spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html
一、大数据性能调优的本质
编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论做什么类型的编程,最终思考的都是硬件方面的问题!最终思考都是在一秒、一毫秒、甚至一纳秒到底是如何运行的,并且基于此进行算法实现和性能调优,最后都是回到了硬件!
在大数据性能的调优,它的本质是硬件的调优!即基于 CPU(计算)、Memory(存储)、IO-Disk/ Network(数据交互) 基础上构建算法和性能调优!我们在计算的时候,数据肯定是存储在内存中的。磁盘IO怎么去处理和网络IO怎么去优化。
二、spark性能调优要点分析
在大数据性能本质的思路上,我们应该需要在那些方面进行调优呢?比如:
1、并行度
2、压缩
3、序列化
4、数据倾斜
5、JVM调优 (例如 JVM 数据结构化优化)
6、内存调优
7、Task性能调优 (例如包含 Mapper 和 Reducer 两种类型的 Task)
8、shuffle网络调优(例如小文件合并)
9、RDD算子调优(例如RDD复用,自定义RDD)
10、数据本地性
11、容错调优
12、参数调优
大数据最怕的就是数据本地性(内存中)和数据倾斜或者叫数据分布不均衡、数据转输,这个是所有分布式系统的问题!数据倾斜其实是跟你的业务紧密相关的。所以调优 Spark 的重点一定是在数据本地性和数据倾斜入手。
1、资源分配和使用:你能够申请多少资源以及如何最优化的使用计算资源
2、关发调优:如何基于 Spark 框架内核原理和运行机制最优化的实现代码功能
3、Shuffle调优:分布式系统必然面临的杀手级别的问题
4、数据倾斜:分布式系统业务本身有数据倾斜
三、spark资源使用原理流程
这是一张来至于官方的经典资源使用流程图,这里有三大组件,第一部份是 Driver 部份,第二就是具体处理数据的部份,第三就是资源管理部份。这一张图中间有一个过程,这表示在程序运行之前向资源管理器申请资源。在实际生产环境中,Cluster Manager 一般都是 Yarn 的 ResourceManager,Driver 会向 ResourceManager 申请计算资源(一般情况下都是在发生计算之前一次性进行申请请求),分配的计算资源就是 CPU Core 和 Memory,我们具体的 Job 里的 Task 就是基于这些分配的内存和 Cores 构建的线程池来运行 Tasks 的。
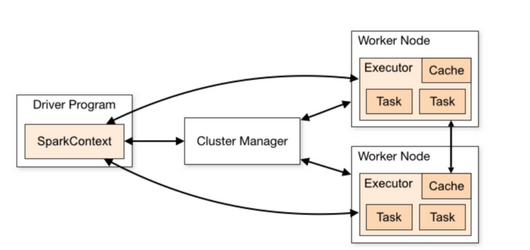
当然在 Task 运行的过程中会大量的消耗内存,而Task又分为 Mapper 和 Reducer 两种不同类型的 Task,也就是 ShuffleMapTask 和 ResultTask 两种类型,这类有一个很关建的调优点就是如何对内存进行使用。在一个 Task 运行的时候,默应会占用 Executor 总内存的 20%,Shuffle 拉取数据和进行聚合操作等占用了 20% 的内存,剩下的大概有 60% 是用于 RDD 持久化 (例如 cache 数据到内存),Task 在运行时候是跑在 Core 上的,比较理想的是有足够的 Core 同时数据分布比较均匀,这个时候往往能够充分利用集群的资源。
核心参数调优如下:
num-executors
executor-memory
executor-cores
driver-memory
spark.default.parallelizm
spark.storage.memoryFraction
spark.shuffle.memoryFraction
- num-executors:该参数一定会被设置,Yarn 会按照 Driver 的申请去最终为当前的 Application 生产指定个数的 Executors,实际生产环境下应该分配80个左右 Executors 会比较合适呢。
- executor-memory:这个定义了每个 Executor 的内存,它与 JVM OOM 紧密相关,很多时候甚至决定了 Spark 运行的性能。实际生产环境下建义是 8G 左右,很多时候 Spark 运行在 Yarn 上,内存占用量不要超过 Yarn 的内存资源的 50%。
- executor-cores:决定了在 Executors 中能够并行执行的 Tasks 的个数。实际生产环境下应该分配4个左右,一般情况下不要超过 Yarn 队列中 Cores 总数量的 50%。
- driver-memory:默应是 1G
- spark.default.parallelizm:并行度问题,如果不设置这个参数,Spark 会跟据 HDFS 中 Block 的个数去设置这一个数量,原理是默应每个 Block 会对应一个 Task,默应情况下,如果数据量不是太多就不可以充份利用 executor 设置的资源,就会浪费了资源。建义设置为 100个,最好 700个左右。Spark官方的建义是每一个 Core 负责 2-3 个 Task。
- spark.storage.memoryFraction:默应占用 60%,如果计算比较依赖于历史数据则可以调高该参数,当如果计算比较依赖 Shuffle 的话则需要降低该比例。
- spark.shuffle.memoryFraction:默应占用 20%,如果计算比较依赖 Shuffle 的话则需要调高该比例。
四、spark更高性能的算子
Shuffle 分开两部份,一个是 Mapper 端的Shuffle,另外一个就是 Reducer端的 Shuffle,性能调优有一个很重要的总结就是尽量不使用 Shuffle 类的算子,我们能避免就尽量避免,因为一般进行 Shuffle 的时候,它会把集群中多个节点上的同一个 Key 汇聚在同一个节点上,例如 reduceByKey。然后会优先把结果数据放在内存中,但如果内存不够的话会放到磁盘上。Shuffle 在进行数据抓取之前,为了整个集群的稳定性,它的 Mapper 端会把数据写到本地文件系统。这可能会导致大量磁盘文件的操作。如何避免Shuffle可以考虑以下:
- 采用 Map 端的 Join (RDD1 + RDD2 )先把一个 RDD1的数据收集过来,然后再通过 sc.broadcast( ) 把数据广播到 Executor 上;
- 如果无法避免Shuffle,退而求其次就是需要更多的机器参与 Shuffle 的过程,这个时候就需要充份地利用 Mapper 端和 Reducer 端机制的计算资源,尽量使用 Mapper 端的 Aggregrate 功能,e.g. aggregrateByKey 操作。相对于 groupByKey而言,更倾向于使用 reduceByKey( ) 和 aggregrateByKey( ) 来取代 groupByKey,因为 groupByKey 不会进行 Mapper 端的操作,aggregrateByKey 可以给予更多的控制。
- 如果一批一批地处理数据来说,可以使用 mapPartitions( ),但这个算子有可能会出现 OOM 机会,它会进行 JVM 的 GC 操作!
- 如果进行批量插入数据到数据库的话,建义采用foreachPartition( ) 。
- 因为我们不希望有太多的数据碎片,所以能批量处理就尽量批量处理,你可以调用 coalesce( ) ,把一个更多的并行度的分片变得更少,假设有一万个数据分片,想把它变得一百个,就可以使用 coalesce( )方法,一般在 filter( ) 算子之后就会用 coalesce( ),这样可以节省资源。
- 官方建义使用 repartitionAndSortWithPartitions( );
- 数据进行复用时一般都会进行持久化 persisit( );
- 建义使用 mapPartitionWithIndex( );
- 也建义使用 tree 开头的算子,比如说 treeReduce( ) 和 treeAggregrate( );
总结
大数据必然要思考的核心性能问题不外乎 CPU 计算、内存管理、磁盘和网络IO操作,这是无可避免的,但是可以基于这个基础上进行优化,思考如何最优化的使用计算资源,思考如何在优化代码,在代码层面上防避坠入性能弱点;思考如何减少网络传输和思考如何最大程度的实现数据分布均衡。
在资源管理调优方面可以设置一些参数,比如num-executors、executor-memory、executor-cores、driver-memory、spark.default.parallelizm、spark.storage.memoryFraction、spark.shuffle.memoryFraction
Shuffle 所导致的问题是所有分布式系统都无法避免的,但是如何把 Shuffle 所带来的性能问题减少最低,是一个很可靠的优化方向。Shuffle 的第一阶段即Mapper端在默应情况下会写到本地,而reducer通过网络抓取的同一个 Key 在不同节点上都把它抓取过来,内存可能不够,不够的话就写到磁盘中,这可能会导致大量磁盘文件的操作。在实际编程的时候,可以用一些比较高效的RDD算子,例如 reduceByKey、aggregrateByKey、coalesce、foreachPartition、repartitionAndSortWithPartitions。
spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析的更多相关文章
- Spark数据本地化-->如何达到性能调优的目的
Spark数据本地化-->如何达到性能调优的目的 1.Spark数据的本地化:移动计算,而不是移动数据 2.Spark中的数据本地化级别: TaskSetManager 的 Locality L ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- Spark调优_性能调优(一)
总结一下spark的调优方案--性能调优: 一.调节并行度 1.性能上的调优主要注重一下几点: Excutor的数量 每个Excutor所分配的CPU的数量 每个Excutor所能分配的内存量 Dri ...
- Spark(十二)--性能调优篇
一段程序只能完成功能是没有用的,只能能够稳定.高效率地运行才是生成环境所需要的. 本篇记录了Spark各个角度的调优技巧,以备不时之需. 一.配置参数的方式和观察性能的方式 额...从最基本的开始讲, ...
- 性能调优的本质、Spark资源使用原理和调优要点分析
本课主题 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- Spark调优,性能优化
Spark调优,性能优化 1.使用reduceByKey/aggregateByKey替代groupByKey 2.使用mapPartitions替代普通map 3.使用foreachPartitio ...
- 二十种实战调优MySQL性能优化的经验
二十种实战调优MySQL性能优化的经验 发布时间:2012 年 2 月 15 日 发布者: OurMySQL 来源:web大本营 才被阅读:3,354 次 消灭0评论 本文将为大家介 ...
- Mysql数据库调优和性能优化的21条最佳实践
Mysql数据库调优和性能优化的21条最佳实践 1. 简介 在Web应用程序体系架构中,数据持久层(通常是一个关系数据库)是关键的核心部分,它对系统的性能有非常重要的影响.MySQL是目前使用最多的开 ...
- Java生鲜电商平台-API请求性能调优与性能监控
Java生鲜电商平台-API请求性能调优与性能监控 背景 在做性能分析时,API的执行时间是一个显著的指标,这里使用SpringBoot AOP的方式,通过对接口添加简单注解的方式来打印API的执行时 ...
随机推荐
- 企业服务总线ESB
# 企业服务总线ESB 由中间件技术实现并支持SOA的一组基础架构,支持异构环境中的服务.消息以及基于事件的交互,并且具有适当的服务级别和可管理性. 通过使用ESB,可以在几乎不更改代码的情况下,以一 ...
- 利用Elasticsearch搭建全球域名解析记录
前言 数据来源,由Rapid7收集并提供下载https://scans.io/study/sonar.fdns 下载Elasticsearch 2.3 ElasticSearch是一个基于Lucene ...
- 团队项目开题Scrum Meeting报告
团队项目开题Scrum Meeting报告 在10月30号星期四的晚上我们团队找到了给我们代码的王翊学长,由学长给我们讲解了他编写IOS平台上北航MOOC系统的架构和思路, 因为我们团队没有苹果公司的 ...
- sampleFactory(女娲造人)
使用简单工厂模式模拟女娲(Nvwa)造人(Person),如果传入参数M,则返回一个Man对象,如果传入参数W,则返回一个Woman对象,如果传入参数R,则返回一个Robot对象. package c ...
- oracle 分页的sql语句
已知有两种方法效率上貌似第一种更优: 1. select * from( select t1.*, rownum n from (select * from cm_log order by oper_ ...
- ubuntu16.04+matlab r2015b VideoReader报错
读取.mp4出错 需要安装gstreamer0.10-ffmpeg ` sudo add-apt-repository ppa:mc3man/gstffmpeg-keep sudo apt-get u ...
- asp.net文件上传接收不到文件 Request.files["']等于null
这个时候你应该检查下你的form表单里面是否配置了这个: enctype ="multipart/form-data" 新手容易出错哦. <form id="fo ...
- bootstrap使用总结
bootstrap是一个webcss框架,集合了html/css/jquery为一家,创建响应式的页面.所谓的响应式就是适配不同的上网设备. 使用bootstrap的步骤: 1.下载bootstrap ...
- H5页面的滚动条在windows浏览器下始终看到(灰色的不可用的)
一般这种情况是在某些相关的div上设置了overflow:scroll属性,在mac系统的浏览器下均没有滚动条显示而在windows下的各个浏览器上均可以看到灰色的不可用的滚动条,这种情况我们需要在b ...
- Mac OS10.10 openfire无法启动问题
1.我用的Java版本是Version 8 Update 51,验证方法可到这个网址下去验证http://www.java.com/zh_CN/download/installed.jsp 2.ope ...