【07】Jenkins:流水线(Pipeline)
写在前面的话
个人认为 Pipeline 在 Jenkins 中算是一个优化性功能,它能够将我们的构建服务的整个过程流程化,这意味着当我们在执行到某一步的时候,可以添加询问,提示我们是否继续运行下一步。当然,这个东西并非我们必须的,在没有 Pipeline 的时候我们依旧能够很好的完成大部分项目的构建。但是 Pipeline 对于传统构建肯定是一个很好的补充,而且当你习惯以后会爱不释手。
关于流水线(Pipline)
Jenkins 从 2.0 开始逐渐从一个 CI 工具转变成为 CD 工具,Pipeline 在其中扮演着至关重要的角色。配置由界面选择逐渐脚本化(采用 Groovy 脚本),我们可以将配置连同代码一起存放在代码仓库,实现版本控制。一次编写,到处运行。
在 Pipeline 中有两个主要关键字需要先简单的了解,可能有些地方还能见到 Step 关键字:
1. Stage:阶段,这其实就是我们将任务细分为多个过程。
2. Node:节点,前面提到过,Jenkins 是可以分布式的,Node 标记着具体在 Master 还是 Slave 运行这个构建。
简单上手
可能我们目前并不知道 Groovy 脚本的语法到底是什么样子,但是可以结合下面的例子慢慢的进行了解。
1. 新建 Pipeline 任务:
可以发现 Pipeline 的配置非常简单,简单到你都找不到哪里拉取代码,其主要的功能都集中在这个脚本框中:
2. 添加 Hello World:

可以看到,由于我们只有一步,所以在 node 关键字下面就只有一个 Step,执行 echo 输出操作。
值得注意的是,这的 echo 并不是我们 Linux 中的 echo 命令,这个 echo 是 Groovy 的关键字,就像 Python 中的 print 一样。
保存退出!
3. 执行构建,查看输出:

我们发现和普通构建执行 Shell 输出感觉差不多,那么我们可以复杂一下步骤!
4. 修改之前的流水线配置,加入步骤:
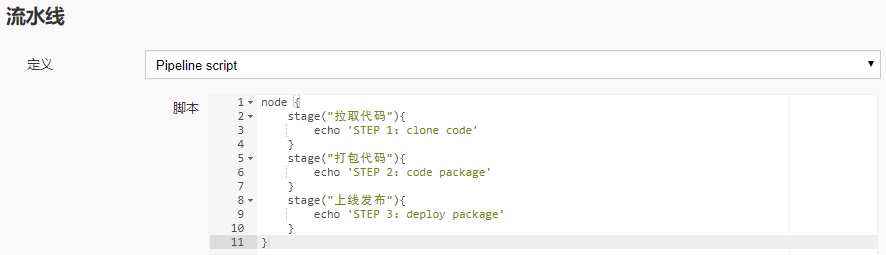
需要知道的是,这个输入框贼难用,建议外部写好粘贴进去:
node {
stage("拉取代码"){
echo 'STEP 1:clone code'
}
stage("打包代码"){
echo 'STEP 2:code package'
}
stage("上线发布"){
echo 'STEP 3:deploy package'
}
}
保存执行构建:
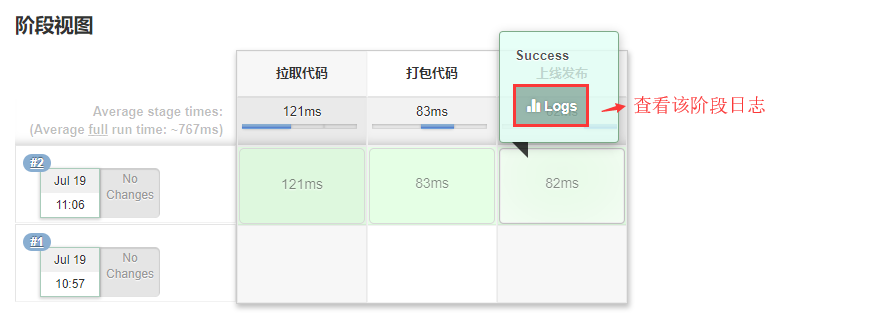
我们可以看到,本次构建按照我们配置的 Stage 分成了三步,我们甚至能够看到每一个过程耗时,做到单独查看该过程的日志。

当然,我们依旧可以去控制台输出里面查看整个过程的全部日志。但是细分的好处在于出问题我们更好的查找到问题所在。
5. Pipeline 语法说明:
我们知道了如何分步骤,但是却只直到一个 echo,显然无法满足我们的需求。在我们填写 Pipeline 的地方有告知语法。

在这里,我们可以通过配置,生成我们常用的语法,比如生成 git 拉代码:

将配置放到我们流水线脚本中,然后配置打包命令:
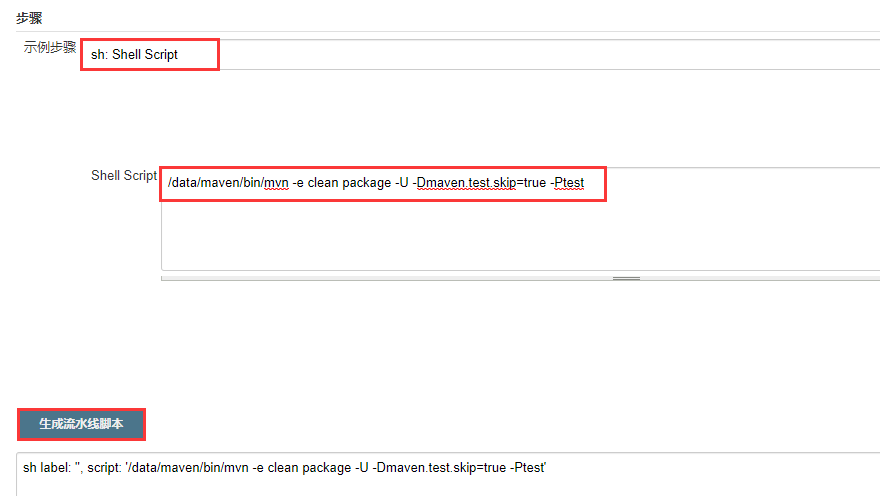
其实运行 Linux 命令是可以简写的,直接:sh '命令' 这样就行。
由于我们本次 mvn 执行构建其实际是依赖于 JDK 的,而我们本地又有多个版本 JDK,所以还需要指定环境变量:

此时我们的脚本变成:
node {
stage("拉取代码"){
echo 'STEP 1:clone code'
git credentialsId: 'xxx', url: 'http://192.168.10.199:8041/xxx.git'
}
stage("打包代码"){
echo 'STEP 2:code package'
withEnv(['JAVA_HOME=/data/jdk7']) {
sh '/data/maven/bin/mvn -e clean package -U -Dmaven.test.skip=true -Ptest'
}
}
stage("上线发布"){
echo 'STEP 3:deploy package'
}
}
注意上面 git 的地址是你自己生成的地址!
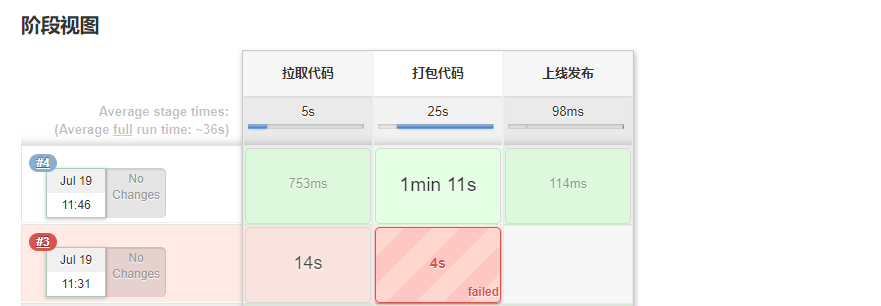
因为我之前没有配置环境变量,多以可以看到构建报错,后面添加环境变量以后就不再出现报错。
当然,withEnv 其实属性是一个 list,所以我们其实是可以定义多个变量的,可以像下面一样,并去调用它:
withEnv(['JAVA_HOME=/data/jdk7', 'NAME="hello"']) {
echo "${NAME}"
echo "${JAVA_HOME}"
}
至于其他的一些语法,如 sleep,timeout 等我们也可找到对用的语法生成。如果你实在懒得去深究,那么 sh 已经能够满足你大部分需求。
同时,在 Pipline 中依然是支持参数化构建的,意味着我们也可以以变量的形式直接引用。
另外有一个特殊的可以说明一下:input
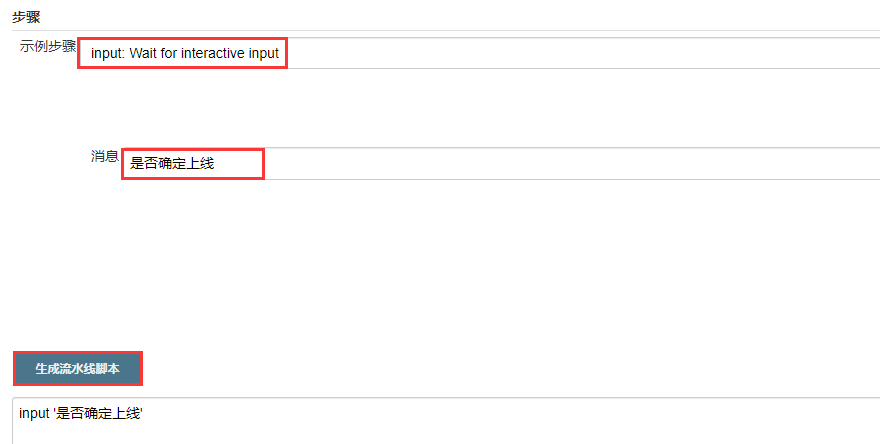
将生成的加入我们的配置中:
node {
stage("拉取代码"){
echo 'STEP 1:clone code'
git credentialsId: 'xxxxx', url: 'http://192.168.10.199:8041/xxxxxx.git'
}
stage("打包代码"){
echo 'STEP 2:code package'
withEnv(['JAVA_HOME=/data/jdk7']) {
sh '/data/maven/bin/mvn -e clean package -U -Dmaven.test.skip=true -Ptest'
}
input '是否确定上线'
}
stage("上线发布"){
echo 'STEP 3:deploy package'
}
}
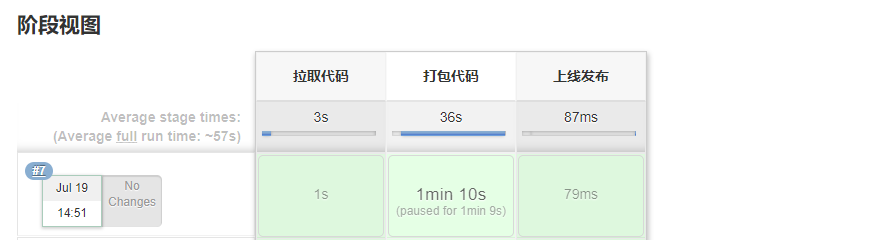
再度构建:

发现卡在了第二步,我们点击查看:

点击以后步骤继续执行:
GitLab 显示构建状态
这其实是一个特殊需求,我们项目在测试阶段一般都存在于开发分支,当测试完成以后才会被提交合并到主干分支。这其中就会有一个问题,具有合并的人能够看到你的代码,但是它并不知道你的代码是否能够正常的构建通过,所以我们希望在 GitLab 上面显示我们测试构建的状态。
具体流程:开发提交代码到 dev 分支 --> 触发 Jenkins 自动构建 --> 构建结果显示到 GitLab 的 Merge request 上
1. 创建 Pipline 任务:
2. 将 GitLab 上我们之前的项目创建一个 dev 分支:
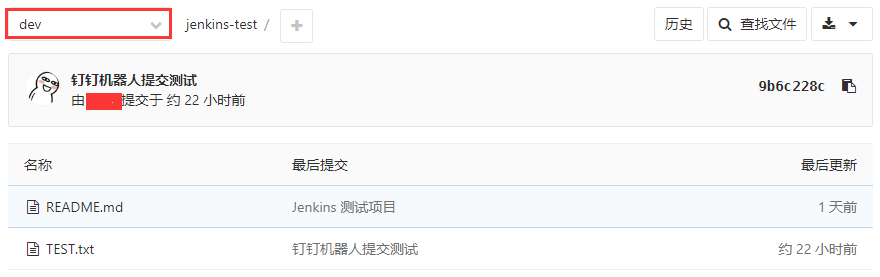
3. Jenkins 配置自动触发构建,之前有详细讲过:
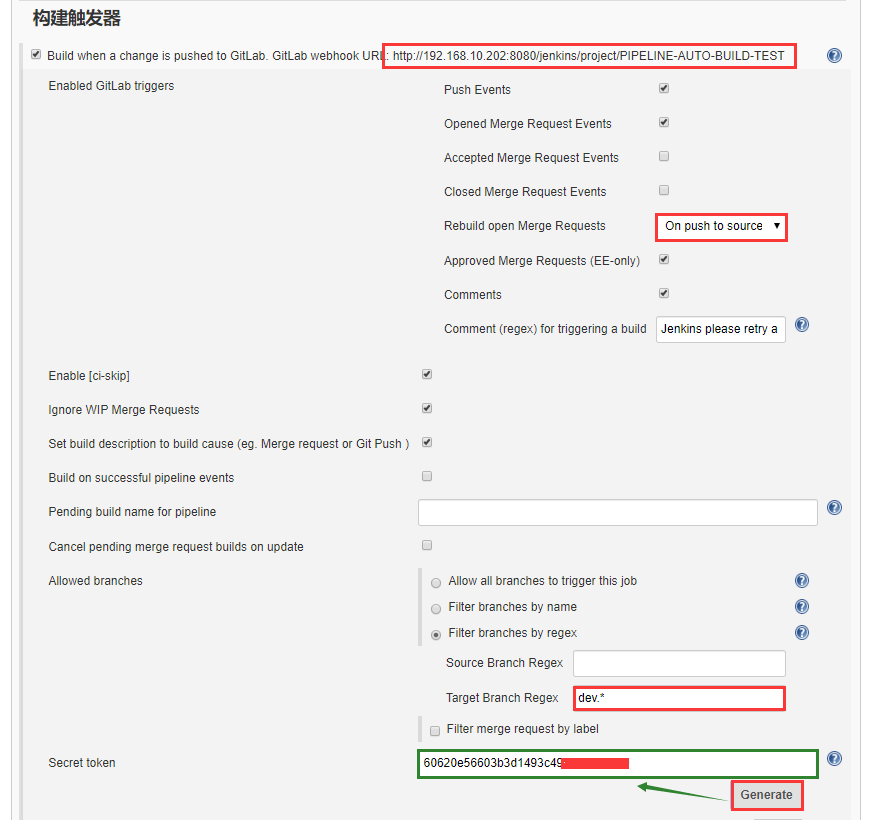
4. GitLab 添加 Jenkins Token:
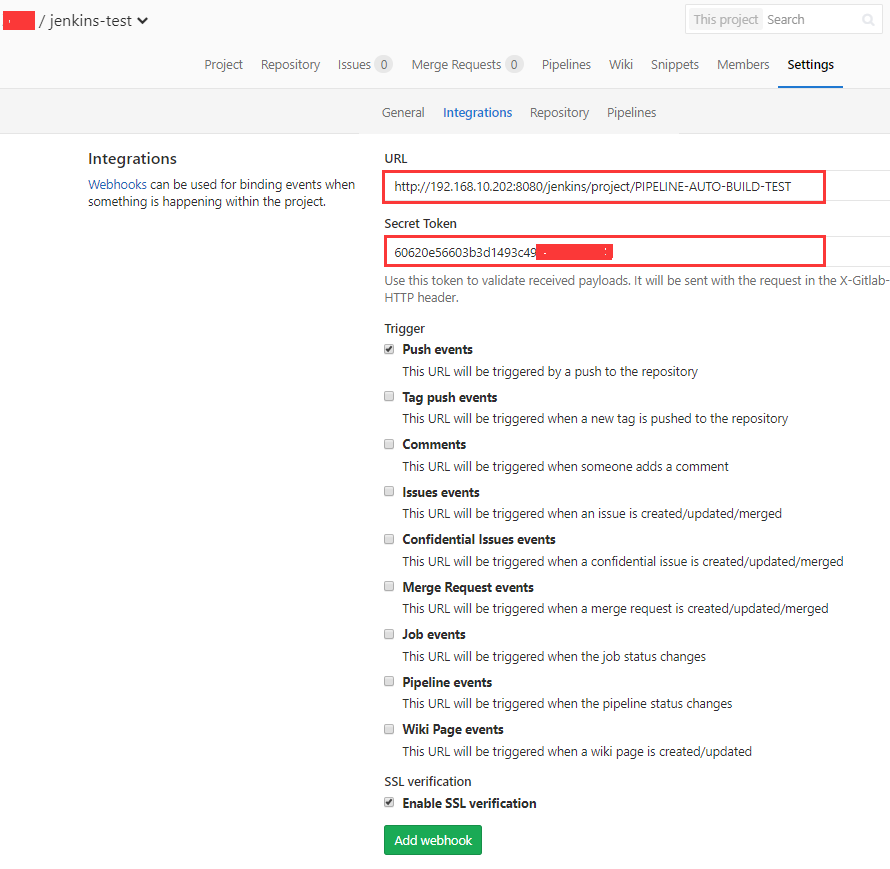
5. Jenkins 添加 Pipeline 操作:
生成 git 拉去配置:

配置 Pipeline 操作:
node {
stage("拉取代码"){
echo 'STEP 1:clone code'
git branch: 'dev', credentialsId: 'xxx', url: 'http://192.168.10.199:8041/xxx.git'
}
stage("打包代码"){
echo 'STEP 2:code package'
}
stage("上线发布"){
echo 'STEP 3:deploy package'
}
}
6. 提交分支测试:

可以看到触发自动构建成功。
此时我们创建合并请求:
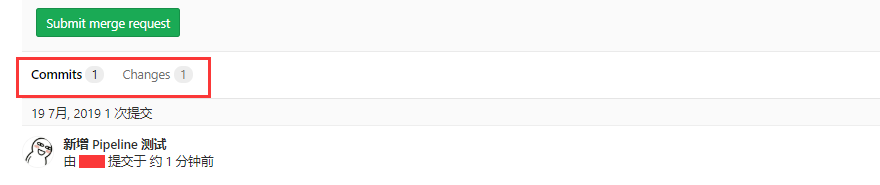
7. GitLab 创建用户 API 授权 Token:
这里就会用到上一节我们说没用的配置,因为上一节其实是 GitLab 触发 Jenkins,所以 Jenkins 不需要 GitLab 的其他权限。
但是这一节不同,Jenkins 需要将构建结果返回给 GitLab,所以这时候就需要这个 Token 了。
GitLab 配置用户授权 Token:

创建 Token,勾选 API 权限:
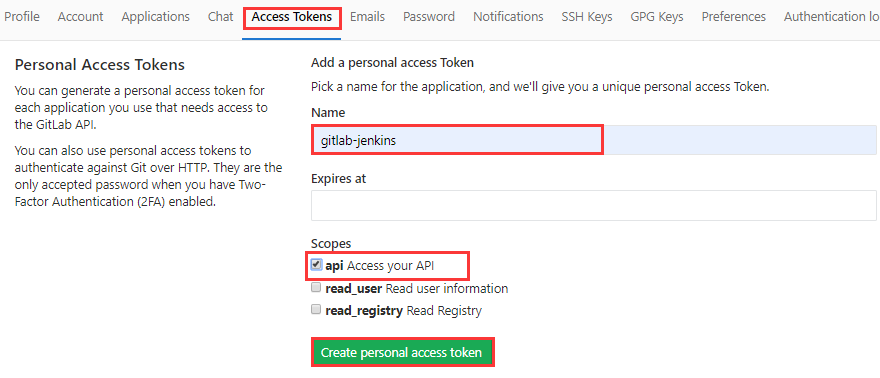
记住这个 Token,因为只能看到这一次,忘了只能重新创建:

8. Jenkins 配置 GitLab 授权 Token:
打开:系统管理 --> 系统设置
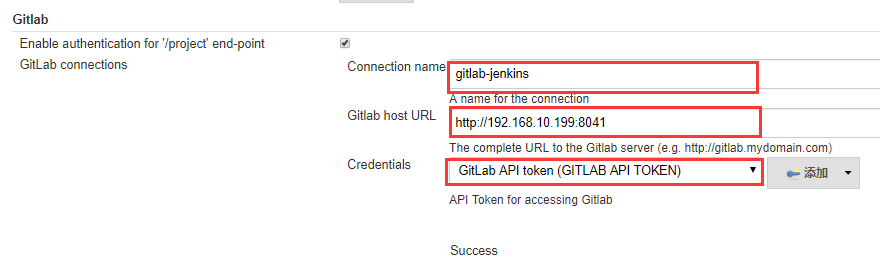
添加的 Token 的时候注意类型是:GitLab API token
9. 修改 Pipeline 的配置:
node {
gitlabCommitStatus{
stage("拉取代码"){
echo 'STEP 1:clone code'
git branch: 'dev', credentialsId: 'xxx', url: 'http://192.168.10.199:8041/xxx.git'
}
stage("打包代码"){
echo 'STEP 2:code package'
}
stage("上线发布"){
echo 'STEP 3:deploy package'
}
}
}
注意:我们在外层添加了 gitlab 的配置。
10. 此时提交代码触发构建:

11. GitLab 提交合并请求:
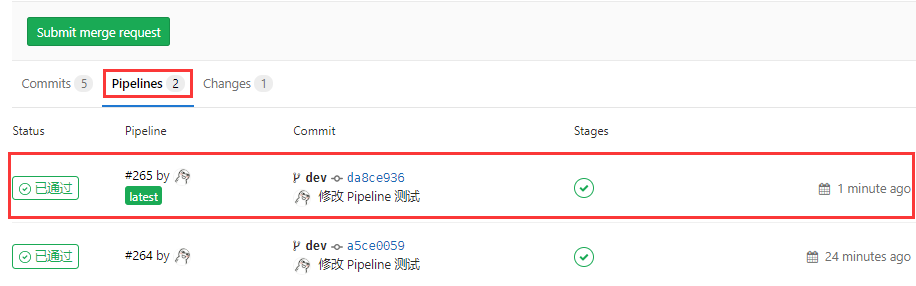
此时我们可以看到在合并请求下方,多了一个 Pipelines 的栏目,里面有我们构建的结果。
这个处理的作用在于,在我们上线合并代码之前,我们能够知道代码是否存在问题,保证我们上线构建。
扩展插件:Blue Ocean
什么是 Blue Ocean?这其实就是 Jenkins 的一个主题,针对 Pipeline 显示做了优化,看起来更牛逼了。
可以去插件中心安装:

安装完成重启后,会在侧边栏增加入口:

可以直接进去查看:
全新的构建过程页面,颜值更高:
感兴趣的可以自己去研究,毕竟 Jenkins 本身的界面已经很多年没变过了,确实丑了点。
小结
Pipeline 的配置简单的可以谈到这里,另外还有他的 SCM 的配置,相对来说比较复杂,包括 Jenkinsfile,感兴趣可以去深入研究,我们还是那个观点,这些配置都是为了服务我们更好的完成工作的。如果学习成本太高但是又没有实质性跨越性的提高我们使用能力。有些知识是可以舍弃的。干我们这行要懂得取舍,不然得学的东西实在太多。
【07】Jenkins:流水线(Pipeline)的更多相关文章
- Jenkins流水线(pipeline)实战之:从部署到体验
关于Jenkins流水线(pipeline) Jenkins 流水线 (pipeline) 是一套插件,让Jenkins可以实现持续交付管道的落地和实施. 关于blueocean Blue Ocean ...
- jenkins的流水线pipeline+项目实验php
声明:实验环境使用Jenkins的应用与搭建的环境 新建一个流水线 pipeline脚本语法架构 node('slave节点名'){ def 变量 #def可以进行变量声明 stage('阶段名A') ...
- jenkins中的流水线( pipeline)的理解(未完)
目录 一.理论概述 Jenkins流水线的发展历程 什么是Jenkins流水线 一.理论概述 pipeline是流水线的英文释义,文档中统一称为流水线 Jenkins流水线的发展历程 在Jenki ...
- jenkins中的流水线( pipeline)的理解(未完)
目录 一.理论概述 Jenkins流水线的发展历程 什么是Jenkins流水线 一.理论概述 pipeline是流水线的英文释义,文档中统一称为流水线 Jenkins流水线的发展历程 在Jenki ...
- 8.Jenkins进阶之流水线pipeline基础使用实践(1)
目录一览: 0x01 基础实践 (1) Maven 构建之 Pipeline Script (2) Maven 构建之 Pipeline Script from SCM (3) Jenkins pi ...
- 6.Jenkins进阶之流水线pipeline语法入门学习(1)
目录一览: 0x00 前言简述 Pipeline 介绍 Pipeline 基础知识 Pipeline 扩展共享库 BlueOcean 介绍 0x01 Pipeline Syntax (0) Groov ...
- Jenkins流水线获取提交日志
写在前 之前使用Jenkins pipeline的时候发现拿不到日志,使用multiple scms插件对应是日志变量获取日志的方式失效了, 但是查看流水线Pipeline Syntax发现check ...
- [转]利用Jenkins的Pipeline实现集群自动化部署SpringBoot项目
环境准备 Git: 安装部署使用略. Jenkins: 2.46.2版本安装部署略(修改jenkins执行用户为root,省得配置权限) JDK: 安装部署略. Maven: 安装部署略. 服务器免密 ...
- 1. Tensorflow高效流水线Pipeline
1. Tensorflow高效流水线Pipeline 2. Tensorflow的数据处理中的Dataset和Iterator 3. Tensorflow生成TFRecord 4. Tensorflo ...
- Hadoop架构: 流水线(PipeLine)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 流水线(PipeLine),简单地理解就是客户端向DataNode传输数据(Packet)和接收Dat ...
随机推荐
- Django框架(十六)-- 中间件、CSRF跨站请求伪造
一.什么是中间件 中间件是介于request与response处理之间的一道处理过程,相对比较轻量级,并且在全局上改变django的输入与输出 二.中间件的作用 如果你想修改请求,例如被传送到view ...
- linux下c语言实现多线程文件复制【转】
转自:https://www.cnblogs.com/zxl0715/articles/5365989.html .具体思路 把一个文件分成N份,分别用N个线程copy, 每个线程只读取指定长度字节大 ...
- Axel多线程工具安装
Axel 是 Linux 下一个不错的轻量级高速下载工具,支持HTTP/FTP/HTTPS/FTPS协议,支持多线程下载.断点续传,且可以从多个地址或者从一个地址的多个连接来下载同一个文件. 大家使用 ...
- 3.3 Spark的部署和应用方式
一.Spark的部署 1.单机Local 2.集群 (1)Standalonc Spark自带的资源管理器,效率不高 (2)YARN 如果部署的是Hadoop集群,可以用YARN资源调度 (3)Mes ...
- 无法解析的外部符号 "void __cdecl cv::imshow
解决方法: 把编译环境放到其他没有报错的项目上,编译通过.
- Python玩转微信小程序
用Python玩转微信 Python玩转微信 大家每天都在用微信,有没有想过用python来控制我们的微信,不多说,直接上干货! 这个是在 itchat上做的封装 http://itchat. ...
- springcloud注解解释
@SpringBootApplication是springboot启动类,包括三个注解,他们的作用分别是: @Configuration:表示将该类作用springboot配置文件类 @Enabl ...
- zz在自动驾驶研发中充分发挥数据的潜能
本次分享内容提纲 数据标注 数据驱动开发 数据驱动决策 前言 上图这是我加入小马智行之前的一个小故事.这不断的提醒我,人工智能需要有足够的数据量,并且充分发挥这些数据的潜能,是我们作为人工智能公司的一 ...
- 批处理教程之cls、pause命令
cls 命令 清除屏幕.执行该命令后,屏幕上的所有信息都被清除,光标重新定位至屏幕左上角. REM 和 :: REM为注释命令,一般用来给程序加上注解,该命令后的内容不被执行,但能回显. 其次 ...
- 【php】day01
一.PHPCORE基础 1.什么是PHP:[Hypertext Preprocessor] WEB程序开发语言,运行在服务器端 的 ...