(转载)ranger原理
文章目录
一、业务背景
大数据集群最基本的就是数据以及用于计算的资源,是一个公司的宝贵财富,我们需要将它们很好管理起来,将相应的数据和资源开放给对应的用户使用,防止被窃取、被破坏等,这就涉及到大数据安全。
现状&&需求
目前我们大数据集群的现状是处于裸奔状态,只要可以登录linux机器即可对集群继续相关操作
所以集群安全对于我们来说迫在眉睫,主要需求有以下几个方面:
- 支持多组件,最好能支持当前公司技术栈的主要组件,HDFS、HBASE、HIVE、YARN、STORM、KAFKA等
- 支持细粒度的权限控制,可以达到HIVE列,HDFS目录,HBASE列,YARN队列,STORM拓扑,KAKFA的TOPIC
- 开源,社区活跃,按照现有的集群改情况造改动尽可能的小,而且要符合业界的趋势。
二、大数据安全组件介绍与对比
目前比较常见的安全方案主要有三种:
- Kerberos(业界比较常用的方案)
- Apache Sentry(Cloudera选用的方案,cdh版本中集成)
- Apache Ranger(Hortonworks选用的方案,hdp发行版中集成)
1、Kerberos
Kerberos是一种基于对称密钥的身份认证协议,它作为一个独立的第三方的身份认证服务,可以为其它服务提供身份认证功能,且支持SSO(即客户端身份认证后,可以访问多个服务如HBase/HDFS等)。
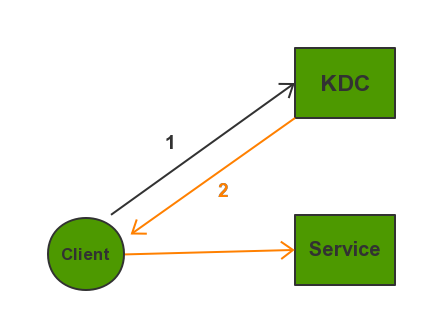
| 服务名 | 作用 |
|---|---|
| KDC | Kerberos的服务端程序,用于验证各个模块 |
| Client | 需要访问服务的用户,KDC和Service会对用户的身份进行认证 |
| Service | 即集成了Kerberos的服务,如HDFS/YARN/HBase等 |
Kerberos协议过程主要有三个阶段,第一个阶段Client向KDC申请TGT,第二阶段Client通过获得的TGT向KDC申请用于访问Service的Ticket,第三个阶段是Client用返回的Ticket访问Service。
优点:
服务认证,防止broker datanode regionserver等组件冒充加入集群
解决了服务端到服务端的认证,也解决了客户端到服务端的认证
缺点:
kerberos为了安全性使用临时ticket,认证信息会失效,用户多的情况下重新认证繁琐
kerberos只能控制你访问或者拒绝访问一个服务,不能控制到很细的粒度,比如hdfs的某一个路径,hive的某一个表,对用户级别上的认证并没有实现(需要配合LDAP)
2、Apache Sentry
Apache Sentry是Cloudera公司发布的一个Hadoop安全开源组件,它提供了细粒度级、基于角色的授权.

优点:
Sentry支持细粒度的hdfs元数据访问控制,对hive支持列级别的访问控制
Sentry通过基于角色的授权简化了管理,将访问同一数据集的不同特权级别授予多个角色
Sentry提供了一个统一平台方便管理
Sentry支持集成Kerberos
缺点:
- 组件只支持hive,hdfs,impala 不支持hbase,yarn,kafka,storm等
3、Apache Ranger
Apache Ranger是Hortonworks公司发布的一个Hadoop安全组件开源组件
优点:
- 提供了细粒度级(hive列级别)
- 基于访问策略的权限模型
- 权限控制插件式,统一方便的策略管理
- 支持审计日志,可以记录各种操作的审计日志,提供统一的查询接口和界面
- 丰富的组件支持(HDFS,HBASE,HIVE,YARN,KAFKA,STORM)
- 支持和kerberos的集成
- 提供了Rest接口供二次开发
4、为什么我们选择Ranger
- 多组件支持(HDFS,HBASE,HIVE,YARN,KAFKA,STORM),基本覆盖我们现有技术栈的组件
- 支持审计日志,可以很好的查找到哪个用户在哪台机器上提交的任务明细,方便问题排查反馈
- 拥有自己的用户体系,可以去除kerberos用户体系,方便和其他系统集成,同时提供各类接口可以调用
综上:我们考虑到和开放平台的集成,以及我们的技术栈和集群操作的审计等几个问题最终选用了apache ranger
三、Apache Ranger系统架构及实践
1、架构介绍

2、组件介绍
- RangerAdmin
以RESTFUL形式提供策略的增删改查接口,同时内置一个Web管理页面。
- Service Plugin
嵌入到各系统执行流程中,定期从RangerAdmin拉取策略,根据策略执行访问决策树,并且记录访问审计
| 插件名称 | 安装节点 |
|---|---|
| Hdfs-Plugin | NameNode |
| Hbase-Plugin | HMaster+HRegionServer |
| Hive-Plugin | HiveServer2 |
| Yarn-Plugin | ResourceManager |
- Ranger-SDK
对接开放平台,实现对用户、组、策略的管理
3、权限模型
访问权限无非是定义了”用户-资源-权限“这三者间的关系,Ranger基于策略来抽象这种关系,进而延伸出自己的权限模型。”用户-资源-权限”的含义详解:
用户
由User或Group来表达,User代表访问资源的用户,Group代表用户所属的用户组。
资源
不同的组件对应的业务资源是不一样的,比如
- HDFS的FilePath
- HBase的Table,Column-family,Column
- Hive的Database,Table,Column
- Yarn的对应的是Queue
权限
由(AllowACL, DenyACL)来表达,类似白名单和黑名单机制,AllowACL用来描述允许访问的情况,DenyACL用来描述拒绝访问的情况,不同的组件对应的权限也是不一样的。
| 插件 | 权限项 |
|---|---|
| Hdfs | Read Write Execute |
| Hbase | Read Write Create Admin |
| Hive | Select Create Update Drop Alter Index Lock Read Write All |
| Yarn | submit-app admin-queue |
4、权限实现
Ranger-Admin职责:
- 管理员对于各服务策略进行规划,分配相应的资源给相应的用户或组,存储在db中
Service Plugin职责:
- 定期从RangerAdmin拉取策略
- 根据策略执行访问决策树
- 实时记录访问审计
策略执行过程:
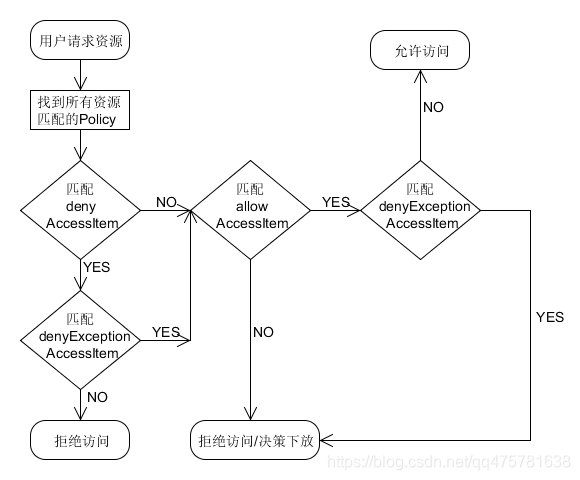
策略优先级:
- 黑名单优先级高于白名单
- 黑名单排除优先级高于黑名单
- 白名单排除优先级高于白名单
决策下放:
如果没有policy能决策访问,一般情况是认为没有权限拒绝访问,然而Ranger还可以选择将决策下放给系统自身的访问控制层
组件集成插件原理:
| Service | Extensible Interface | Ranger Implement Class |
|---|---|---|
| HDFS | org.apache.hadoop.hdfs.server.namenode.INodeAttributeProvider | org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer |
| HBASE | org.apache.hadoop.hbase.protobuf.generated.AccessControlProtos.AccessControlService.Interface | org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor |
| Hive | org.apache.hadoop.hive.ql.security.authorization.plugin.HiveAuthorizerFactory | org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory |
| YARN | org.apache.hadoop.yarn.security.YarnAuthorizationProvider | org.apache.ranger.authorization.yarn.authorizer.RangerYarnAuthorizer |
ranger通过实现各组件扩展的权限接口,进行权限验证
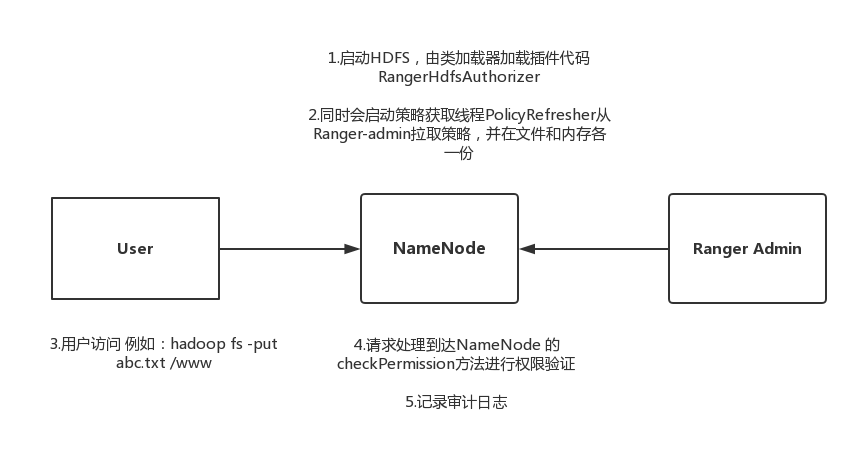
Hdfs实现原理
hdfs-site.xml会修改如下配置:
<property>
<name>dfs.permissions.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.inode.attributes.provider.class</name>
<value>org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
加载过程:
Hbase实现原理
在安装完hbase插件后,hbase-site.xml会修改如下配置:
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
加载过程:

Hive实现原理
hiveserver2-site.xml
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
加载过程:

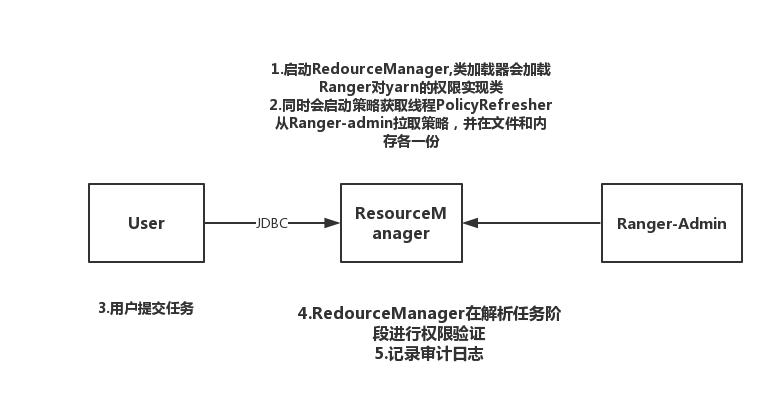
Yarn实现原理
yarn-site.xml
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.authorization-provider</name>
<value>org.apache.ranger.authorization.yarn.authorizer.RangerYarnAuthorizer</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
加载过程:
四、Ranger实践
1、组权限实现
由于在调用各服务过程中使用hdfs shell、hbase-shell、hive-jdbc只能获取到用户信息,在只有组策略时会匹配不成功,认为没有权限,实现办法是加入ldap组件同步用户组信息,这样增加了系统的复杂性,我们通过改写ranger-admin代码,在客户端plugin获取策略时,将组权限赋予用户,这样就实现了组策略功能。
原文:https://blog.csdn.net/qq475781638/article/details/90247153#Hive_227
(转载)ranger原理的更多相关文章
- [转载]SSD原理与实现
[转载]SSD原理与实现 这里只mark一下,对原论文讲解的很好的博文 https://zhuanlan.zhihu.com/p/33544892 这里有一个关于SSD的很好的程序实现,readme里 ...
- [转载] Thrift原理简析(JAVA)
转载自http://shift-alt-ctrl.iteye.com/blog/1987416 Apache Thrift是一个跨语言的服务框架,本质上为RPC,同时具有序列化.发序列化机制:当我们开 ...
- [转载] ConcurrentHashMap原理分析
转载自http://blog.csdn.net/liuzhengkang/article/details/2916620 集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的 ...
- [转载]NGINX原理分析 之 SLAB分配机制
作者:邹祁峰 邮箱:Qifeng.zou.job@hotmail.com 博客:http://blog.csdn.net/qifengzou 日期:2013.09.15 23:19 转载请注明来自&q ...
- (转载)ConcurrentHashMap 原理
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区 (Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章 ...
- [转载] ZooKeeper原理及使用
转载自http://www.wuzesheng.com/?p=2609 ZooKeeper是Hadoop Ecosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordina ...
- [转载] kprobe原理解析(一)
From: https://www.cnblogs.com/honpey/p/4575928.html kprobe原理解析(一) kprobe是linux内核的一个重要特性,是一个轻量级的内核调试工 ...
- [转载]Redux原理(一):Store实现分析
写在前面 写React也有段时间了,一直也是用Redux管理数据流,最近正好有时间分析下源码,一方面希望对Redux有一些理论上的认识:另一方面也学习下框架编程的思维方式. Redux如何管理stat ...
- 转载--httpclient原理和应用
https://blog.csdn.net/wangpeng047/article/details/19624529/ 多谢大神的分享
随机推荐
- form表单提交数据给后台
1.完整登录示例 1. form表单往后端提交数据注意三点 1.所有获取用户输入标签都应该放在form表单里面 2.action属性控制往哪儿提交,method一般都是设置成post 3.提交按钮必须 ...
- Mybatis中使用collection进行多对多双向关联示例(含XML版与注解版)
Mybatis中使用collection进行多对多双向关联示例(含XML版与注解版) XML版本: 实体类: @Data @NoArgsConstructor public class Course ...
- Python基础知识(五)------字典
Python基础知识(四)------字典 字典 一丶什么是字典 dict关键字 , 以 {} 表示, 以key:value形式保存数据 ,每个逗号分隔 键: 必须是可哈希,(不可变的数据类型 ...
- Python的bytes和str
Python和C的字符串 在Python 3 中,bytes单独作为一个类型,不再和str类型混在一起.关于字符串和字节,我想先回顾下C/C++ 在C/C++中,字符串是由char数组构成,每个元素是 ...
- nodeJS从入门到进阶三(MongoDB数据库)
一.MongoDB数据库 1.概念 数据库(DataBase)是一个按照数据结构进行数据的组织,管理,存放数据的仓库. 2.关系型数据库 按照关系模型存储的数据库,数据与数据之间的关系非常密切,可以实 ...
- 使用MUI框架实现JQ购物车增减
// 购物车数量减少$('.reduce').click(function () { addMinus(this,0)}); // 购物车数量增加$('.increase').click(functi ...
- MySQL Replication--中继日志更新
RELAY LOG相关参数 设置如何保存从节点接收到的主库BINLOG sync_relay_log : 设置如何同步中继日志到中继日志文件. 当sync_relay_log = 0时,则MySQL服 ...
- wget详解
wget命令用来从指定的URL下载文件.wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕.如果是服务器打断下 ...
- NGINX并发量优化
NGINX并发量优化 一.压力测试 命令:ab -c 2000 -n 2000 web服务器的地址 ab:压力测试工具 -c:client缩写,客户端的数量 -n:总的访问量,所有客户端总共的访问量. ...
- python的tkinter,能画什么图?
今天从下午忙到现在,睡觉. 这个能绘点图的. import json import tkinter as tk from tkinter import filedialog from tkinter ...