[python]MergeTxt按列合并同一个文件下多个txt文件
开发需求:应项目需要,要将记录成txt的实验数据进行按列合并(也即为不同文件上下合并),从而进行机器学习训练.
实验数据类似如此
模拟验证数据
1.txt
*****1*****
abcdefghijklmn
opqrstuvwxyz
hhhhhhhhhhhhhhhhhhh
2.txt
*****2*****
12345678910
11121314151
123456897897
1231564564879
2132564644561
3.txt
*****3*****
wkhdwadadfa
wdawadwfafa
fggfwgwgqws
sssssssssss
4.txt
*****4*****
wdawadwfafa
fggfwgwgqws
sssssssssss
wkhdwadadfa
运行结果
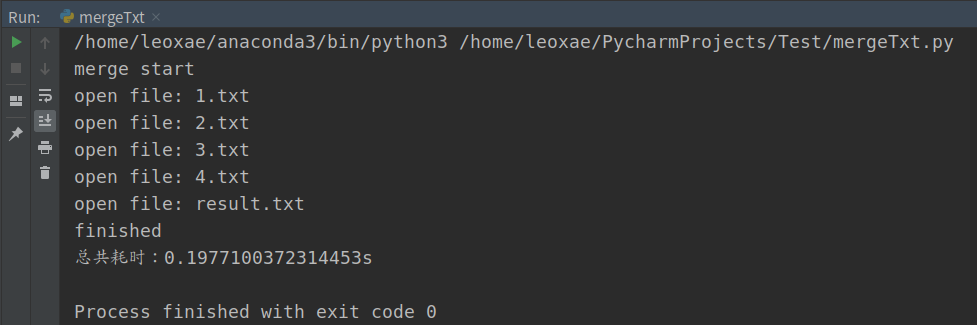
最终结果
# -*- coding:utf-8*-
import sys
import os
import os.path
import time
time_start = time.time()
'''
“a” 以“追加”模式打开, (从 EOF 开始, 必要时创建新文件)
“a+” 以”读写”模式打开
“ab” 以”二进制 追加”模式打开
“ab+” 以”二进制 读写”模式打开
“w” 以”写”的方式打开
“w+” 以“读写”模式打开
“wb” 以“二进制 写”模式打开
“wb+” 以“二进制 读写”模式打开
“r+” 以”读写”模式打开
“rb” 以”二进制 读”模式打开
“rb+” 以”二进制 读写”模式打开
rU 或 Ua 以”读”方式打开, 同时提供通用换行符支持 (PEP 278)
1、使用“w”模式。文件若存在,首先要清空,然后重新创建
2、使用“a”模式。把所有要写入文件的数据都追加到文件的末尾,即使你使用了seek()指向文件的其他地方,如果文件不存在,将自动被创建。
3、f.read([size]) :size未指定则返回整个文件,如果文件大小>2倍内存则有问题。f.read()读到文件尾时返回”“(空字串)
4、file.readline() 返回一行
5、file.readline([size]) 返回包含size行的列表,size 未指定则返回全部行
6、”for line in f: print line” #通过迭代器访问
7、f.write(“hello\n”) #如果要写入字符串以外的数据,先将他转换为字符串.
8、f.tell() 返回一个整数,表示当前文件指针的位置(就是到文件头的比特数).
9、f.seek(偏移量,[起始位置]) : 用来移动文件指针
偏移量 : 单位“比特”,可正可负
起始位置 : 0 -文件头, 默认值; 1 -当前位置; 2 -文件尾
10、f.close() 关闭文件
'''
# 合并同一个文件夹下多个txt#
def MergeTxt(filepath='', outfile='', rmode='', ntag=False):
'''
@param filepath: 合并的文件目录
@param outfile: 合并输出文件目录
@param rmode: 读写模式
@param ntag: 是否换行标记
'''
print('merge start')
# open(path, ‘-模式 -‘, encoding =’UTF - 8’)
k = open(filepath + outfile, rmode)
for parent, dirnames, filenames in os.walk(filepath):
# 需针对当前文件做升序排序,否则按照os.walk的规则,遍历列表是乱序的
filenames.sort(key=None, reverse=False)
for filepath in filenames:
# filepath 即为遍历目录列表中当前文件路径
# txtpath 即为所有文件夹的路径
txtPath = os.path.join(parent, filepath)
print('open file:', filepath)
f = open(txtPath)
if (ntag):
k.write(f.read() + "\n")
else:
k.write(f.read())
k.close()
print('finished')
# 合并同一个文件夹下多个txt#
def MergeTxt_range(filepath='', outfile='', rmode='', ntag=False, range_start = 1, range_end = 31):
'''
@param filepath: 合并的文件目录
@param outfile: 合并输出文件目录
@param rmode: 读写模式
@param ntag: 是否换行标记
'''
print('merge start')
# open(path, ‘-模式 -‘, encoding =’UTF - 8’)
k = open(filepath + outfile, rmode)
for num in range(range_start, range_end):
txtPath = filepath + str(num) + '.txt'
print('txtpath', txtPath)
f = open(txtPath)
if (ntag):
k.write(f.read() + "\n")
else:
k.write(f.read())
k.close()
print('finished')
if __name__ == '__main__':
filepath = "/home/leoxae/PycharmProjects/Test/trainData/dragging/dragging_gz_train/"
outfile = "dragging_gz_train.txt"
rmode = 'a+'
ntag = True
MergeTxt_range(filepath, outfile, rmode, ntag,11,31)
time_end = time.time()
print(u'总共耗时:' + str(time_end - time_start) + 's')
[python]MergeTxt按列合并同一个文件下多个txt文件的更多相关文章
- python 检索一个目录下所有的txt文件,并把文件改为.log
检索一个目录及子目录下所有的txt文件,并把txt文件后缀改为log: import os f_path = r'C:\Users\PycharmProjects\mystudy\Testfolder ...
- python实现将文件夹内所有txt文件合并成一个文件
新建一个文件夹命名为yuliao,把所有txt文件放进去就ok啦!注意路径中‘/’,windows下路径不是这样. #coding=utf-8 import os #获取目标文件夹的路径 filed ...
- python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 python操作txt文件中 ...
- 读取同一文件夹下多个txt文件中的特定内容并做统计
读取同一文件夹下多个txt文件中的特定内容并做统计 有网友在问,C#读取同一文件夹下多个txt文件中的特定内容,并把各个文本的数据做统计. 昨晚Insus.NET抽上些少时间,来实现此问题,加强自身的 ...
- java算法面试题:编写一个程序,将a.txt文件中的单词与b.txt文件中的单词交替合并到c.txt文件中,a.txt文件中的单词用回车符分隔,b.txt文件中用回车或空格进行分隔。
package com.swift; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File ...
- Java关于条件判断练习--统计一个src文件下的所有.java文件内的代码行数(注释行、空白行不统计在内)
要求:统计一个src文件下的所有.java文件内的代码行数(注释行.空白行不统计在内) 分析:先封装一个静态方法用于统计确定的.java文件的有效代码行数.使用字符缓冲流读取文件,首先判断是否是块注释 ...
- php 获取文件下的所有文件。php 获取文件下的所有子文件。php 递归获取文件下的所有文件。封装好的方法
//php 获取文件下的所有文件.php 获取文件下的所有子文件.php 递归获取文件下的所有文件.直接上封装好的php代码 <?php //文件路径 $dir = dirname(__FILE ...
- Java以流的方式将指定文件夹里的.txt文件全部复制到另一文件夹,并删除原文件夹中所有.txt文件
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.Fi ...
- 4.产生10个1-100的随机数,并放到一个数组中 (1)把数组中大于等于10的数字放到一个list集合中,并打印到控制台。 (2)把数组中的数字放到当前文件夹的numArr.txt文件中
package cn.it.text; import java.io.FileWriter; import java.io.IOException; import java.util.ArrayLis ...
随机推荐
- 内存管理——placement new
C++给我们三个申请内存的方式,new(new operator),array new 和placement new. placement new意思是 让对象构建在已经分配好的内存上. (这里我再把 ...
- STL学习笔记1
STL六大部件 容器.分配器.算法.迭代器.适配器.仿函数 他们的关系如下
- 【STM32】使用SDIO进行SD卡读写,包含文件管理FatFs(五)-文件管理初步介绍
其他链接 [STM32]使用SDIO进行SD卡读写,包含文件管理FatFs(一)-初步认识SD卡 [STM32]使用SDIO进行SD卡读写,包含文件管理FatFs(二)-了解SD总线,命令的相关介绍 ...
- Java事务与JTA
一.什么是JAVA事务 通俗的理解,事务是一组原子操作单元,从数据库角度说,就是一组SQL指令,要么全部执行成功,若因为某个原因其中一条指令执行有错误,则撤销先前执行过的所有指令.更简答的说就是:要么 ...
- 最新的Android Sdk 使用Ant多渠道批量打包
实例工程.所需的文件都在最后的附件中. 今天花费了几个小时,参考网上的资料,期间遇到了好几个问题, 终于实现了使用Ant批量多渠道打包,现在,梳理一下思路,总结使用Ant批量多渠道打包的方法:1 ...
- ORACLE 本session产生的redo
select * from v$statname a ,v$mystat bwhere a.STATISTIC# = b.STATISTIC# and a.name = 'redo size';
- iOS-调用系统的短信和发送邮件功能,实现短信分享和邮件分享
一.邮件分享 1.iOS系统自带邮件设置邮箱(此处以QQ邮箱为例)(http://jingyan.baidu.com/album/6181c3e084cb7d152ef153b5.html?picin ...
- UNIX基本命令
### 1. 必学命令 help [子命令] : 查看某一个具体的子命令的使用方法### 2. 常用命令 - cd path : 将当前路径切换到path路径 - pwd : 查看当前所在路径 - l ...
- SpringBoot中使用JUnit4(入门篇)
添加依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>sp ...
- AOP切入点的配置
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...