Mesa: GeoReplicated, Near RealTime, Scalable Data Warehousing
Mesa的定义并没有反映出他的特点,因为分布式,副本,高可用,他都是依赖google的其他基础设施完成的
他最大的特点是,和传统数仓比,可以做到near real-time的返回聚合的查询结果
算入实时数仓的范围,做到数据一致性,高吞吐的写入,并提供较好的查询性能


所以Mesa的核心是Storage Subsystem如何设计的,
提出一个数仓的经典问题,
提出,dimensional和measure attributes的概念,那么一般dimensional具备hierarchical的特点,比如时间,那么在每个一个layer上都会形成一个物化视图
对于数仓,在dimensional上进行drill-downs和roll-ups,就称为一个最常见的操作
但是对于实时数仓,这就是一个难题,当数据实时写入的时候,如何保证每个物化视图的数据都是同步的,或者可以实时更新

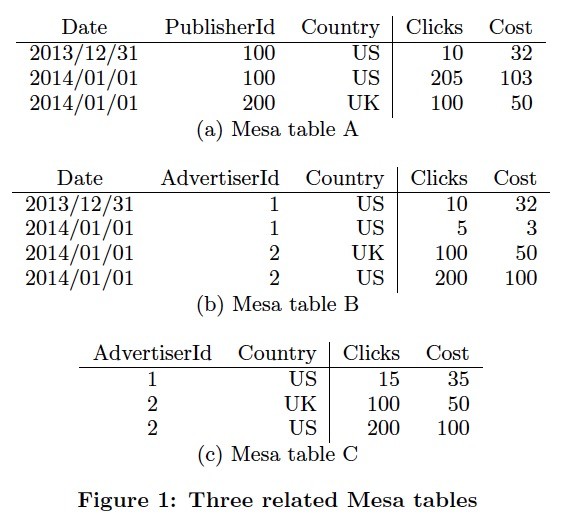
Mesa的Table schema里面除了要定义,传统的key,value的类型,
还需要定义Aggre函数,一定要满足结合律,但是交换律不是强要求
右边的例子中,可以看出,c是b的一个物化视图

Update和查询
更新关键是要batch,而且这个batch是要上游来保证的,mesa自己也不会cache batch,这个batch通常是分钟级别的,这如果大流量的数据,分钟级别要多大的batch
并且每个batch都会有一个递增version,更新的时候,也是需要根据version来严格按顺序更新,这个来保证atomicity
查询的时候需要带上version number


更新的例子,
更新两个版本,这里没有直接更新c,因为c是b的物化视图,b更新后,Mesa会自动更新c
Mesa论文并没有太多细节讨论,如何高效的更新物化视图,可能他们没有做什么特别的设计,但是如果要所有视图一致,等所有视图更新完,update才返回?
版本数据管理
这里抛出问题,
如果保留所有的原始数据,很expensive
如果要在查询的时候聚合所有的数据,很expensive
但是如果在插入的时候去做预聚合,也很expensive
所以这里的设计其实也很直觉,
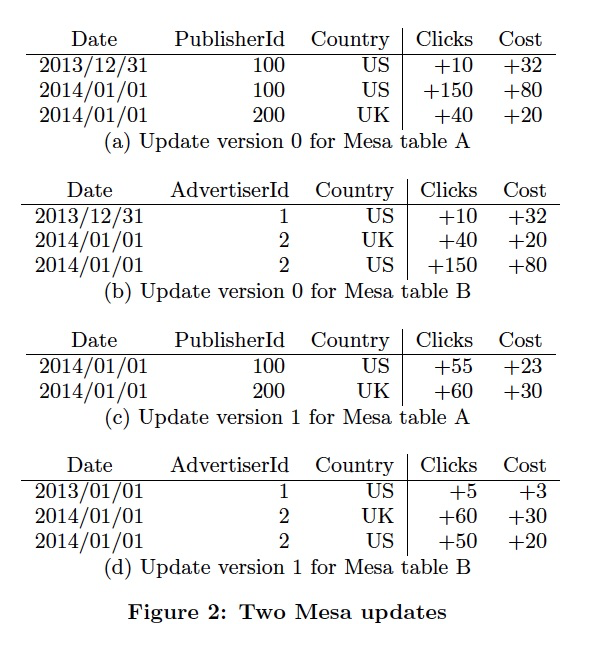
写入的时候不能update,只能append,这样才能高吞吐,所以写入只能记录deltas,deltas是batch级别的,至少包含一个version,batch内部预先聚合,这种称为Singletons,如图最右
查询的时候,如果要聚合所有的deltas得到结果,可能不行,所以需要定期把老的delta做compaction,这个叫base compaction
这样查询性能还是不够,那么把新的deltas做小batch的compaction,称为delta compaction,如图,中间,10个version compaction一下
这样查询的时候,可以根据时间或条件,尽量prune deltas,如果老数据,直接读base,新数据,就用cumulatives的结果和部分的Singletons的结果进行聚合





后面论文还讲了一堆的东西,无甚亮点
Mesa核心就是这套版本管理设计,可以参考借鉴
同样的问题,Mesa的数据结构设计的也比较粗糙,Confluo的数据结构设计的更加精妙
Mesa: GeoReplicated, Near RealTime, Scalable Data Warehousing的更多相关文章
- What’s the difference between data mining and data warehousing?
Data mining is the process of finding patterns in a given data set. These patterns can often provide ...
- Druid: A Real-time Analytical Data Store
Druid一种实时数仓,针对的场景和目的,如下比较明确 Druid was originally designed to solve problems around ingesting and exp ...
- Building LinkedIn’s Real-time Activity Data Pipeline
转自:http://blog.163.com/guaiguai_family/blog/static/20078414520138911393767/ http://sites.computer.or ...
- dataware fact 事实 不可更新 data warehousing business intelligence 优劣判据
不可 Kimball维度建模 维度建模,而非数据建模 文本型度量是对某些事情的描述.虽然以文本方式度量事实是可行的,但是应将其放入维度表中,除非对事实表的每个行,其文本是唯一的. 数据仓库的好坏直接取 ...
- Ubiq:A Scalable and Fault-tolerant Log Processing Infrastructure
Abstract 互联网应用通常会产生大量的时间日志需要进行分析和处理.本文介绍Ubiq的架构,它是一个分布式系统,用于处理不断增长的日志文件,具有可扩展性.高可用.低延迟的特性.Ubiq框架容忍基础 ...
- (转) [it-ebooks]电子书列表
[it-ebooks]电子书列表 [2014]: Learning Objective-C by Developing iPhone Games || Leverage Xcode and Obj ...
- The Log: What every software engineer should know about real-time data's unifying abstraction
http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-abo ...
- Visualize real-time data streams with Gnuplot
源文地址 (September 2008) For the last couple of years, I've been working on European Space Agency (ESA) ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
随机推荐
- Java 之 Collection 接口
一.Collection 集合 Collection:单列集合类的根接口,用于存储一系列符合某种规则的元素,它有两个重要的子接口,分别是 java.util.List 和 java.util.Set. ...
- 给WEB DYNPRO 程序创建TCODE
1,创建WDA程序,这里就不介绍了,使用现成的程序:ZCRM_ME_SATISFACTION 2,SE93创建TCODE,输入事物代码ZLYTEST点击创建,选择带参数的事物代码. 3,填写事物WDY ...
- docker建镜像
docker建镜像 # build docker build -t $(BASE):$(TAG) -f run.docker . Dockerfile Dockerfile是自定义镜像的一个重要帮手, ...
- centos下导入mysql数据库
先进入mysql1.mysql -u root -p2.输入密码3.use 要导入的数据库名(没有就新建一个,使用create database test;命令新建,再use test;,再set n ...
- WingIDE Pro 7如何检查Python集成?
在开始使用某些代码之前,让我们确保Wing已成功找到您的Python安装.立即从“ 工具”菜单中打开Python Shell工具.如果一切顺利,它应该启动Python并向您显示Python命令提示符, ...
- 常用Windows命令、常用 Cmd命令(补充)
常用的Windows 命令使用能够提升工作效率以及快捷处理事项. 下面为平时常用的Windows 命令/cmd 命令. 一.以下命令无需打开cmd 窗口即可操作(输入完毕 打个 回车,即可执行). 1 ...
- Refrence
深入详解美团点评CAT跨语言服务监控(一) CAT简介与部署 https://blog.csdn.net/caohao0591/article/details/80693289 搭建大众点评CAT监控 ...
- 如何监控网站URL是否正常?
监控网站URL是否正常最常见的方法莫过于wget和curl命令了,这两个命令都是非常强大的,强大到网友查看帮助都无从选择的地步了,今天呢,老男孩老师正好录制Shell编程实战课程,因此,顺便总结了一下 ...
- js生成随机密码,密码位数自定
话不多说,上代码 function pb(size){ var seed = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N', ...
- Blink示例程序
打开Arduino IDE(话说与Processing IDE的UI好像啊 然后将这段代码输入.也可从文件>例子>01.Basics/Blink(File/Examples/01.Basi ...