在Ubuntu上安装hadoop-2.7.7
1.安装open-vm-tools
sudo apt-get install open-vm-tools


2.安装openjdk
sudo apt-get install openjdk-8-jdk

3.安装配置ssh
apt-get install openssh-server
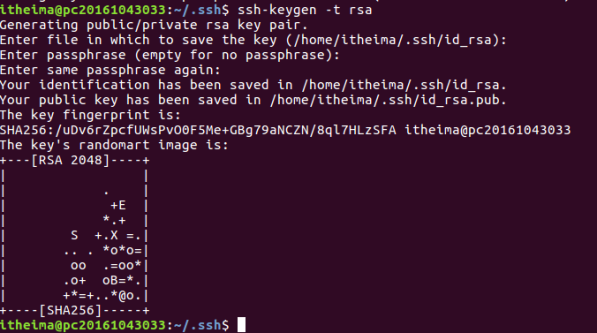
4.在进行了初次登陆后,会在当前家目录用户下有一个.ssh文件夹,进入该文件夹下:cd .ssh
ssh-keygen -t rsa
一路回车c

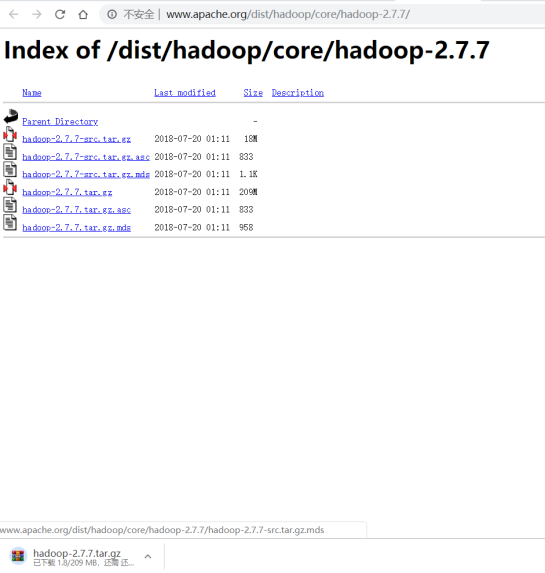
5.下载hadoop2.7.7 解压缩并改名为hadoop目录,放到/usr/local下(注意权限)
sudo mv ~/hadoop-2.7.7 /usr/local/hadoop



6.修改目录所有者 /usr/local/下的hadoop文件夹
sudo chown -R 当前用户名 /usr/local/hadoop

7.设置环境变量
(1)进入 sudo gedit ~/.bashrc
#~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
#打包hadoop程序需要的环境变量
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
#让环境变量生效
source ~/.bashrc
(2) 进入 /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
(3) 进入 /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(4) 进入 /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
(5) 进入 /usr/local/hadoop/etc/hadoop/mapred-site.xml(mapred-site.xml.template重命名)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(6) 进入 /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

8.格式化hdfs文件系统
hdfs namenode -format

9.启动hadoop
start-all.sh 或start-dfs.sh start-yarn.sh

10.浏览器搜索
在Ubuntu上安装hadoop-2.7.7的更多相关文章
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- 在Ubuntu上安装Hadoop(单机模式)步骤
1. 安装jdk:sudo apt-get install openjdk-6-jdk 2. 配置ssh:安装ssh:apt-get install openssh-server 为运行hadoop的 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- Ubuntu 12.04上安装Hadoop并运行
Ubuntu 12.04上安装Hadoop并运行 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 在官网上下载好四个文件 在Ubuntu的/home/w ...
- 在Linux上安装Hadoop
先决条件: Hadoop是用JAVA写的,所以首先要安装Java.在Ubuntu上安装JDK见:http://blog.csdn.net/microfhu/article/details/766739 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
[转自:]http://blog.csdn.net/hitwengqi/article/details/8008203 最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文. 首先要了 ...
- [异常解决] ubuntu上安装JLink驱动遇到的坑及给后来者的建议
一.前言 最近将整个电脑格式化,改成了linux操作系统 希望这样能让自己在一个新的世界探索技术.提升自己吧- win上的工具用多了,就不想变化了- 继上一篇<ubuntu上安装虚拟机遇到的问题 ...
- Ubuntu上安装Robomongo及添加到启动器
到目前为止,Robomongo仍是MongoDB最好的客户端管理工具,如需在Ubuntu上安装Robomongo,可直接从官网下载.tar.gz压缩包进行解压,然后直接运行bin目录下的robomon ...
- 在 Ubuntu 上安装 Android Studio
在 Ubuntu 上安装 Android Studio http://www.linuxidc.com/Linux/2013-05/84812.htm 打开terminal,输入以下命令 sudo a ...
随机推荐
- golang——写文件和读文件
之前聊过,操作文件——读写文件,直接调用接口即可. 如果是一直写入操作,写入操作一直进行的,免不了会有,有时一大批数据过来,有时没有一条数据. 鉴于此场景,选择用select....channel 的 ...
- ansiblle---roles
使用ansible中的roles来管理主机. 剧本中的roles你现在已经学过 tasks 和 handlers,那怎样组织 playbook 才是最好的方式呢?简单的回答就是:使用 roles ! ...
- CPU排行-台式
此文已经于2017年11月1日更新!来源于极速空间 实际对比: intel i3-7100(双核四线程) CPU性能远超过 AMD X4 860K(四核四线程) intel i5-7500(四核四线程 ...
- LC 969. Pancake Sorting
Given an array A, we can perform a pancake flip: We choose some positive integer k <= A.length, t ...
- 人才-T型人才:百科
ylbtech-人才-T型人才:百科 T型人才是指按知识结构区分出来的一种新型人才类型.用字母“T”来表示他们的知识结构特点.“—”表示有广博的知识面,“|”表示知识的深度.两者的结合,既有较深的专业 ...
- CSS三角形的实现原理及运用
原理 css盒模型 一个盒子包括: margin+border+padding+content– 上下左右边框交界处出呈现平滑的斜线. 利用这个特点, 通过设置不同的上下左右边框宽度或者颜色可以得到小 ...
- mock的使用
mock的重要性 mock就是对于某些不容易构造或者不容易获取的对象,用一个虚拟的对象来创建的方法.项目开发和测试过程中,遇到以下的情况时,就需要模拟结果返回. 1.当另一方接口或服务还未完成,阻碍项 ...
- kafka整合springboot
1.pom.xml添加依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifa ...
- 监控web80端口
判断本机的80端口是否开启着,如果开启着什么都不做,如果发现端口不存在,那么重启一下httpd服务,并发邮件通知你自己. #! /bin/bashmail=123@123.comif netstat ...
- Docker监控:最佳实践以及cAdvisor和Prometheus监控工具的对比
在DockerCon EU 2015上,Brian Christner阐述了“Docker监控”的概况,分享了这方面的最佳实践和Docker stats API的指南,并对比了三个流行的监控方案:cA ...