Scrapy - 小说爬虫
实例解析 - 小说爬虫
页面分析
共有三级页面
一级页面 大目录
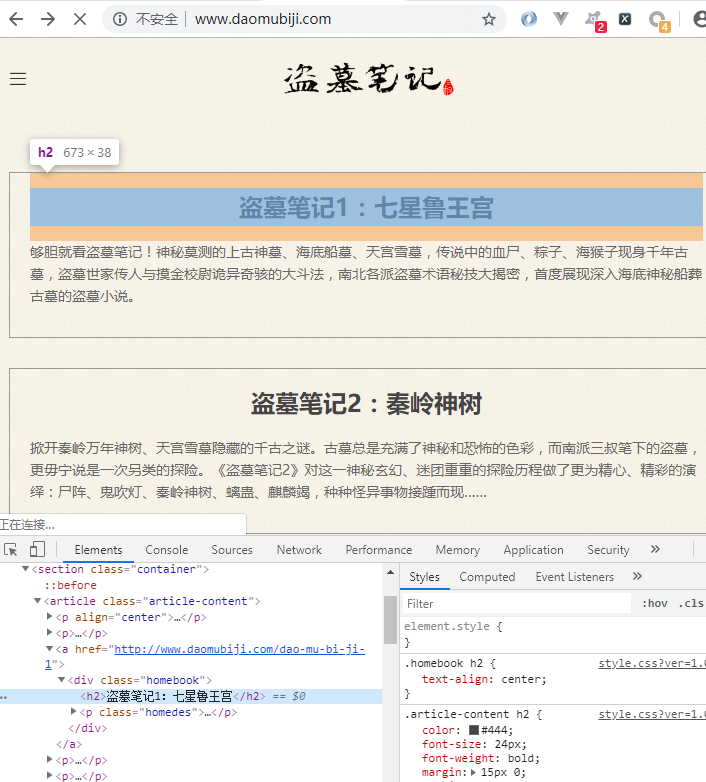
二级页面 章节目录
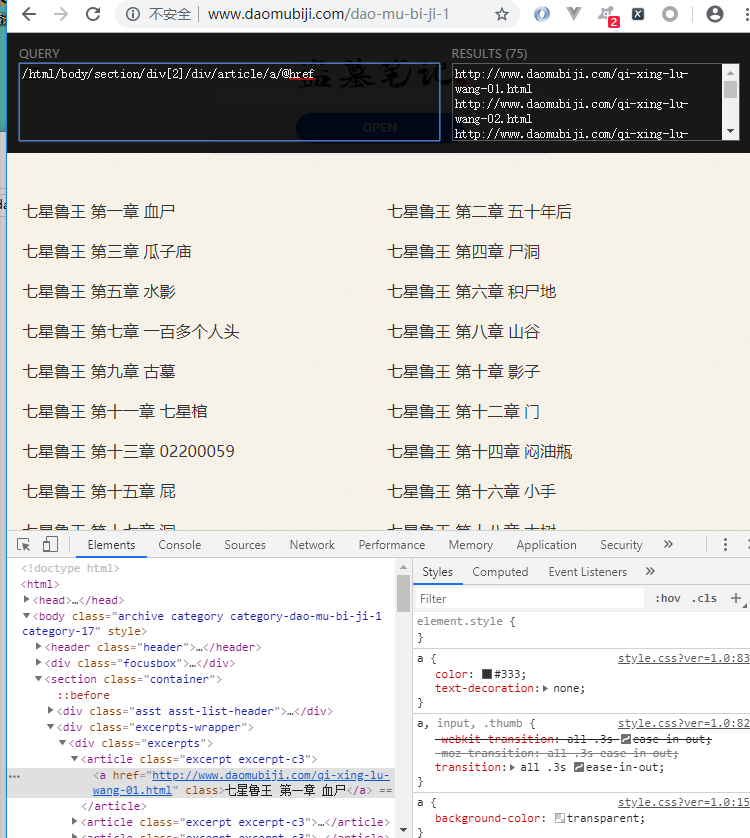
三级界面 章节内容
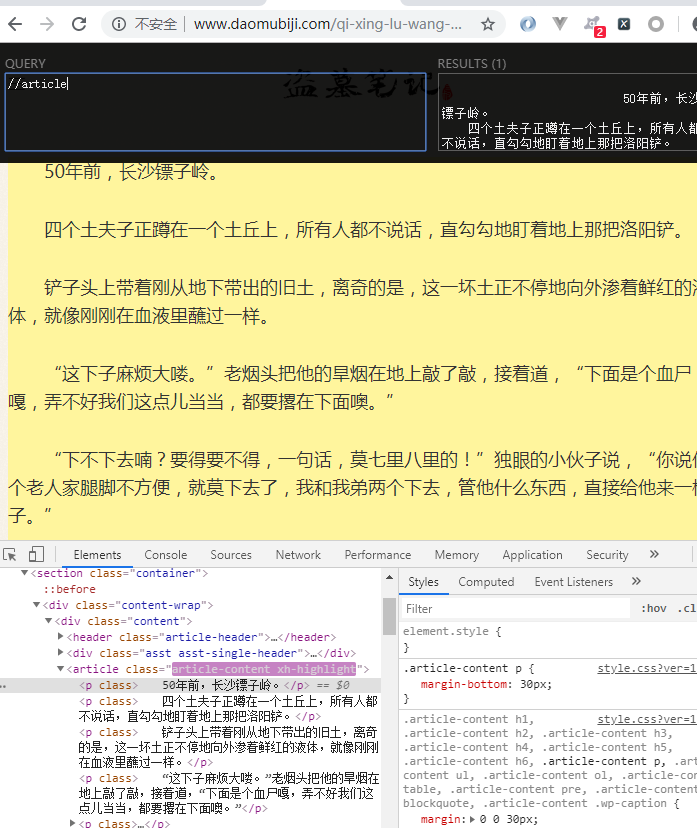
爬取准备
一级界面
http://www.daomubiji.com/
二级页面xpath
直接复制的 xpath
/html/body/section/article/a/@href
这里存在着反爬虫机制, 改变了页面结构
在返回的数据改变了页面结构, 需要换为下面的 xpath 才可以
//ul[@class="sub-menu"]/li/a/@href
三级页面xpath
//article
项目准备
begin.py
pycharm 启动文件,方便操作
from scrapy import cmdline
cmdline.execute('scrapy crawl daomu --nolog'.split())
settings.py
相关的参数配置
BOT_NAME = 'Daomu'
SPIDER_MODULES = ['Daomu.spiders']
NEWSPIDER_MODULE = 'Daomu.spiders'
ROBOTSTXT_OBEY = False LOG_LEVEL = 'WARNING'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
ITEM_PIPELINES = {
'Daomu.pipelines.DaomuPipeline': 300,
}
逻辑代码
items.py
指定相关期望数据
-*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class DaomuItem(scrapy.Item):
# define the fields for your item here like:
# 卷名
juan_name = scrapy.Field()
# 章节数
zh_num = scrapy.Field()
# 章节名
zh_name = scrapy.Field()
# 章节链接
zh_link = scrapy.Field()
# 小说内容
zh_content = scrapy.Field()
daomu.py
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from ..items import DaomuItem class DaomuSpider(scrapy.Spider):
name = 'daomu'
allowed_domains = ['www.daomubiji.com']
start_urls = ['http://www.daomubiji.com/'] # 解析一级页面,提取 盗墓笔记1 2 3 ... 链接
def parse(self, response):
# print(response.text)
one_link_list = response.xpath(
'//ul[@class="sub-menu"]/li/a/@href'
).extract()
# print('*' * 50)
# print(one_link_list)
# 把链接交给调度器入队列
for one_link in one_link_list:
yield scrapy.Request(
url=one_link,
callback=self.parse_two_link
) # 解析二级页面
def parse_two_link(self, response):
# 基准xpath,匹配所有章节对象列表
article_list = response.xpath('//article')
# print(article_list)
# 依次获取每个章节信息
for article in article_list:
# 创建item对象
item = DaomuItem()
info = article.xpath('./a/text()'). \
extract_first().split()
print(info) # ['秦岭神树篇', '第一章', '老痒出狱']
item['juan_name'] = info[0]
item['zh_num'] = info[1]
item['zh_name'] = info[2]
item['zh_link'] = article.xpath('./a/@href').extract_first()
# 把章节链接交给调度器 yield scrapy.Request(
url=item['zh_link'],
# 把item传递到下一个解析函数
meta={'item': item},
callback=self.parse_three_link
) # 解析三级页面
def parse_three_link(self, response):
item = response.meta['item']
# 获取小说内容
item['zh_content'] = '\n'.join(response.xpath(
'//article[@class="article-content"]'
'//p/text()'
).extract()) yield item # '\n'.join(['第一段','第二段','第三段'])
pipelines.py
持久化处理
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class DaomuPipeline(object):
def process_item(self, item, spider): filename = 'downloads/{}-{}-{}.txt'.format(
item['juan_name'],
item['zh_num'],
item['zh_name']
) f = open(filename,'w')
f.write(item['zh_content'])
f.close() return item
Scrapy - 小说爬虫的更多相关文章
- 使用scrapy制作的小说爬虫
使用scrapy制作的小说爬虫 爬虫配套的django网站 https://www.zybuluo.com/xuemy268/note/63660 首先是安装scrapy,在Windows下的安装比 ...
- 爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫 通过Scrapy,我们可以轻松地完成一个站点爬虫的编写.但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码. 如果我们将各个站点的 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- C#最基本的小说爬虫
新手学习C#,自己折腾弄了个简单的小说爬虫,实现了把小说内容爬下来写入txt,还只能爬指定网站. 第一次搞爬虫,涉及到了网络协议,正则表达式,弄得手忙脚乱跑起来效率还差劲,慢慢改吧. 爬的目标:htt ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- Scrapy创建爬虫项目
1.打开cmd命令行工具,输入scrapy startproject 项目名称 2.使用pycharm打开项目,查看项目目录 3.创建爬虫,打开CMD,cd命令进入到爬虫项目文件夹,输入scrapy ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
随机推荐
- Image Processing and Analysis_15_Image Registration: A Method for Registration of 3-D shapes——1992
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- c# 引用类型和值类型的内存分配
- Python使用selenium模拟点击(二)
本篇文章是接着第一篇文章讲的 具体可看第一篇:https://www.cnblogs.com/whatarey/p/10477754.html 要实现功能>搜索完毕,自动点击 这个功能做的停操蛋 ...
- C语言Makefile文件制作
本文摘抄自“跟我一起写Makefile ”,只是原文中我自己感觉比较精要的一部分,并且只针对C语言,使用GCC编译器. 原文请看这里:http://wiki.ubuntu.org.cn/%E8%B7% ...
- python3 准备
一.前言 1.Python是著名的“龟叔”Guido van Rossum发明的 2.python分为python2和python3两大版本,python2渐渐被淘汰,建议使用python3 3.py ...
- 01-docker简介及安装
什么是dockerdocker是一个开源项目,诞生于2013年初,最初是dotCloud公司内部的一个业余项目,它基于google公司推出的go语言实现.项目后来加入了linux基金会,遵从了apac ...
- 新安装的Ubuntu如何切换到root的方法
Ubuntu中root用户和user用户的相互切换Ubuntu是最近很流行的一款Linux系统,因为Ubuntu默认是不启动root用户,现在介绍如何进入root的方法. (1)从user用户切 ...
- 项目:JS实现简易计算器案例
组件化网页开发下的: 步骤一:让页面动起来的JavaScript深入讲解 的 项目:JS实现简易计算器案例
- Ubuntu16安装fabric1.4.4环境
安装流程依照官网地址 https://hyperledger-fabric.readthedocs.io/en/release-1.4/build_network.html 如果需要安装最新的版本,可 ...
- 001_C#我的第一个串口上位机软件
(一)首先感谢杜洋工作室 < 入门 C#设计 >带来的视频教学 (二)本次设计从会单片机但是又不会上位机又想搞简单上位机的人群角度提供教程 (三)本次教程的目的是制作普通的串口软件,从而实 ...