Hadoop集群安装压缩工具Snappy,用于Hbase
最近项目中要用到Hadoop和Hbase,为了节省服务器的存储成本,并提高吞吐,安装并开启HBase的数据压缩为Snappy。
主流的HBase压缩方式有GZip | LZO | Snappy,Snappy的压缩比会稍微优于LZO。相比于gzip,Snappy压缩率不如gzip,但是压缩和解压缩速度有很大优势,而且节省cpu资源。
Hadoop默认没有支持snappy压缩,需要我们自己编译 才能支持snappy的压缩。
一、安装包准备
jdk1.8
apache-maven-3.6.1-bin.tar.gz
snappy-1.1.1.tar.gz
protobuf-2.5.0.tar.gz
hadoop-2.7.3-src.tar.gz
二、安装基础软件
yum -y install gcc gcc-c++ libtool cmake maven zlib-devel
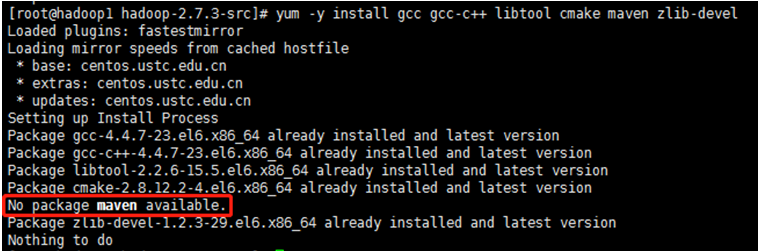
确保以上基础软件都安装成功,如maven出现以上情况,则按下面方法安装maven。
三、安装maven
3.1. 上传解压
上传安装包到/usr/local并解压安装包,用root用户解压maven安装包到/usr/local目录下
cd /usr/local tar -xvf apache-maven-3.6.1-bin.tar
3.2. 配置环境变量
编辑/etc/profile文件,添加如下代码:
MAVEN_HOME=/usr/local/apache-maven-3.6.1
export MAVEN_HOME
export PATH=${PATH}:${MAVEN_HOME}/bin

3.3. 环境变量生效
保存文件,并运行如下命令使环境变量生效:
source /etc/profile
3.4. 验证
在控制台输入如下命令,如果能看到Maven相关版本信息,则说明Maven已经安装成功
mvn –v

四、安装snappy
4.1.上传解压
上传安装包到/usr/local并解压安装包,用root用户解压snappy安装包到/usr/local目录下,并按顺序执行以下命令,进行安装:
cd /usr/local tar -xvf snappy-1.1.1.tar.gz cd snappy-1.1.1 ./configure make && make install
4.2.验证
查看snappy是否安装成功
ll /usr/local/lib/ | grep snappy

五、安装protobuf
下载地址:https://github.com/google/protobuf/releases/tag/v2.5.0
5.1.上传解压
上传安装包到/usr/local并解压安装包,用root用户解压protobuf安装包到/usr/local目录下,按顺序执行以下命令,进行安装:
cd /usr/local tar -xvf protobuf-2.5.0.tar.gz cd protobuf-2.5.0 ./configure make && make install
5.2.验证
查看protobuf是否安装完成
protoc –version

六、编译生成hadoop-native-Libraries
hadoop源码下载地址:http://archive.apache.org/dist/hadoop/core/
6.1.上传解压
上传安装包到/usr/local并解压安装包,用root用户解压hadoop安装包到/usr/local目录下,按顺序执行以下命令,进行安装:
cd /usr/local tar -xvf hadoop-2.7.3-src.tar
6.2.编译生成hadoop-native-Libraries
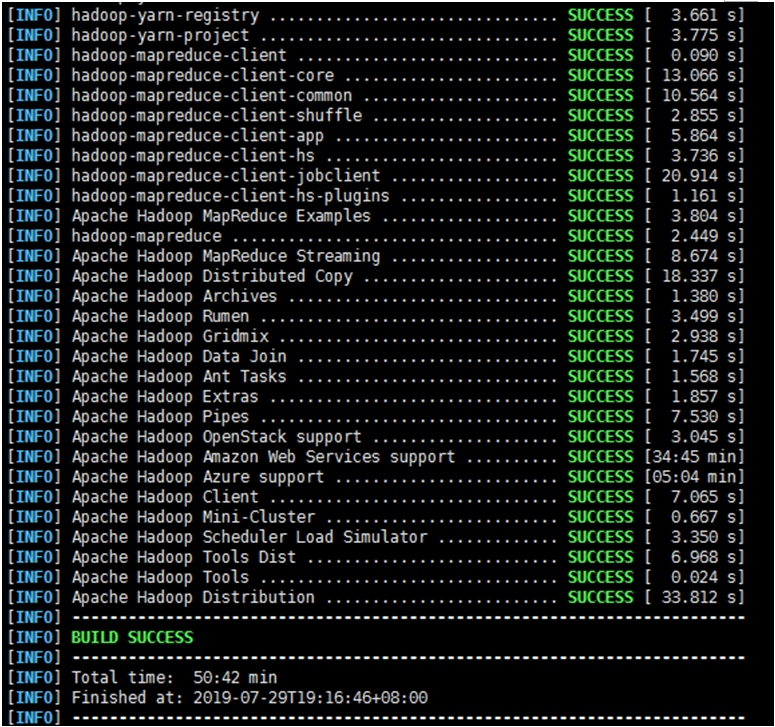
执行以下命令进行编译,因为通过通过mvn安装,会从官方下载相关所需文件,时间漫长,我大概花了3小时左右,如果出现失败终止了,可重新执行以下命令。
注意:为了提高下载速度。可以修改下载源(添加国内阿里的maven仓库)
mvn package -DskipTests -Pdist,native -Dtar -Dsnappy.lib=/usr/local/lib -Dbundle.snappy
6.3.配置Hadoop和Hbase
1、 进入/usr/local/hadoop-2.7.3-src/hadoop-dist/target/hadoop-2.7.3/lib/native目录,检查是否存在以下文件:
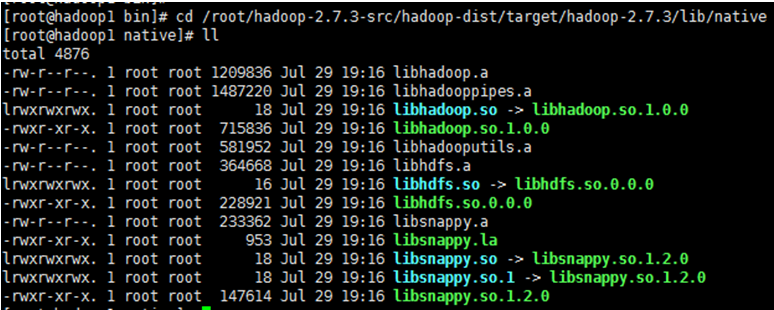
2、 将以上目录下的文件拷贝到hadoop集群中的hadoop下的lib/native目录,如果没有则新建,集群中的各节点均需拷贝;
3、 将以上目录下的文件拷贝到hbase下的lib/native/Linux-amd64-64目录下,如果没有则新建,集群中的各节点均需拷贝;
4、 进入/usr/local/hadoop-2.7.3/etc/hadoop目录下修改core-site.xml配置文件
vi core-site.xml
在文件中加入如下内容:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
6.4.重启Hadoop和Hbase
在主节点,依次停止:Hbase、Hadoop服务,然后在依次启动Hadoop、Hbase服务。
这里要注意的是:Hbase启动依赖于Hadoop,会去找Hadoop的hdfs,所以要先启动好Hadoop服务
6.5.验证
1、 进入安装了Hbase的linux控制台,输入hbase shell 命令进行登陆;

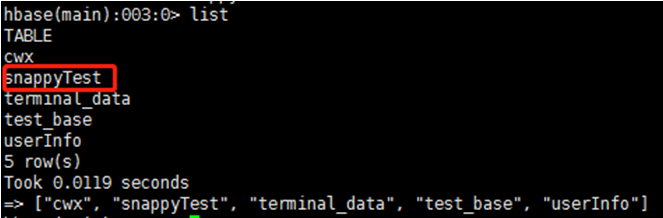
2、 执行以下命令创建表,指定压缩为snappy
create 'snappyTest',{NAME=>'f',COMPRESSION => 'SNAPPY'}

以上提示说明创建成功,可在进一步用list命令查看:
结语
费了好大的劲,终于安装成功,网上各种搜,方法五花八门,真搞不懂安装snappy为什么要这么麻烦,竟然还要配置Hadoop,先在这里记录总结一下,后续有时间在研究吧。
网上还有说要编译安装hadoop-snappy的,查了一下,在hadoop2.x源码已经集成了Snappy压缩了,所以编译安装hadoop-snappy 根本是多余的。
Hadoop集群安装压缩工具Snappy,用于Hbase的更多相关文章
- Apache Hadoop 集群安装文档
简介: Apache Hadoop 集群安装文档 软件:jdk-8u111-linux-x64.rpm.hadoop-2.8.0.tar.gz http://www.apache.org/dyn/cl ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- Apache Hadoop集群安装(NameNode HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 ).HA的集 ...
- Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 192.16 ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置(三台机器跑集群)
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- Hadoop集群安装-CDH5(5台服务器集群)
CDH5包下载:http://archive.cloudera.com/cdh5/ 架构设计: 主机规划: IP Host 部署模块 进程 192.168.254.151 Hadoop-NN-01 N ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
随机推荐
- MyBatis-13-缓存
13.缓存(了解) 13.1.简介 查询 : 连接数据库,耗资源! 一次查询的结果,给他暂存在一个可以直接取到的地方!--->内存 : 缓存 我们再次查询相同数据的时候,直接走缓存,就不用走数据 ...
- Mapreduce案例之找共同好友
数据准备: A:B,C,D,F,E,OB:A,C,E,KC:F,A,D,ID:A,E,F,LE:B,C,D,M,LF:A,B,C,D,E,O,MG:A,C,D,E,FH:A,C,D,E,OI:A,OJ ...
- 清除文本中Html的标签
/// <summary> /// 清除文本中Html的标签 /// </summary> /// <param name="Content"> ...
- CI环境搭建下-Jenkis与git结合
设置权限: 也可以通过公私钥的方式,添加权限,公私钥填写在gitblit用户中心: Jenkins中填写私钥: 添加: 添加后如果仍然报错,是因为windows下要使用http的地址. 在此,可 ...
- mybatis标签selectkey无法返回主键值
- ZOJ - 4114 Flipping Game
ZOJ - 4114 Flipping Game 题目大意:给出两个串s,t,n个灯泡的序列,1代表开着,0代表关着,一共操作k轮,每轮改变m个灯泡的状态,问最终能把s串变成t串的方案数. 坤神题解. ...
- ubuntu安装chrome driver
首先下载Chrome Driver(Firefox Driver的安装与该步骤相同) 链接: http://chromedriver.storage.googleapis.com/index.html ...
- x86—EFLAGS寄存器详解[转]
鉴于EFLAGS寄存器的重要性,所以将这一部分内容从处理器体系结构及寻址模式一文中单独抽出另成一文,这部分内容主要来自Intel Developer Mannual,在后续的内核系列中遇到的许多和EF ...
- 集合家族——LinkedList
一.概述: LinkedList 与 ArrayList 一样实现 List 接口,只是 ArrayList 是 List 接口的大小可变数组的实现,LinkedList 是 List 接口链表的实现 ...
- NSLock的一些使用
在多线程的编程环境中,锁的使用必不可少! 使用时,基本方法就是: [lock lock]; // 加锁 [obj yourMethod]; // 处理你的操作 [lock unlock]; // 解锁 ...