Hadoop(四)—— MapReduce
一、Hadoop版本特性
MRv1
第一代计算框架,由编程模型和运行时环境两部分组成。
编程模型是,将数据进行map操作,然后进行reduce操作,最后将计算结果存储到HDFS中。
运行时环境是,由JobTracker和TaskTracker组成,JobTracker进行资源管理和作业控制。TaskTracker负责接收JobTracker分配的任务并执行。
YARN/MRv2
针对MRv1的问题,提出YARN资源管理框架,将JobTracker中的资源管理和作业控制分开,资源管理由ResourceManager进程实现,作业控制由ApplicationMaster进程实现。
二、模型概述
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the Writable interface. Additionally, the key classes have to implement the WritableComparable interface to facilitate sorting by the framework.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
map()
对多个key/value进行处理产生对应的新的key/value。
reduce()
对key/value进行处理,生成最终结果。
MapReduce架构
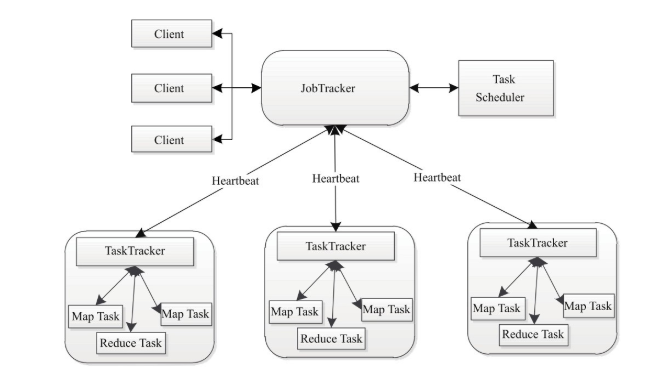
实现一个MapReduce程序
对数据进行处理。找出所有年份中的最高气温。
引入Jar包
<!-- hadoop mapreduce编程所需jars -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
MapReduce模型
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable(可靠的), fault-tolerant manner(方式).
MR是一个软件框架,可以简化编写应用,用于在分布式环境下,用一种可用、容错的方式处理大规模数据。
A MapReduce job usually splits the input data-set into independent chunks(块、片) which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
一个MR任务,通常将输入的数据集用map任务以完全并行的方式处理成独立的块。
参考文档
Hadoop技术内幕:深入解析MapReduce架构设计与实现原理
Hadoop(四)—— MapReduce的更多相关文章
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
随机推荐
- JavaWeb 之 Filter 验证用户登录案例
需求: 1. 访问一个网站的资源.验证其是否登录 2. 如果登录了,则直接放行. 3. 如果没有登录,则跳转到登录页面,提示"您尚未登录,请先登录". 代码实现: import j ...
- Integer装箱拆箱、参数传递
拆箱装箱 举个例子 @Test public void testEquals() { int int1 = 12; int int2 = 12; Integer integer1 = new Inte ...
- nepenthes用法
安装 # apt-get install nepenthes 配置文件 # vi submit-file.conf submit-file { path "/var/lib/nepenthe ...
- AudioToolbox--利用AudioQueue音频队列,通过缓存对声音进行采集与播放
都说iOS最恶心的部分是流媒体,其中恶心的恶心之处更在即时语音. 所以我们先不谈即时语音,研究一下,iOS中声音采集与播放的实现. 要在iOS设备上实现录音和播放功能,苹果提供了简单的做法,那就是利用 ...
- scrapy 下载器中间件 随机切换user-agent
下载器中间件如下列表 ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewa ...
- let 和 var 定义变量的区别
一.变量提升 var 存在变量提升,而 let 不存在变量提升,所以用 let 定义的变量一定要在声明后再使用,否则会报错. var //var定义的变量存在变量提升,变量会把声明提升到整个作用域的最 ...
- MySQL Lock--MySQL INSERT加锁学习
准备测试数据: ## 开启InnoDB Monitor SET GLOBAL innodb_status_output=ON; SET GLOBAL innodb_status_output_lock ...
- Hive使用过程中踩过的坑
hive启动时错误1 Cannot execute statement:impossible to write to binary long since BINLOG_FORMAT = STATEME ...
- 安装lamp服务器
1.安装http: $ yum install httpd 2.启动http: $ systemctl start httpd 3.访问:http://192.168.1.100 4.Installi ...
- php将原数组倒序array_reverse()
1.数组倒序排列 $arr = array(1,2,3); $arr = array_reverse($arr); print_r($arr);