[原创]python爬虫之BeautifulSoup,爬取网页上所有图片标题并存储到本地文件
from bs4 import BeautifulSoup
import requests
import re
import os
r = requests.get("https://re.jd.com/search?keyword=%E6%B0%B4%E6%9E%9C%20%E7%BD%91&keywordid=44195495794&re_dcp=202m0QjIIg==&traffic_source=1004&test=1&enc=utf8&cu=true&utm_source=baidu-search&utm_medium=cpc&utm_campaign=t_262767352_baidusearch&utm_term=44195495794_0_32d58cbc7f0f40e08d64a09fbc8c95c4")
result = r.content
# print(result)
soup = BeautifulSoup(result,"html.parser")
# print(soup.script.text)
souptext = soup.find(type='text/javascript').text
# print(souptext) pattern3 =re.compile(r'\"ad_title_text\":\"(.*?\"),\"image_url\":\"(.*?\.(jpg|png))\"')
patternresult3 = pattern3.findall(souptext)
print(patternresult3) j = 0
for i in patternresult3:
j = j+1
title = i[0].replace(' ','').replace('\"','').replace('/','')
with open(os.getcwd()+'\\jpg\\'+title+str(j)+"."+i[2],"wb") as f: #在执行代码前,需要先创建一个jpg的目录,os.getcwd()用来获取当前目录
f.write(requests.get("https://img1.360buyimg.com/n6/"+i[1]).content)
运行结果如下:
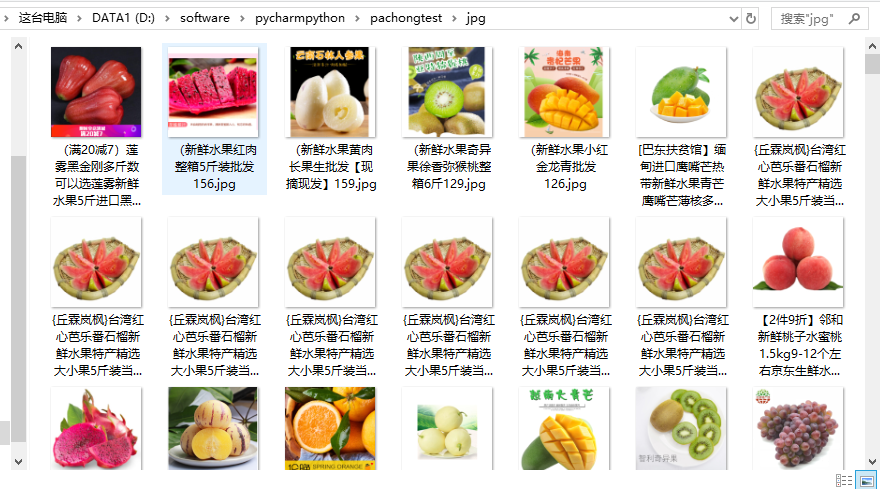
[原创]python爬虫之BeautifulSoup,爬取网页上所有图片标题并存储到本地文件的更多相关文章
- python 爬虫 requests+BeautifulSoup 爬取巨潮资讯公司概况代码实例
第一次写一个算是比较完整的爬虫,自我感觉极差啊,代码low,效率差,也没有保存到本地文件或者数据库,强行使用了一波多线程导致数据顺序发生了变化... 贴在这里,引以为戒吧. # -*- coding: ...
- 原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我 注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的. 爬虫 ...
- 原创:Python爬虫实战之爬取代理ip
编程的快乐只有在运行成功的那一刻才知道QAQ 目标网站:https://www.kuaidaili.com/free/inha/ #若有侵权请联系我 因为上面的代理都是http的所以没写这个判断 代 ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- logistic 回归(线性和非线性)
一:线性logistic 回归 代码如下: import numpy as np import pandas as pd import matplotlib.pyplot as plt import ...
- 炫酷的CSS3响应式表单
原创YouTube@ Online Tutorials css代码: * { margin: 0; padding: 0; box-sizing: border-box; font-family: ' ...
- 《CarbonData》
深度访谈:华为开源数据格式 CarbonData 项目,实现大数据即席查询秒级响应 Tina 阅读数:145842016 年 7 月 13 日 19:00 华为宣布开源了 CarbonDa ...
- java自定义词典使用Hanlp
一开始按照网上的方法在配置文件加入自定义的词典不行,不知道是什么问题,这里给出链接,有兴趣的自己尝试:https://my.oschina.net/u/3793864/blog/3073171 说一下 ...
- luoguP2178 [NOI2015]品酒大会(后缀自动机)
题意 承接上篇题解 考虑两个后缀的\(lcp\)是什么,是将串反着插入后缀自动机后两个前缀(终止节点)的\(lca\)!!!于是可以在parent tree上DP了. 比后缀数组又简单又好写跑的还快. ...
- CentOS7 中创建 Django 项目
1. (新建文件夹用于存放项目)进入指定文件夹,创建Django项目 django-admin.py startproject mysite mysite 为项目名称 2. 进入项目文件夹,新建app ...
- java创建泛型的实例
如果存在泛型 T ,要创建它的实例,以下方式行不通 public class xxx { privaye E[] data ; public xxx() { data = new E[10] ; } ...
- 阿里Sentinel支持Spring Cloud Gateway啦
1. 前言 4月25号,Sentinel 1.6.0 正式发布,带来 Spring Cloud Gateway 支持.控制台登录功能.改进的热点限流和注解 fallback 等多项新特性,该出手时就出 ...
- 解惑:如何使得寝室的电脑和实验室的电脑远程相互访问(Linux和Windows)
解惑:如何使得寝室的电脑和实验室的电脑远程相互访问 一.前言 自从接触计算机网络之后就一直想着把实验室的电脑和自己寝室的电脑远程连接起来,结果总是郁郁不能成功,网上这样的教材也少的可怜,于是总是搁置下 ...
- git 给分支添加描述 管理分支实用方法
1.背景 在我们工作中,正常情况我们处在一个迭代中,一个人最多会有几个功能,比较正常的操作我们会给每个大功能创建不同的分支,方便管理. 我们可以非常愉快的进行版本管理,遇到特殊情况我们也可以方便版本退 ...