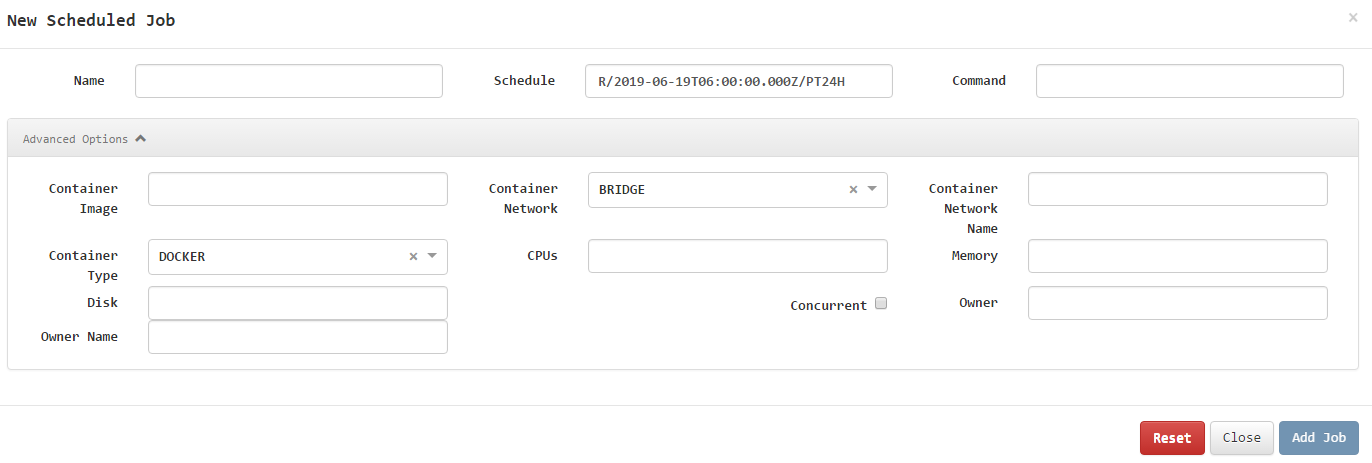
添加任务

只需要配置
- 任务名称
- 时间间隔
- 要执行的shell命令/脚本
其中shell命令也可以替换为启动docker容器,如下图:
时间间隔格式示例:
R/2019-06-19T14:40:00.000+08:00/PT5M
以上配置为在北京时间下每5分钟执行
任务执行之后可以在mesos上找到任务执行记录
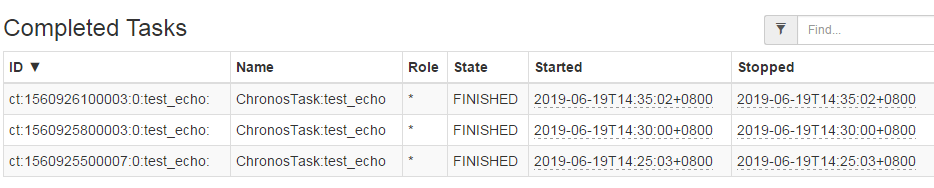
任务定义以及执行状态都可以在zk上找到
[zk: localhost:2181(CONNECTED) 7] get /chronos/state/state/J_ $job_name
只需要完成一个通用的shell脚本,这个shell脚本根据参数首先将一个hdfs目录(任务目录,包括脚本和配置等)下载到本地,然后进入目录执行参数中的命令,即可实现分布式任务调度;
$ do_job.sh $hdfs_path $cmd
参考:https://hub.docker.com/r/mesosphere/chronos/
【原创】大数据基础之Chronos的更多相关文章
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
随机推荐
- 如何在linux中发送邮件,使用163邮箱发信。
linux中,可以使用mail命令往外发送邮件,在使用前,只需要指定如下简单配置即可,这里演示用 163.com 邮箱发送至 qq.com 编辑 /etc/mail.rc,写入下方的参数 se ...
- quartz 定时器时间表达式
按顺序依次为 秒(~) 分钟(~) 小时(~) 天(月)(~,但是你需要考虑你月的天数) 月(~) 天(星期)(~ =SUN 或 SUN,MON,TUE,WED,THU,FRI,SAT) .年份(-) ...
- LC 265. Paint House II
There are a row of n houses, each house can be painted with one of the k colors. The cost of paintin ...
- ValueAnimator
import android.animation.ValueAnimator; import android.os.Bundle; import android.support.v7.app.AppC ...
- DBUtil连接数据库
1. SQL server连接: 数据库不同架包就不同 SQL server 使用的架包是(sqljdbc4.jar) 2. Mysql (MariaDB同理) SQL server 使用的架包是(m ...
- 公式test
- TextInput组件的常用属性
1.TextInput组件基本介绍: TextInput是一个允许用户在应用中通过键盘输入文本的基本组件.本组件的属性提供了多种特性的配置,譬如自动完成.自动大小写.占位文字,以及多种不同的键盘类型( ...
- 后缀数组--summer-work之我连模板题都做不起
这章要比上章的AC自动机要难理解. 这里首先要理解基数排序:基数排序与桶排序,计数排序[详解] 下面通过这个积累信心:五分钟搞懂后缀数组!后缀数组解析以及应用(附详解代码) 下面认真研读下这篇: [转 ...
- 小程序插件使用wx.createSelectorQuery()获取不到节点信息
发现小程序一个bug, 在小程序插件中使用wx.createSelectorQuery()获取不到节点信息,需要在后面加入in(this) 例如: const query = wx.createSel ...
- Kaggle初体验之泰坦尼特生存预测
Kaggle初体验之泰坦尼特生存预测 学习完了决策树的ID3.C4.5.CART算法,找一个试手的地方,Kaggle的练习赛泰坦尼特很不错,记录下 流程 首先注册一个账号,然后在顶部菜单栏Co ...