Mesa: GeoReplicated, Near RealTime, Scalable Data Warehousing
Mesa的定义并没有反映出他的特点,因为分布式,副本,高可用,他都是依赖google的其他基础设施完成的
他最大的特点是,和传统数仓比,可以做到near real-time的返回聚合的查询结果
算入实时数仓的范围,做到数据一致性,高吞吐的写入,并提供较好的查询性能


所以Mesa的核心是Storage Subsystem如何设计的,
提出一个数仓的经典问题,
提出,dimensional和measure attributes的概念,那么一般dimensional具备hierarchical的特点,比如时间,那么在每个一个layer上都会形成一个物化视图
对于数仓,在dimensional上进行drill-downs和roll-ups,就称为一个最常见的操作
但是对于实时数仓,这就是一个难题,当数据实时写入的时候,如何保证每个物化视图的数据都是同步的,或者可以实时更新

Mesa的Table schema里面除了要定义,传统的key,value的类型,
还需要定义Aggre函数,一定要满足结合律,但是交换律不是强要求
右边的例子中,可以看出,c是b的一个物化视图

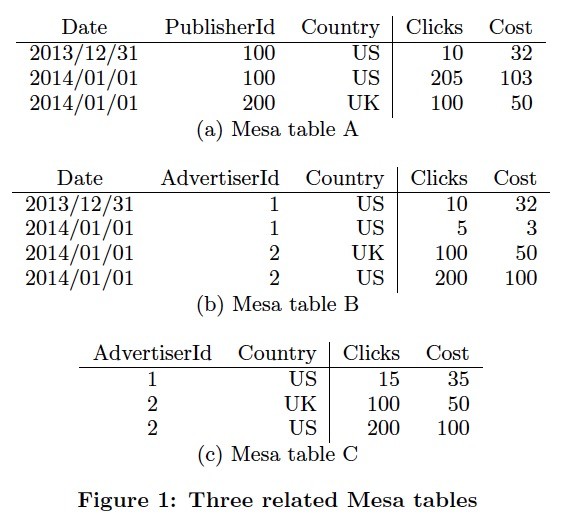
Update和查询
更新关键是要batch,而且这个batch是要上游来保证的,mesa自己也不会cache batch,这个batch通常是分钟级别的,这如果大流量的数据,分钟级别要多大的batch
并且每个batch都会有一个递增version,更新的时候,也是需要根据version来严格按顺序更新,这个来保证atomicity
查询的时候需要带上version number


更新的例子,
更新两个版本,这里没有直接更新c,因为c是b的物化视图,b更新后,Mesa会自动更新c
Mesa论文并没有太多细节讨论,如何高效的更新物化视图,可能他们没有做什么特别的设计,但是如果要所有视图一致,等所有视图更新完,update才返回?
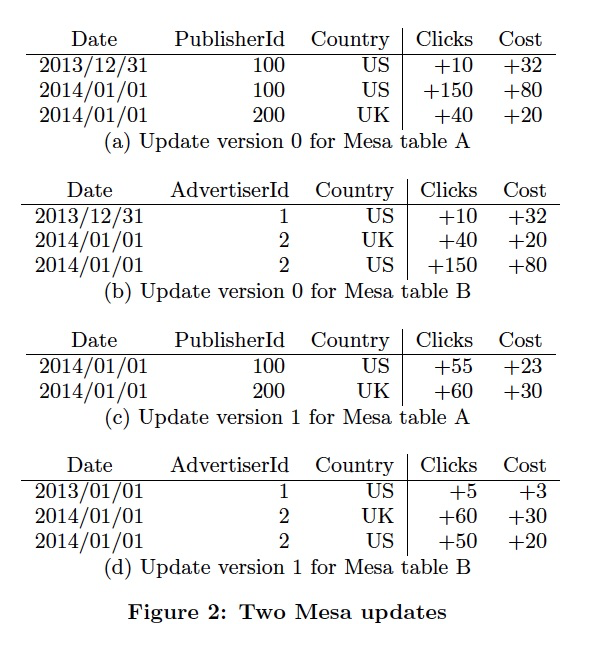
版本数据管理
这里抛出问题,
如果保留所有的原始数据,很expensive
如果要在查询的时候聚合所有的数据,很expensive
但是如果在插入的时候去做预聚合,也很expensive
所以这里的设计其实也很直觉,
写入的时候不能update,只能append,这样才能高吞吐,所以写入只能记录deltas,deltas是batch级别的,至少包含一个version,batch内部预先聚合,这种称为Singletons,如图最右
查询的时候,如果要聚合所有的deltas得到结果,可能不行,所以需要定期把老的delta做compaction,这个叫base compaction
这样查询性能还是不够,那么把新的deltas做小batch的compaction,称为delta compaction,如图,中间,10个version compaction一下
这样查询的时候,可以根据时间或条件,尽量prune deltas,如果老数据,直接读base,新数据,就用cumulatives的结果和部分的Singletons的结果进行聚合





后面论文还讲了一堆的东西,无甚亮点
Mesa核心就是这套版本管理设计,可以参考借鉴
同样的问题,Mesa的数据结构设计的也比较粗糙,Confluo的数据结构设计的更加精妙
Mesa: GeoReplicated, Near RealTime, Scalable Data Warehousing的更多相关文章
- What’s the difference between data mining and data warehousing?
Data mining is the process of finding patterns in a given data set. These patterns can often provide ...
- Druid: A Real-time Analytical Data Store
Druid一种实时数仓,针对的场景和目的,如下比较明确 Druid was originally designed to solve problems around ingesting and exp ...
- Building LinkedIn’s Real-time Activity Data Pipeline
转自:http://blog.163.com/guaiguai_family/blog/static/20078414520138911393767/ http://sites.computer.or ...
- dataware fact 事实 不可更新 data warehousing business intelligence 优劣判据
不可 Kimball维度建模 维度建模,而非数据建模 文本型度量是对某些事情的描述.虽然以文本方式度量事实是可行的,但是应将其放入维度表中,除非对事实表的每个行,其文本是唯一的. 数据仓库的好坏直接取 ...
- Ubiq:A Scalable and Fault-tolerant Log Processing Infrastructure
Abstract 互联网应用通常会产生大量的时间日志需要进行分析和处理.本文介绍Ubiq的架构,它是一个分布式系统,用于处理不断增长的日志文件,具有可扩展性.高可用.低延迟的特性.Ubiq框架容忍基础 ...
- (转) [it-ebooks]电子书列表
[it-ebooks]电子书列表 [2014]: Learning Objective-C by Developing iPhone Games || Leverage Xcode and Obj ...
- The Log: What every software engineer should know about real-time data's unifying abstraction
http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-abo ...
- Visualize real-time data streams with Gnuplot
源文地址 (September 2008) For the last couple of years, I've been working on European Space Agency (ESA) ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
随机推荐
- AttributeError: module 'matplotlib' has no attribute 'verbose'
AttributeError: module 'matplotlib' has no attribute 'verbose' 翻译:attributeError:模块“matplotlib”没有“ve ...
- Go语言入门——interface
1.Go如何定义interface Go通过type声明一个接口,形如 type geometry interface { area() float64 perim() float64 } 和声明一个 ...
- MySQL Config--参数innodb_flush_method
延迟写 传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘I/O都通过缓冲进行.当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其排入输 ...
- Jquery学习笔记,全面实用,需要的可以留下邮箱,给大家发原稿文档
JQuery 第一章:Jquery概念介绍 1.1 Jquery介绍 (1)并不是一门新语言.将常用的.复杂的操作进行函数化封装,直接调用,大大降低了使用JavaScript的难度,改变了使用Java ...
- getResourceAsStream的路径问题
1.Class类的getResourceAsStream this.getClass().getResourceAsStream("/resource.properties"); ...
- main process exited, code=exited, status=203/EXEC
问题描述: Oct :: c_3. systemd[]: Started etcd. Oct :: c_3. systemd[]: Starting etcd... Oct :: c_3. syste ...
- 【爬虫】Load版的生产者和消费者模式
''' Lock版的生产者和消费者模式 ''' import threading import random import time gMoney = 1000 # 原始金额 gLoad = thre ...
- 树莓派安装realvnc_server
先 sudo raspi-config 打开VNC. 然后去realvnc官网去下载raspberry的vncserver 已经ssh连接的前提下可以电脑下载后使用scp命令转移到树莓派上,使用以下命 ...
- 【Yellow Cards CodeForces - 1215A 】【贪心】
该题难点在于求最小的离开数,最大的没什么好说的,关键是求最小的. 可以这样去想,最小的离开数就是每个人获得的牌数等于他所能接受的最大牌数-1,这样就可以直接比较m=a1(k1-1)+a2(k2-1)与 ...
- 云打印 对Echo的Beta产品测试报告
云打印 对Echo的Beta产品测试报告 课程名称:软件工程1916|W(福州大学) 团队名称: 云打印 作业要求: 项目Beta冲刺(团队) 作业目标:作业集合 团队队员 队员学号 队员姓名 个人博 ...