回归模型效果评估系列3-R平方
决定系数(coefficient of determination,R2)是反映模型拟合优度的重要的统计量,为回归平方和与总平方和之比。R2取值在0到1之间,且无单位,其数值大小反映了回归贡献的相对程度,即在因变量Y的总变异中回归关系所能解释的百分比。 R2是最常用于评价回归模型优劣程度的指标,R2越大(接近于1),所拟合的回归方程越优。
假设一数据集包括y1,...,yn共n个观察值,相对应的模型预测值分别为f1,...,fn。定义残差ei = yi − fi,平均观察值为
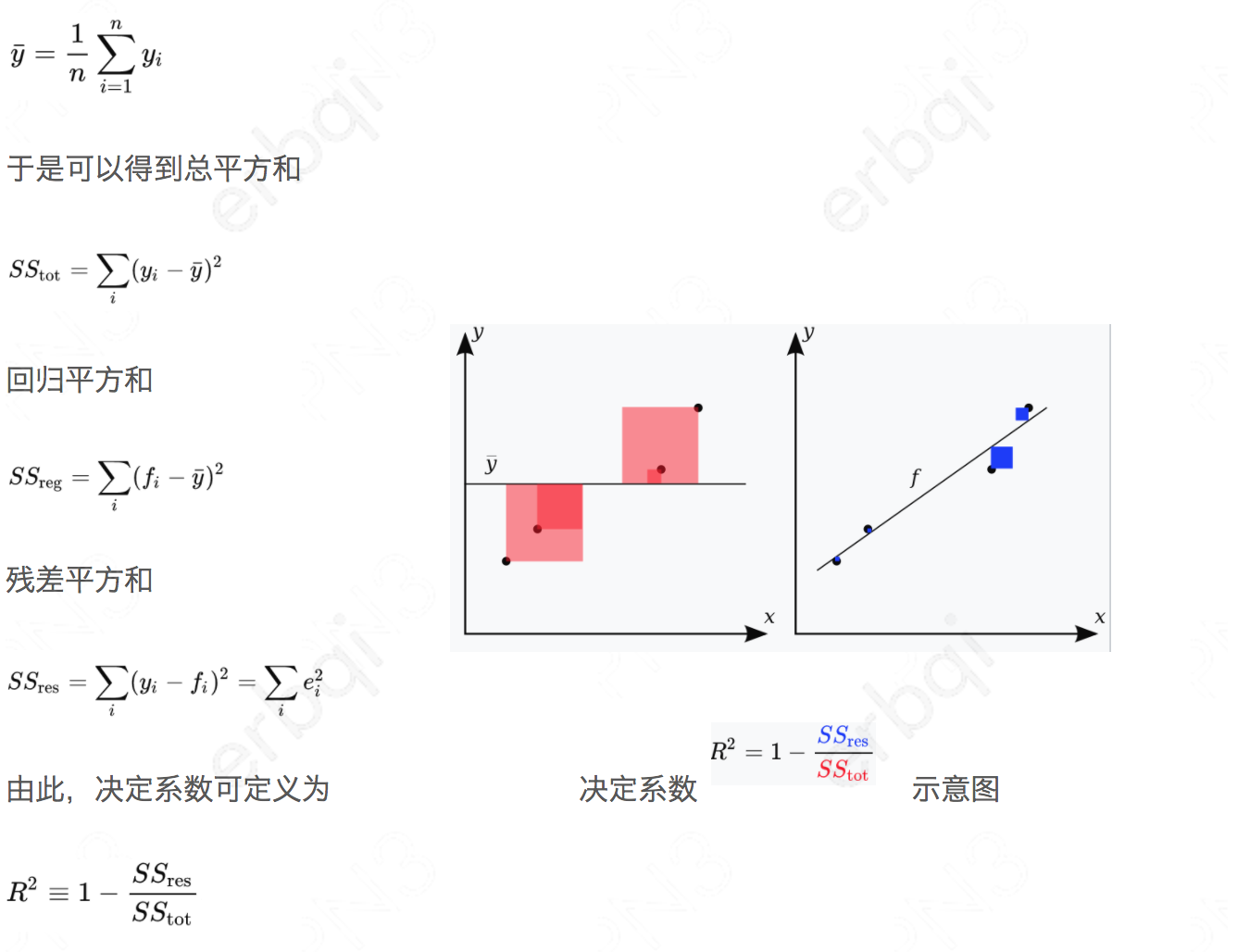
虽然R2可以用来评价回归方程的优劣,但随着自变量个数的增加,R2将不断增大(因为自变量个数的增加,意味着模型的复杂度升高,对样本数据的拟合程度会提高)。
若对两个具有不同个数自变量的回归方程进行比较时,不能简单地用R2作为评价回归方程的标准,还必须考虑方程所包含的自变量个数的影响,此时可用校正的决定系数(R2-adjusted)

其中n是样本数量,p是模型中变量的个数,当变量个数为0时,修正和原始的R方是一样的
就是相当于给变量的个数加惩罚项。换句话说,如果两个模型,样本数一样,R2一样,那么从修正R2的角度看,使用变量个数少的那个模型更优。
至于R2大于多少才有意义呢?这时我们可以看另外一个指标:复相关系数(Multiple correlation coefficient)R,R是决定系数R2的平方根,可用来度量因变量Y与多个自变量间的线性相关程度,即观察值Y与估计值之间的相关程度。
相关系数要在0.7~0.5才有意义,因此,R2应大于0.5*0.5=0.25,所以有种观点认为,在直线回归中应R2大于0.3才有意义。
还是来看下一个简单的例子,看下简单的平滑预测的R平方有多少

import numpy as np def r_square(y,f):
y,f = np.array(y),np.array(f)
y_mean = y.mean()
SStot = sum(np.power((y-y_mean),2))
SSres = sum(np.power(y-f,2))
return 1.0 - 1.0*SSres/SStot def smooth_(squences,period=5):
res = []
gap = period/2
right = len(squences)
for i in range(right):
res.append(np.mean(squences[i-gap if i-gap > 0 else 0:i+gap if i+gap < right else right]))
return res httpspeedavg = np.array([1821000, 2264000, 2209000, 2203000, 2306000, 2005000, 2428000,
2246000, 1642000, 721000, 1125000, 1335000, 1367000, 1760000,
1807000, 1761000, 1767000, 1723000, 1883000, 1645000, 1548000,
1608000, 1372000, 1532000, 1485000, 1527000, 1618000, 1640000,
1199000, 1627000, 1620000, 1770000, 1741000, 1744000, 1986000,
1931000, 2410000, 2293000, 2199000, 1982000, 2036000, 2462000,
2246000, 2071000, 2220000, 2062000, 1741000, 1624000, 1872000,
1621000, 1426000, 1723000, 1735000, 1443000, 1735000, 2053000,
1811000, 1958000, 1828000, 1763000, 2185000, 2267000, 2134000,
2253000, 1719000, 1669000, 1973000, 1615000, 1839000, 1957000,
1809000, 1799000, 1706000, 1549000, 1546000, 1692000, 2335000,
2611000, 1855000, 2092000, 2029000, 1695000, 1379000, 2400000,
2522000, 2140000, 2614000, 2399000, 2376000])
httpavg = np.round((1.0*httpspeedavg/1024/1024).tolist(),2)
smooth = np.round(smooth_((1.0*httpspeedavg/1024/1024).tolist(),5),2) print r_square(httpavg,smooth)
# 0.711750424322
也就是71%的网络变化情况可以用平滑预测来解释
回归模型效果评估系列3-R平方的更多相关文章
- 回归模型效果评估系列1-QQ图
(erbqi)导语 QQ图全称 Quantile-Quantile图,也就是分位数-分位数图,简单理解就是把两个分布相同分位数的值,构成点(x,y)绘图:如果两个分布很接近,那个点(x,y)会分布在y ...
- 回归模型效果评估系列2-MAE、MSE、RMSE、MAPE(MAPD)
MAE.MSE.RMSE.MAPE(MAPD)这些都是常见的回归预测评估指标,重温下它们的定义和区别以及优缺点吧 MAE(Mean Absolute Error) 平均绝对误差 ...
- 【NLP】蓦然回首:谈谈学习模型的评估系列文章(一)
统计角度窥视模型概念 作者:白宁超 2016年7月18日17:18:43 摘要:写本文的初衷源于基于HMM模型序列标注的一个实验,实验完成之后,迫切想知道采用的序列标注模型的好坏,有哪些指标可以度量. ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- python + sklearn ︱分类效果评估——acc、recall、F1、ROC、回归、距离
之前提到过聚类之后,聚类质量的评价: 聚类︱python实现 六大 分群质量评估指标(兰德系数.互信息.轮廓系数) R语言相关分类效果评估: R语言︱分类器的性能表现评价(混淆矩阵,准确率,召回率,F ...
- R in action读书笔记(11)-第八章:回归-- 选择“最佳”的回归模型
8.6 选择“最佳”的回归模型 8.6.1 模型比较 用基础安装中的anova()函数可以比较两个嵌套模型的拟合优度.所谓嵌套模型,即它的一 些项完全包含在另一个模型中 用anova()函数比较 &g ...
- 机器学习-回归中的相关度和R平方值
1. 皮尔逊相关系数(Pearson Correlation Coefficient) 1.1 衡量两个值线性相关强度的量 1.2 取值范围[-1, 1] 正相关:>0, 负相关:<0, ...
- 深度学习实践系列(1)- 从零搭建notMNIST逻辑回归模型
MNIST 被喻为深度学习中的Hello World示例,由Yann LeCun等大神组织收集的一个手写数字的数据集,有60000个训练集和10000个验证集,是个非常适合初学者入门的训练集.这个网站 ...
- 最小角回归 LARS算法包的用法以及模型参数的选择(R语言 )
Lasso回归模型,是常用线性回归的模型,当模型维度较高时,Lasso算法通过求解稀疏解对模型进行变量选择.Lars算法则提供了一种快速求解该模型的方法.Lars算法的基本原理有许多其他文章可以参考, ...
随机推荐
- Java EE之JSTL(下)
3.使用国际化和格式化标签库(FMT命名空间) 如果你希望创建部署在Web上,并面向庞大的国际化用户的企业级Java应用程序,那么你最终需要为世界的特定区域进行应用程序本地化.这将通过国际化实现(通常 ...
- 解题:USACO13JAN Island Travels
题面 好像没啥可说的,就当练码力了...... 先用BFS跑出岛屿,然后跑最短路求岛屿间的距离,最后状压DP得出答案 注意细节,码码码2333 #include<set> #include ...
- POJ 1966 Cable TV Network 【经典最小割问题】
Description n个点的无向图,问最少删掉几个点,使得图不连通 n<=50 m也许可以到完全图? Solution 最少,割点,不连通,可以想到最小割. 发现,图不连通,必然存在两个点不 ...
- Apache+tomcat配置动静分离(一个apache一个tomcat,没有做集群)
1. 下载apache http server,tomcat,mok_jk.so apache下载地址:http://httpd.apache.org/download.cgi tomcat下载地址: ...
- 【左偏树】【P3261】 [JLOI2015]城池攻占
Description 小铭铭最近获得了一副新的桌游,游戏中需要用 m 个骑士攻占 n 个城池.这 n 个城池用 1 到 n 的整数表示.除 1 号城池外,城池 i 会受到另一座城池 fi 的管辖,其 ...
- 使用VS2012调试Dump文件
前一节我讲了怎么设置C++崩溃时生成Dump文件 , 点击 传送门 , 这一节我讲讲怎么使用 VS2012 调试生成的 Dump 文件 , 甚至可以精确到出错的那一行代码上面 ; 1. 生成 Dump ...
- freemark的常用方法
1,截取字符串 有的时候我们在页面中不需要显示那么长的字符串,比如新闻标题,这样用下面的例子就可以自定义显示的长度 < lt. <= lte. > gt. >= gte < ...
- Hibernate基础知识详解
一.Hibernate框架 Hibernate是一个开放源代码的对象关系映射框架,它对 JDBC进行了非常轻量级的对象封装,它将POJO类与数据库表建立映射关系,是一个 全自动的O ...
- Maven项目导出jar包配置
<!-- 第一种打包方式 (maven-jar-plugin), 将依赖包和配置文件放到jar包外 --> <build> <sourceDirectory>src ...
- ASP.NET CORE API Swagger+IdentityServer4授权验证
简介 本来不想写这篇博文,但在网上找到的文章博客都没有完整配置信息,所以这里记录下. 不了解IdentityServer4的可以看看我之前写的入门博文 Swagger 官方演示地址 源码地址 配置Id ...