EFK收集nginx日志
准备三台centos7的服务器 两核两G的
关闭防火墙和SELinux
systemctl stop firewalld
setenforce 0rpm -ivh jdk-8u131-linux-x64_.rpm
准备中... ################################# [%]
正在升级/安装...
:jdk1..0_131-:1.8.0_131-fcs ################################# [%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar... java -version //执行这条命令可以看到jdk的版本 就是jdk环境配置成功
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) -Bit Server VM (build 25.131-b11, mixed mode)
2. 因为我装的是无图形化界面的centos 每一台虚拟机都需要
yum -y install wget
cd /usr/local/src
##这个下载的是zookeeper
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
##这个下载的是kafka
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.0/kafka_2.11-2.2.0.tgz
3. 解压zookeeper 然后移动到/usr/local/zookeeper kafka做同样的操作 kafka移动到/usr/local/kafka
tar -zxf zookeeper-3.4..tar.gz
mv zookeeper-3.4. /usr/local/zookeeper
tar -zxf kafka_2.-2.2..tgz
mv kafka_2.-2.2. /usr/local/kafka
4.在 /usr/local/zookeeper创建两个目录 zkdatalog zkdata
cd /usr/local/zookeeper
mkdir {zkdatalog,zkdata}
5.进入/usr/loca/zookeeper/conf 复制一个配置文件 修改复制出来的配置文件
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
*******************************
tickTime=
initLimit=
syncLimit=
dataDir=/usr/local/zookeeper/zkdata
datalogDir=/usr/local/zookeeper/zkdatalog
clientPort=
server.=192.168.18.140::
server.=192.168.18.141::
server.=192.168.18.142::
*******************************
6. 每一台的操作都不一样
第一台
echo '' > /usr/local/zookeeper/zkdata/myid
第二台
echo '' > /usr/local/zookeeper/zkdata/myid
第三胎
echo '' > /usr/local/zookeeper/zkdata/myid
7.启动服务 启动的时候按顺序开启 第一台 第二台 第三台
cd /usr/local/zookeeper/bin
./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
8.查看是否开启 zookpeer 的状态
第一台 显示这个状态表示成功
./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower 第二台
./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: leader 第三台
./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
搭建kafka
第一台
cd /usr/local/kafka/config
vim server.properties
*********************
broker.id=
advertised.listeners=PLAINTEXT://kafka01:9092
zookeeper.connect=192.168.18.140:,192.168.18.141:,192.168.18.142: (三台服务器的IP地址) 第2台
cd /usr/local/kafka/config
vim server.properties
*********************
broker.id=
advertised.listeners=PLAINTEXT://kafka02:9092
zookeeper.connect=192.168.18.140:,192.168.18.141:,192.168.18.142: (三台服务器的IP地址) 第3台
cd /usr/local/kafka/config
vim server.properties
*********************
broker.id=
advertised.listeners=PLAINTEXT://kafka03:9092
zookeeper.connect=192.168.18.140:,192.168.18.141:,192.168.18.142: (三台服务器的IP地址)
10.vim /etc/hosts
添加以下内容在每一台服务器上
192.168.18.140 kafka01
192.168.18.141 kafka02
192.168.18.142 kafka03
11.启动kafka的命令 每一台都启动kafka
cd /usr/local/kafka/bin
./kafka-server-start.sh -daemon ../config/server.properties
启动之后可以查看端口9092
ss -ntlp | grep
12.创建主题 topics
cd /usr/local/kafka/bin
./kafka-topics.sh --create --zookeeper 192.168.18.140:(这个ip地址随便写三台服务器中的一个就可以)--replication-factor --partitions --topic wg007
查看主题 如果可以显示刚刚创建的就是成功了
cd /usr/local/kafka/bin
./kafka-topics.sh --list --zookeeper 192.168.18.140:
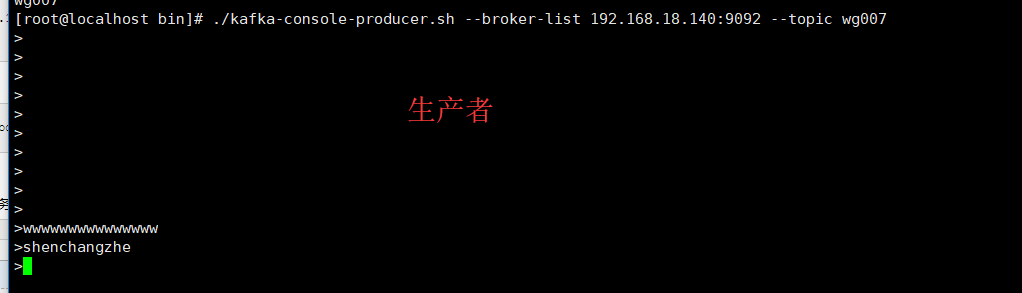
模拟生产者 执行代码后就会有一个小的 >
cd /usr/local/kafka/bin
./kafka-console-producer.sh --broker-list 192.168.18.140: --topic wg007
>
在第二台服务器上模拟消费者
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.18.141: --topic wg007 --from-beginning
测试模拟生产者和消费者是否成功
在模拟生产者的服务器上写一些东西 可以在模拟消费者的服务器上可以看到表示成功如下所示

写一个脚本用来创建kafka的topic
cd /usr/local/kafka/bin
vim kafka-create-topics.sh
#################################
#!/bin/bash
read -p "请输入一个你想要创建的topic:" topic
cd /usr/local/kafka/bin
./kafka-topics.sh --create --zookeeper 192.168.18.140: --replication-factor --partitions --topic ${topic}
创建一个新的yum源
vim /etc/yum.repo.d/filebeat.repo
***加入以下内容
[filebeat-.x]
name=Elasticsearch repository for .x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=
autorefresh=
type=rpm-md
安装
yum -y install filebeat
编辑filebeat的配置文件
cd /etc/filebeat
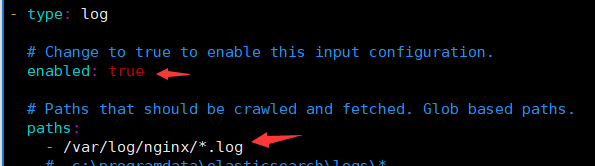
vim filebeat.yml
修改以下内容 enabled: true paths:
- /var/log/nginx/*.log //写这个路径的前提是安装nginx output.kafka:
enabled: true
# Array of hosts to connect to.
hosts: ["192.168.18.140:9092","192.168.18.141:9092","192.168.18.142:9092"]
topic: nginx5 //写这个nginx_log1 的前提是有nginx_log1的topic 上面有生产者的脚本
安装nginx
yum -y install epel*
yum -y install nginx
启动nginx和filebeat
systemctl start filebeat
systemctl enable filebeat
systemctl start nginx
可以给ningx生产一些数据
yum -y install httpd-tools
ab -n1000 -c http://127.0.0.1/cccc //这条命令可以多执行几次
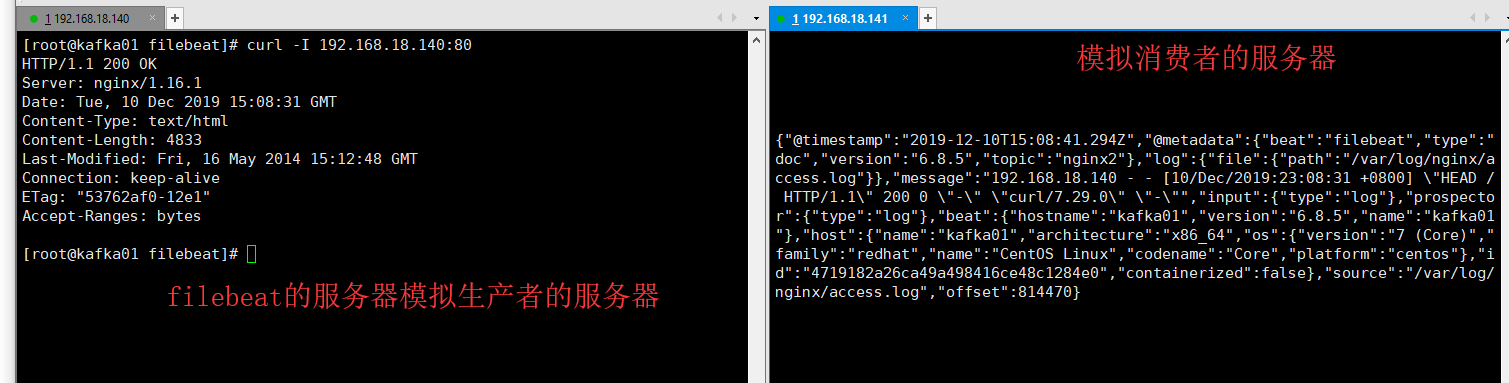
可以在安装filebeat的服务器上测试一下nginx的服务
curl -I 192.168.18.140:
在模拟消费者的服务器上 如果可以显示一下内容 表示成功了
cd /usr/local/kafka/bin ./kafka-console-consumer.sh --bootstrap-server 192.168.18.141: --topic nginx5(这里的topic的名字一定要和filebeat的配置文件里的一致) --from-beginning
如图所示
现在开始收集多个日志 system nginx secure 和日志 编辑filebeat的配置文件
#讲filebeat的input改成下面的样子 filebeat.inputs:
#这个是收集nginx的日志
- type: log
enabled: true
paths:
- /var/log/nginx/*.log //nginx的日志文件
fields:
log_topics: nginx5 //这个是收集nginx的topic #这个是收集system的日志
- type: log
enabled: true
paths:
- /var/log/messages //system的日志文件目录
fields:
log_topics: messages //这个是收集system的topic #收集secure的日志
- type: log
enabled: true
paths:
- /var/log/secure //secure的日志文件
fields:
log_topics: secure //这个是收集secure的topic output.kafka:
enabled: true
hosts: ["192.168.18.140:9092","192.168.18.141:9092","192.168.18.142:9092"]
topic: '%{[fields][log_topics]}'
注意:一点更要创建三个topic 就是上面的配置文件提到的topic 可以使用上面的脚本创建topic 重启filebeat
systemctl restart filebeat
我是用了三台服务器来做EFK集群
接下来在第二胎安装logstash 在第三胎安装ES集群(就是elasticsearch和kibana)
安装
安装logstash在第二台
rpm -ivh logstash-6.6..rpm
安装 kibana 和elasticsearch
rpm -ivh elasticsearch-6.6..rpm
rpm -ivh kibana-6.6.-x86_64.rpm
编辑elasticsearch的配置文件
vim /etc/elasticsearch/elasticsearch.yml
############################
network.host: 192.168.18.142
http.port:
启动elasticsearch
systemctl restart elasticsearch
编辑kibana的配置文件
vim /etc/kibana/kibana.yml
######################
server.port:
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.18.142:9200"] 然后启动kibana
systemctl restart kibana
现在开始 编写logstash的三个配置文件
cd /etc/logstash/conf.d
现在是messages的 vim messages.conf
input {
kafka {
bootstrap_servers => ["192.168.18.140:9092,192.168.18.141:9092,192.168.18.142:9092"]
group_id => "logstash"
topics => "messages"
consumer_threads =>
}
}
output {
elasticsearch {
hosts => "192.168.18.142:9200"
index => "messages-%{+YYYY.MM.dd}"
}
}
现在是nginx的 vim nginx.conf
input {
kafka {
bootstrap_servers => ["192.168.18.140:9092,192.168.18.141:9092,192.168.18.142:9092"]
group_id => "logstash"
topics => "nginx5"
consumer_threads =>
}
}
filter {
grok {
match => { "message" => "%{NGINXACCESS}" }
}
}
output {
elasticsearch {
hosts => "192.168.18.142:9200"
index => "nginx1_log-%{+YYYY.MM.dd}"
}
}
现在是secure的 vim secure.conf
input {
kafka {
bootstrap_servers => ["192.168.18.140:9092,192.168.18.141:9092,192.168.18.142:9092"]
group_id => "logstash"
topics => "secure"
consumer_threads =>
}
}
output {
elasticsearch {
hosts => "192.168.18.142:9200"
index => "secure-%{+YYYY.MM.dd}"
}
}
添加管道
vim /etc/logstash/pipelines.yml - pipeline.id: messages
path.config: "/etc/logstash/conf.d/messages.conf"
- pipeline.id: nginx
path.config: "/etc/logstash/conf.d/nginx.conf"
- pipeline.id: secure
path.config: "/etc/logstash/conf.d/secure.conf"
正则匹配
cd /usr/share/logstash/vendor/bundle/jruby/2.3./gems/logstash-patterns-core-4.1./patterns
vim nginx_access
URIPARAM1 [A-Za-z0-$.+!*'|(){},~@#%&/=:;_?\-\[\]]*
NGINXACCESS %{IPORHOST:client_ip} (%{USER:ident}|- ) (%{USER:auth}|-) \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} (%{NOTSPACE:request}|-)(?: HTTP/%{NUMBER:http_version})?|-)" %{NUMBER:status} (?:%{NUMBER:bytes}|-) "(?:%{URI:referrer}|-)" "%{GREEDYDATA:agent}"
重启logstash systemctl restart logstash
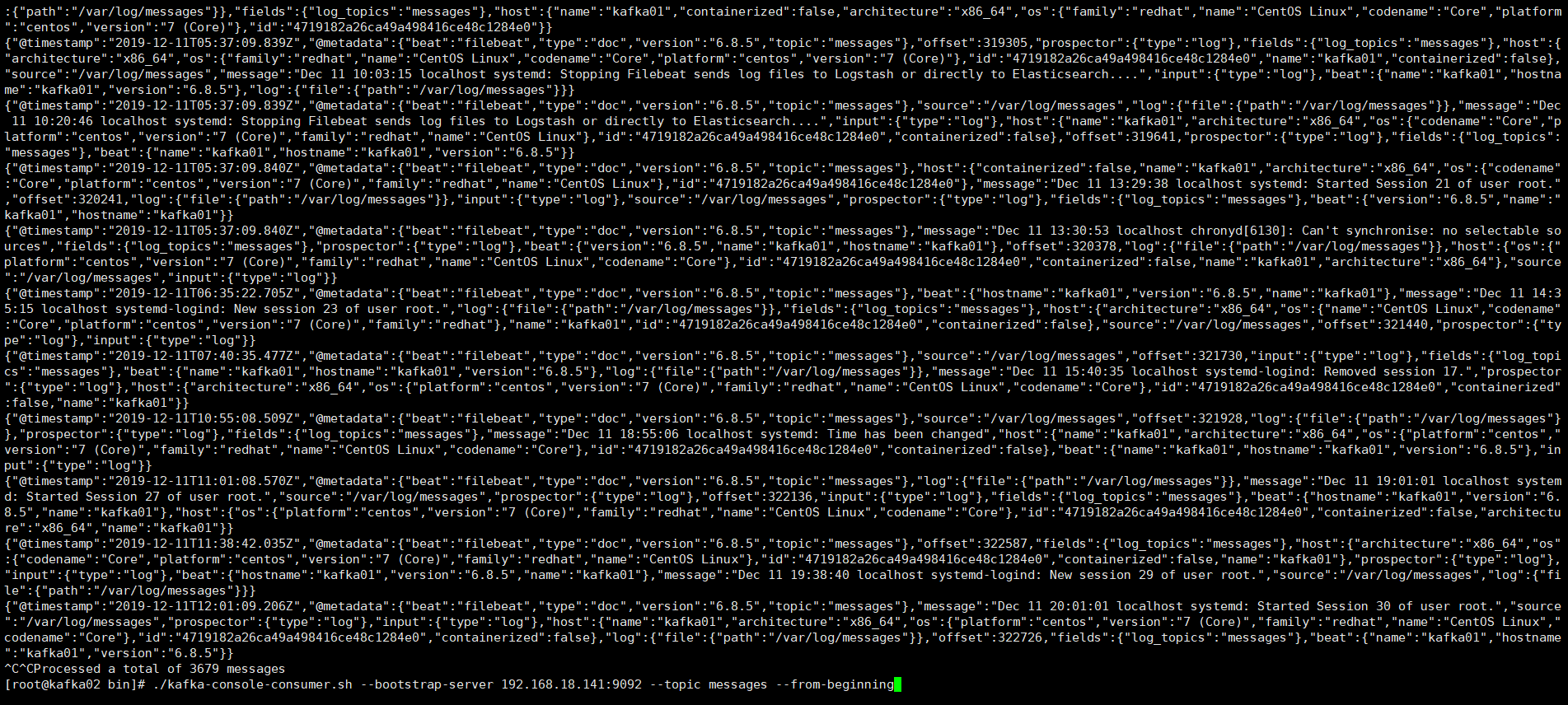
可以在第二台机器上查看模拟消费者的状态 messages的
执行下面的命令可以显示出日志内容就是成功
cd /usr/local/kafak/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.18.141: --topic messages --from-beginning<br><br>
可以在第二台机器上查看模拟消费者的状态 secure的
执行下面的命令可以显示出日志内容就是成功
cd /usr/local/kafak/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.18.141: --topic secure --from-beginning

可以在第二台机器上查看模拟消费者的状态 nginx的 nginx的可以生产一些日志文件 创建一些访问记录
执行下面的命令可以显示出日志内容就是成功
cd /usr/local/kafak/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.18.141: --topic nginx5 --from-beginning
EFK收集nginx日志的更多相关文章
- ELK Stack (2) —— ELK + Redis收集Nginx日志
ELK Stack (2) -- ELK + Redis收集Nginx日志 摘要 使用Elasticsearch.Logstash.Kibana与Redis(作为缓冲区)对Nginx日志进行收集 版本 ...
- ELK filter过滤器来收集Nginx日志
前面已经有ELK-Redis的安装,此处只讲在不改变日志格式的情况下收集Nginx日志. 1.Nginx端的日志格式设置如下: log_format access '$remote_addr - $r ...
- ELK日志系统之使用Rsyslog快速方便的收集Nginx日志
常规的日志收集方案中Client端都需要额外安装一个Agent来收集日志,例如logstash.filebeat等,额外的程序也就意味着环境的复杂,资源的占用,有没有一种方式是不需要额外安装程序就能实 ...
- 安装logstash5.4.1,并使用grok表达式收集nginx日志
关于收集日志的方式,最简单性能最好的应该是修改nginx的日志存储格式为json,然后直接采集就可以了. 但是实际上会有一个问题,就是如果你之前有很多旧的日志需要全部导入elk上查看,这时就有两个问题 ...
- ELK 二进制安装并收集nginx日志
对于日志来说,最常见的需求就是收集.存储.查询.展示,开源社区正好有相对应的开源项目:logstash(收集).elasticsearch(存储+搜索).kibana(展示),我们将这三个组合起来的技 ...
- 第七章·Logstash深入-收集NGINX日志
1.NGINX安装配置 源码安装nginx 因为资源问题,我们先将nginx安装在Logstash所在机器 #安装nginx依赖包 [root@elkstack03 ~]# yum install - ...
- ELASTIC 5.2部署并收集nginx日志
elastic 5.2集群安装笔记 设计架构如下: nginx_json_log ->filebeat ->logstash ->elasticsearch ->kiban ...
- rsyslog收集nginx日志配置
rsyslog日志收集配置 rsyslog服务器收集各服务器的日志,并汇总,再由logstash处理 请查看上一篇文章 http://bbotte.blog.51cto.com/6205307/16 ...
- Docker 部署 ELK 收集 Nginx 日志
一.简介 1.核心组成 ELK由Elasticsearch.Logstash和Kibana三部分组件组成: Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引 ...
随机推荐
- SpringBoot使用@ServerEndpoint无法依赖注入问题解决(WebSocket)
如上两图所示,在WebSocket中我想使用Redis.把自己编写的RedisUtil使用@Autowired自动注入到当前类. 在运行时,出现异常:java.lang.NullPointExcept ...
- Java使用正则表达式匹配多行 Pattern flags
Java中正则匹配有多种模式,若不选择模式则默认为单行匹配 匹配模式(Pattern flags) compile()方法有两个模式 未开匹配模式 Pattern compile(String reg ...
- linux下僵尸进程的发现与处理
一.概述 僵尸进程是怎么产生的 当子进程退出时,父进程没有调用wait函数或者waitpid()函数等待子进程结束,又没有显式忽略SIGCHLD信号,那么它将一直保持在僵尸状态,如果这时父进程结束了, ...
- k8s-Label(标签)
k8s-Label(标签) 一.Label是什么? Label是Kubernetes系统中的一个核心概念.Label以key/value键值对的形式附加到各种对象上,如Pod.Service.RC.N ...
- 尝试 WebAssembly
wasm 为浏览器应用开辟了一个全新的领域.意义非凡,并不是一句两句说的清的,今天正好有点空做些实验. 1. emsdk 的安装 Emscripten 可以直接将 C/C++ 编译为 wasm,让用 ...
- Oracle For Linux 恢复日记 霆智X8III
公司最近的客户需要在LINUX系统中做数据迁移,备份出来的内容数据库物理文件,回档日志和SpfileXXXX 客户用的是北京霆智的X8备份阵列,X8与数据库服务器都放在IDC机所,IDC机房与客户之间 ...
- Excel导出,添加有效性
#region 添加有效性 DataTable dt = LAbll.LogisticsAccounts(DeptId); //查数据 if (dt.Rows.Count < 20) //有效 ...
- js 时间格式化成字符串
我用的简单的直接的字符串格式转化 function getTimeStr() { var date = new Date(); var year = date.getFullYear(); var m ...
- 2019 边锋游戏java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.边锋游戏等公司offer,岗位是Java后端开发,因为发展原因最终选择去了边锋游戏,入职一年时间了,也成为了面 ...
- JavaScript 之 RegExp 对象
RegExp 正则表达式对象 一.正则表达式 正则表达式:定义字符串的组成规则. 1.单个字符:[ ] 如:[a].[ab].[a-zA-Z0-9] 特殊符号代表特殊含义的单个字符: \d:单个数字字 ...