01-Hadoop概述及基础环境搭建
1 hadoop概述
1.1 为什么会有大数据处理
- 传统数据库:存储亿级别的数据,需要高性能的服务器;并且解决不了本质问题;只能存结构化数据
- 大数据存储:通过分布式存储,将数据存到一台机器的同时,还可以备份到其他机器上,这样当某台机器挂掉了或磁盘坏掉了,在其他机器上可以拿到该数据,数据不会丢失(可备份)
- 磁盘不够挂磁盘,机器不够加机器(可横行扩展)
- 传统数据库: 当数据库存储亿级别的数据后,查询效率也下降的很快,查询不能秒级返回
- 大数据分析:分布式计算。也可以横行扩展

1.2 什么是hadoop?
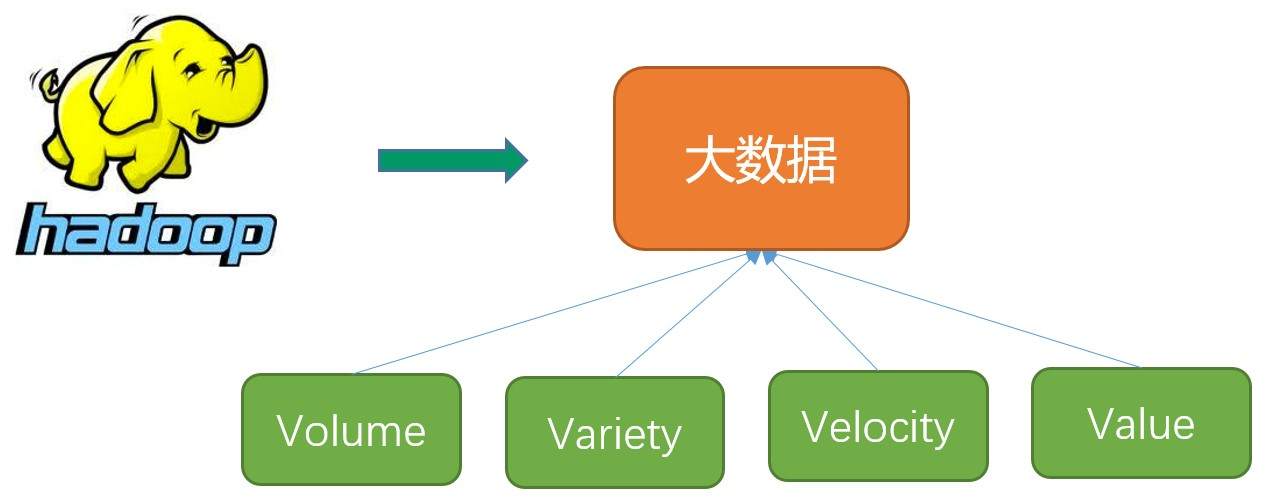
- 数据容量大(Volume)。从TB级别,跃升到PB级别
- 数据类型繁多(Variety)。包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求
- 商业价值高(Value)。客户群体细分,提供定制化服务;发掘新的需求同时提高投资的回报率;降低服务成本
- 处理速度快(Velocity)。这是大数据区分于传统数据挖掘的最显著特征。预计到2020年,全球数据使用量将达到35.2ZB。在如此海量的数据面前,处理数据的效率就是企业的生命

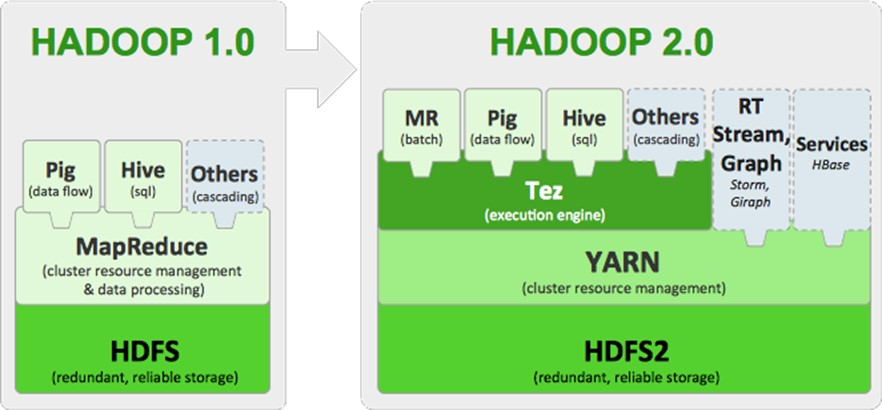
Hadoop1.0 的 MapReduce(MR1):集资源管理和任务调用、计算功能绑在一起,扩展性较差,不支持多计算框架
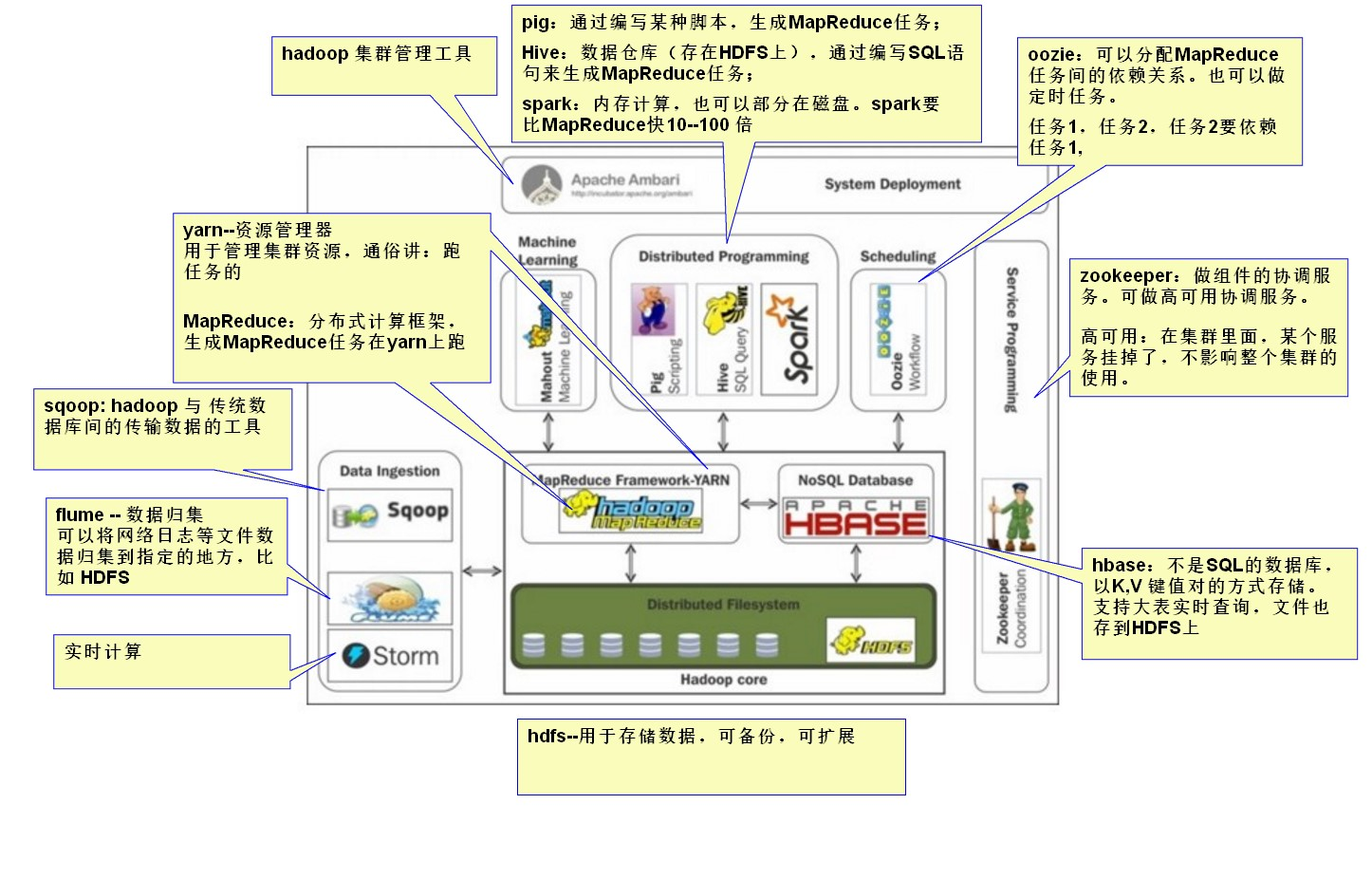

2 基础环境搭建
// 查看网卡配置文件是否一致
vim /etc/sysconfig/network-scripts/ifcfg-ens33
// 文件配置如下:
TYPE="Ethernet"
BOOTPROTO=static
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
NAME="eno16777736"
UUID="cb7a79a9-8114-482b-93f0-fce73bcef88b"
DEVICE="eno16777736"
ONBOOT="yes"
IPADDR=192.168.142.200
PREFIX=24
GATEWAY=192.168.142.2
DNS1=192.168.142.2
DNS2=8.8.8.8 // 重启网络
systemctl restart network.service 或 service network restart
// ping 百度,测试网络是否正常
ping www.baidu.com
2.1 配置阿里云 yum 源
yum install -y lrzsz
mv Centos-7.repo /etc/yum.repos.d/
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.bak
mv Centos-7.repo CentOS-Base.repo
yum clean all
# 服务器的包信息下载到本地电脑缓存起来
yum makecache
yum update -y
配置完毕。
2.2 安装常用软件
yum install -y openssh-server vim gcc gcc-c++ glibc-headers bzip2-devel lzo-devel curl wget openssh-clients zlib-devel autoconf automake cmake libtool openssl-devel fuse-devel snappy-devel telnet unzip zip net-tools.x86_64 firewalld systemd
2.3 关闭防火墙
2.4 关闭SELinux

2.5 安装JDK
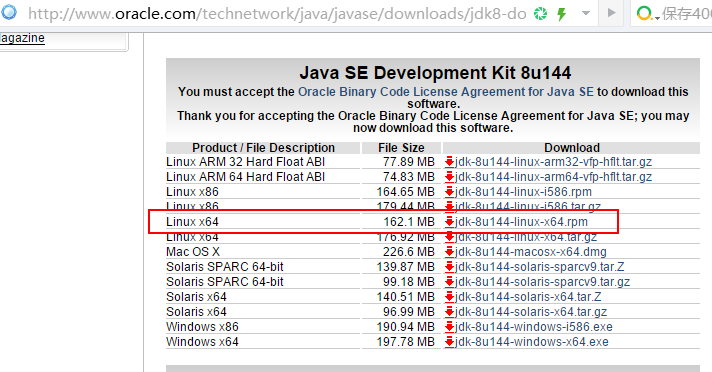
export JAVA_HOME=/usr/java/jdk1.8.0_144
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar


#使修改生效
source /etc/profile
#查看系统变量值
env | grep PATH
#检查JDK 配置情况
env | grep JAVA_HOME
2.6 修改主安装常用软件主机名
hostnamectl set-hostname nn1.hadoop
#修改完后用hostname可查看当前主机名
hostname
2.7 创建hadoop 用户并设置 hadoop 用户密码
#创建hadoop用户
useradd hadoop
#给hadoop用户设置密码
hadoop000
2.8 给hadoop用户,配置SSH密钥

#切换到hadoop用户
su – hadoop
#创建.ssh目录
mkdir ~/.ssh
#生成ssh公私钥
ssh-keygen -t rsa -f ~/.ssh/id_rsa -P ''
#输出公钥文件内容并且重新输入到~/.ssh/authorized_keys文件中
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
#给~/.ssh文件加上700权限
chmod 700 ~/.ssh
#给~/.ssh/authorized_keys加上600权限
chmod 600 ~/.ssh/authorized_keys
2.9 禁止非 whell 组用户切换到root,配置免密切换root
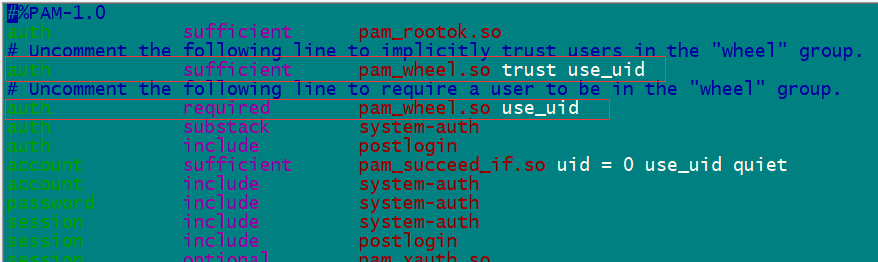
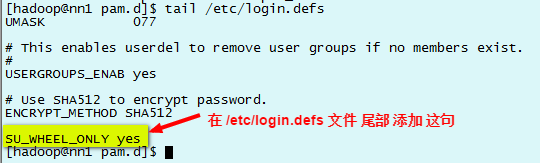
#把hadoop用户加到wheel组里
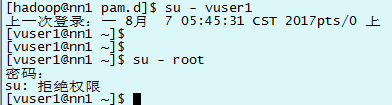
[root@nn1 ~]# gpasswd -a hadoop wheel
#查看wheel组里是否有hadoop用户
[root@nn1 ~]# cat /etc/group | grep wheel

2.10 配置hosts 文件
在克隆机器前,配置nn1 机器的 /etc/hosts 文件,文件内需要配置nn1、nn2、s1、s2、s3 所有机器的IP 和 主机名。
192.168.174.160 nn1.hadoop
192.168.174.161 nn2.hadoop
192.168.174.162 s1.hadoop
192.168.174.163 s2.hadoop
192.168.174.164 s3.hadoop
2.11 克隆4台机器
执行完上面的命令,一个基础的linux系统就配置好了。然后再根据这个虚拟机克隆出 4个linux系统
其中:nn2.hadoop: 从节点
s1.hadoop、s2.hadoop、s3.hadoop:三个工作节点
并用hadoop用户,测试彼此之间是否能进行ssh通信
右键 nn1 机器→ 管理 → 克隆。
克隆完成后,需要给克隆的虚拟机配置静态IP。
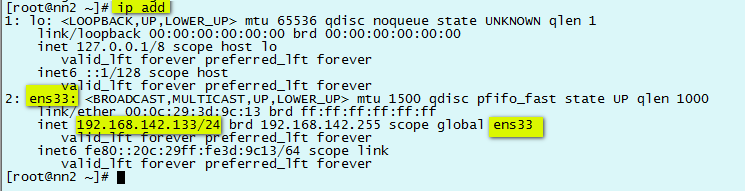
1)查看网卡硬件名称和基本信息 ip add
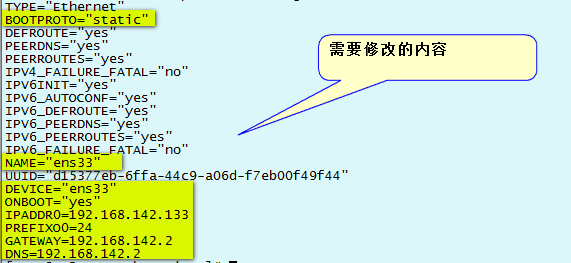
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
NAME="ens33"
UUID="d15377eb-6ffa-44c9-a06d-f7eb00f49f44"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.142.133
PREFIX=24
GATEWAY=192.168.142.2
DNS1=192.168.142.2
DNS2=8.8.8.8
hostnamectl set-hostname nn1.hadoop
#修改完后用hostname可查看当前主机名
hostname

// 停止NetworkManager服务
systemctl stop NetworkManager.service
// 并设置成开机不启动
systemctl disable NetworkManager.service
// 之后重启网络服务
systemctl restart network.service
hostnamectl set-hostname nn2.hadoop
hostnamectl set-hostname s1.hadoop
hostnamectl set-hostname s2.hadoop
hostnamectl set-hostname s3.hadoop
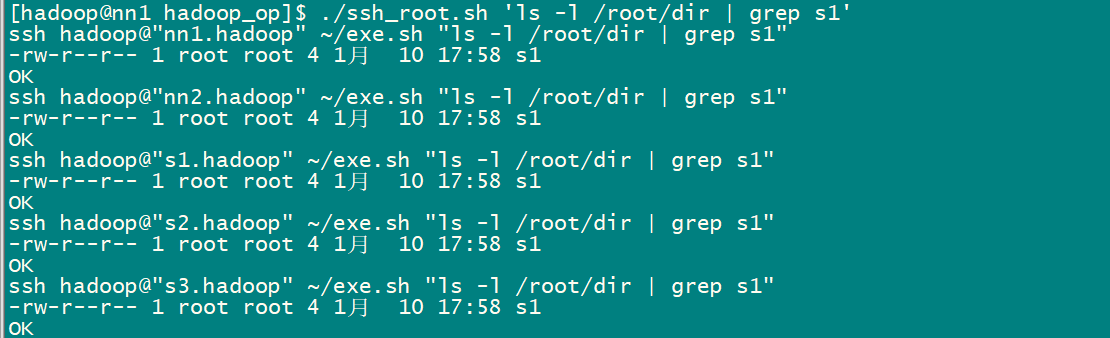
3 批量脚本说明及使用
3.1 批量脚本说明
chmod -R +x ~/hadoop_op

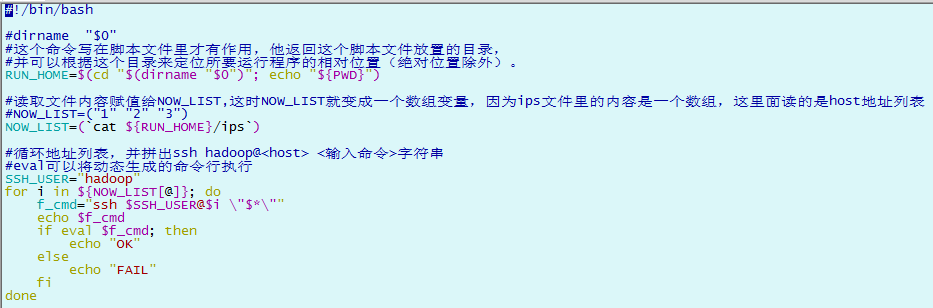
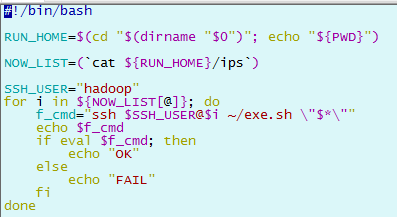

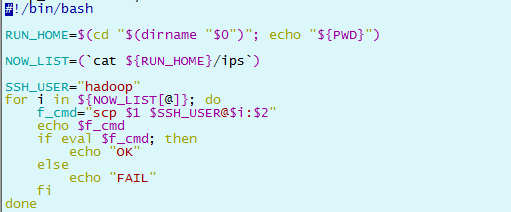
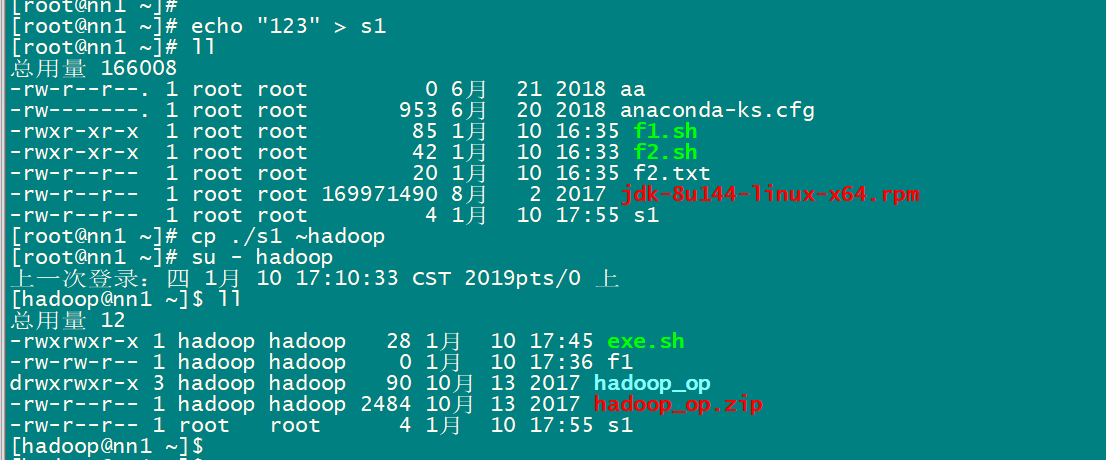
3.2 批量脚本的使用


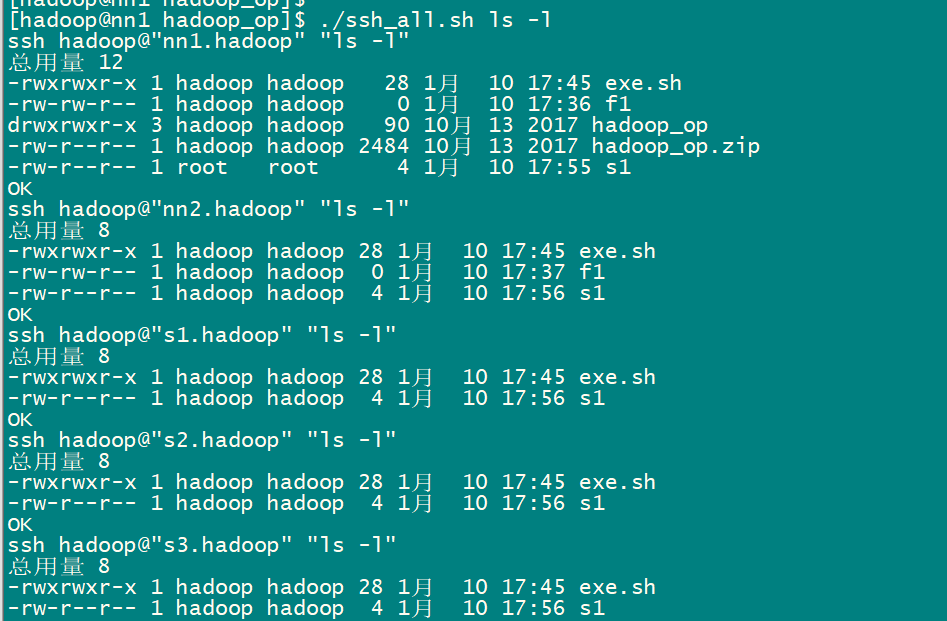
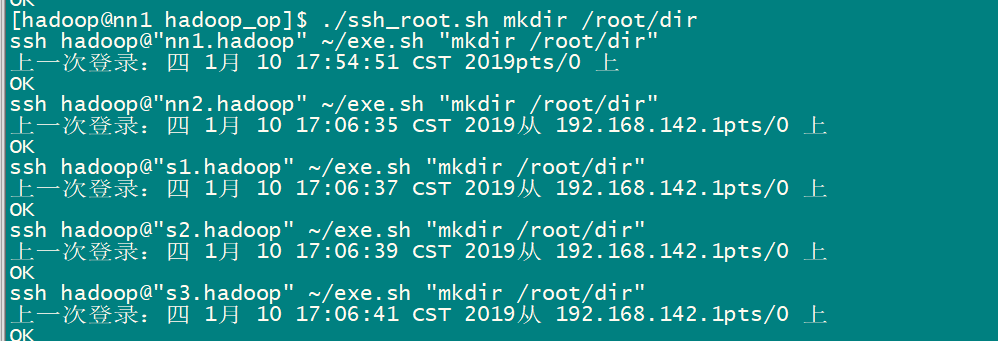
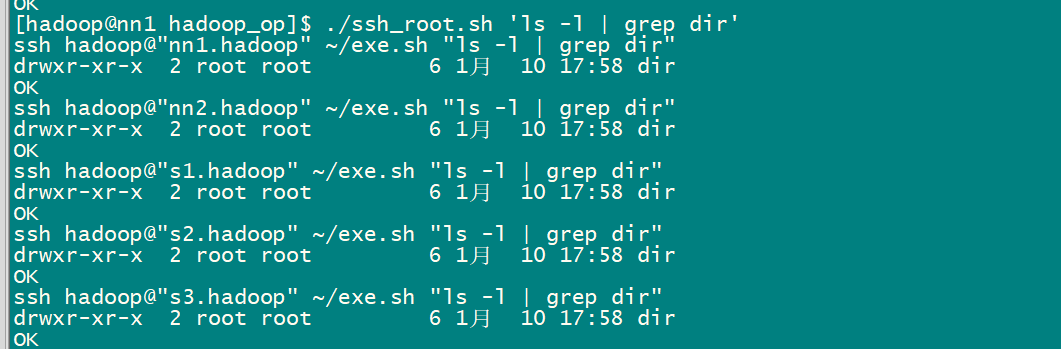
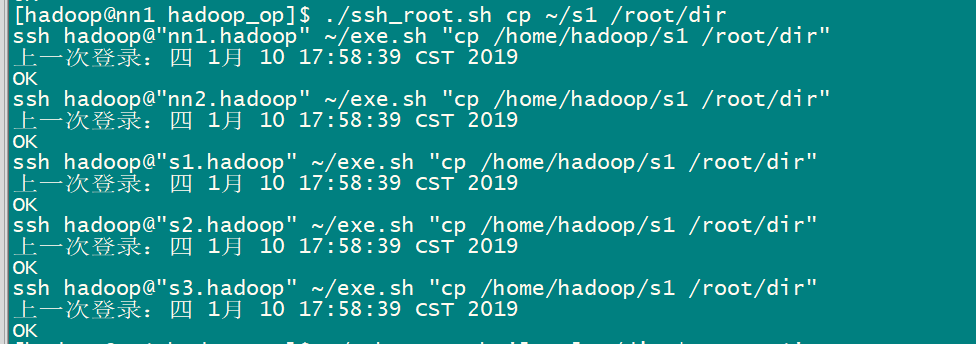
01-Hadoop概述及基础环境搭建的更多相关文章
- Hadoop学习之基础环境搭建
期望目的 基于VMware workstation 10.0 + CentOS 7 + hadoop 3.2.0,在虚拟机上搭建一套Hadoop集群环境,总共包含4个节点,其中1个master节点.3 ...
- 【Hadoop基础教程】1、Hadoop之服务器基础环境搭建(转)
本blog以K-Master服务器基础环境配置为例分别演示用户配置.sudo权限配置.网路配置.关闭防火墙.安装JDK工具等.用户需参照以下步骤完成KVMSlave1~KVMSlave3服务器的基础环 ...
- Hadoop window win10 基础环境搭建(2.8.1)
下面运行步骤除了配置文件有部分改动,其他都是参照hadoop下载解压的share/doc/index.html. hadoop下载:http://apache.opencas.org/hadoop/c ...
- Hadoop window win10 基础环境搭建(2.8.1)(转)
下面运行步骤除了配置文件有部分改动,其他都是参照hadoop下载解压的share/doc/index.html. hadoop下载:http://apache.opencas.org/hadoop/c ...
- 【Hadoop基础教程】4、Hadoop之完全分布式环境搭建
上一篇blog我们完成了Hadoop伪分布式环境的搭建,伪分布式模式也叫单节点集群模式, NameNode.SecondaryNameNode.DataNode.JobTracker.TaskTrac ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- [小北De编程手记] : Lesson 01 - Selenium For C# 之 环境搭建
在我看来一个自动化测试平台的构建,是一种很好的了解开发语言,单元测试框架,自动化测试驱动,设计模式等等等的途径.因此,在下选择了自动化测试的这个话题来和大家分享一下本人关于软件开发和自动化测试的认识. ...
- Spark环境搭建(上)——基础环境搭建
Spark摘说 Spark的环境搭建涉及三个部分,一是linux系统基础环境搭建,二是Hadoop集群安装,三是Spark集群安装.在这里,主要介绍Spark在Centos系统上的准备工作--linu ...
- hadoop3.1.0 window win7 基础环境搭建
https://blog.csdn.net/wsh596823919/article/details/80774805 hadoop3.1.0 window win7 基础环境搭建 前言:在windo ...
随机推荐
- jQuery系列(四):jQuery的属性操作
jquery的属性操作模块分为四个部分:html属性操作,dom属性操作,类样式操作和值操作 html属性操作:是对html文档中的属性进行读取,设置和移除操作.比如attr().removeAttr ...
- 顺序表应用1:多余元素删除之移位算法(SDUT 3324)
Problem Description 一个长度不超过10000数据的顺序表,可能存在着一些值相同的"多余"数据元素(类型为整型),编写一个程序将"多余"的数据 ...
- LoadLibrary(C:\soft\IDA 7.0\IDA 7.0\plugins\python64.dll) error: 找不到指定的模块。 C:\soft\IDA 7.0\IDA 7.0\plugins\python64.dll: can't load file LoadLibrary(C:\soft\IDA 7.0\IDA 7.0\plugins\python64.dll) erro
LoadLibrary(C:\soft\IDA 7.0\IDA 7.0\plugins\python64.dll) error: 找不到指定的模块. C:\soft\IDA 7.0\IDA 7.0\p ...
- node和npm版本引起的安装依赖和运行项目失败问题
问题:node版本不同导致的安装依赖版本不同而无法启动 https://www.jianshu.com/p/c07293c8c6d4 实际上问题分为两个部分: 1,npm包管理器安装依赖不成功,此时需 ...
- Visual Studio Code(VS code)介绍
一.日常安利 VS code VS vode特点: 开源,免费: 自定义配置 集成git 智能提示强大 支持各种文件格式(html/jade/css/less/sass/xml) 调试功能强大 各种方 ...
- .net 数据导出
安装npoi,下面是具体的C#代码: public static XSSFWorkbook BuildWorkbook(DataTable dt) { var book = new XSSFWorkb ...
- redis的哨兵
删除旧master或者不可达slave sentinel永远会记录好一个Master的slaves,即使slave已经与组织失联好久了.这是很有用的,因为sentinel集群必须有能力把一个恢复可用的 ...
- Windows Server 2012R2 部署 Domain Controller
1. Create a machine as Domain Controller; 2. Change DNS server address as 127.0.0.1; 3. Change Compu ...
- polya定理,环形涂色
环形涂色裸题 #include<iostream> #include<cstdio> #include<algorithm> #include<vector& ...
- linux下如何基于已有容器创建image并运行?
1. 通过docker ps命令先找到容器id,示例如下,123456789012就是我们要找的 jello@~$ docker ps CONTAINER ID IMAGE COMMAND CREAT ...