加速JDBC的快捷方法
JAVA 应用必须通过 JDBC 从数据库中取数,有时候我们会发现,数据库的负担一点也不重而且 SQL 很简单,但取数的速度仍然很慢。仔细测试会发现,性能瓶颈主要在 JDBC 上,比如 MySQL 的 JDBC 性能就非常差,Oracle 也不好。但是,JDBC 是数据库厂商提供的包,我们在外部没办法提高性能。
可以想到的办法是利用多 CPU 手段采用并行方案来提速,但 Java 的并行程序非常难写,要考虑资源共享冲突等麻烦事务。
下面介绍使用集算器的并行技术来提升数据库 JDBC 取数性能,可以避免 JAVA 硬编码的复杂性,还能够方便实现多线程结果集的合并。适用于:
- 源数据规模较大的查询报表
- 多数据集报表
- ETL 数据抽取
集算器并行配置
通过集算器进行并行取数前需要配置集算器的并行属性。IDE 中通过菜单“工具 - 选项”设置 IDE 支持的最大并行数量,一般建议最大并行数不要超过 CPU 核数。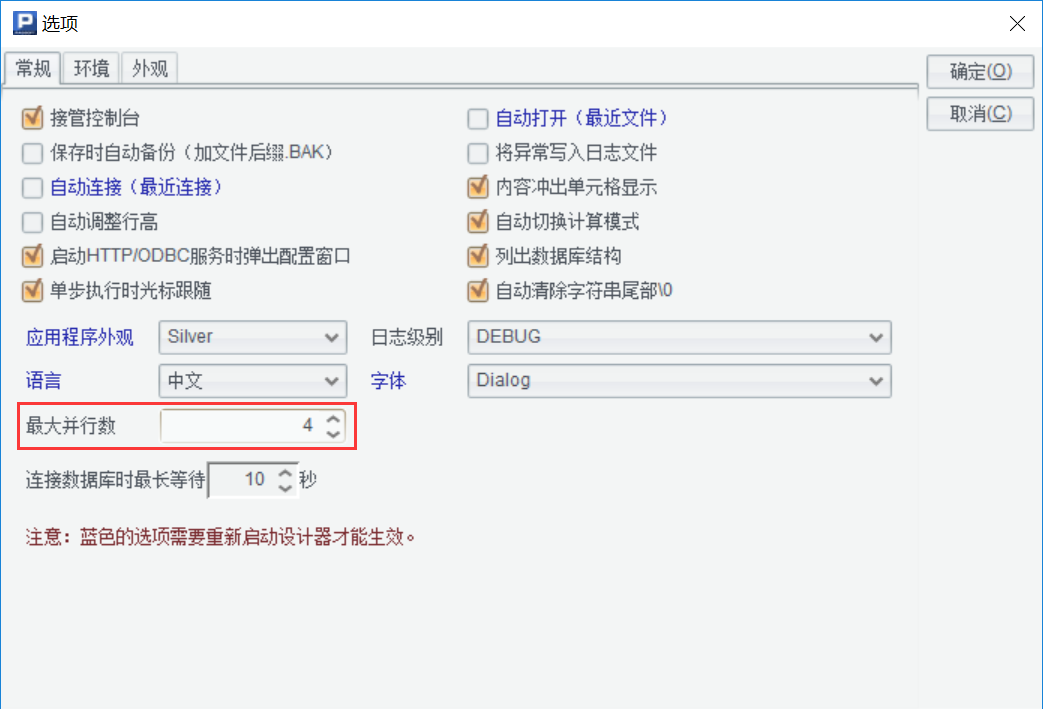
集算器服务端则需要修改 raqsoftConfig.xml 配置: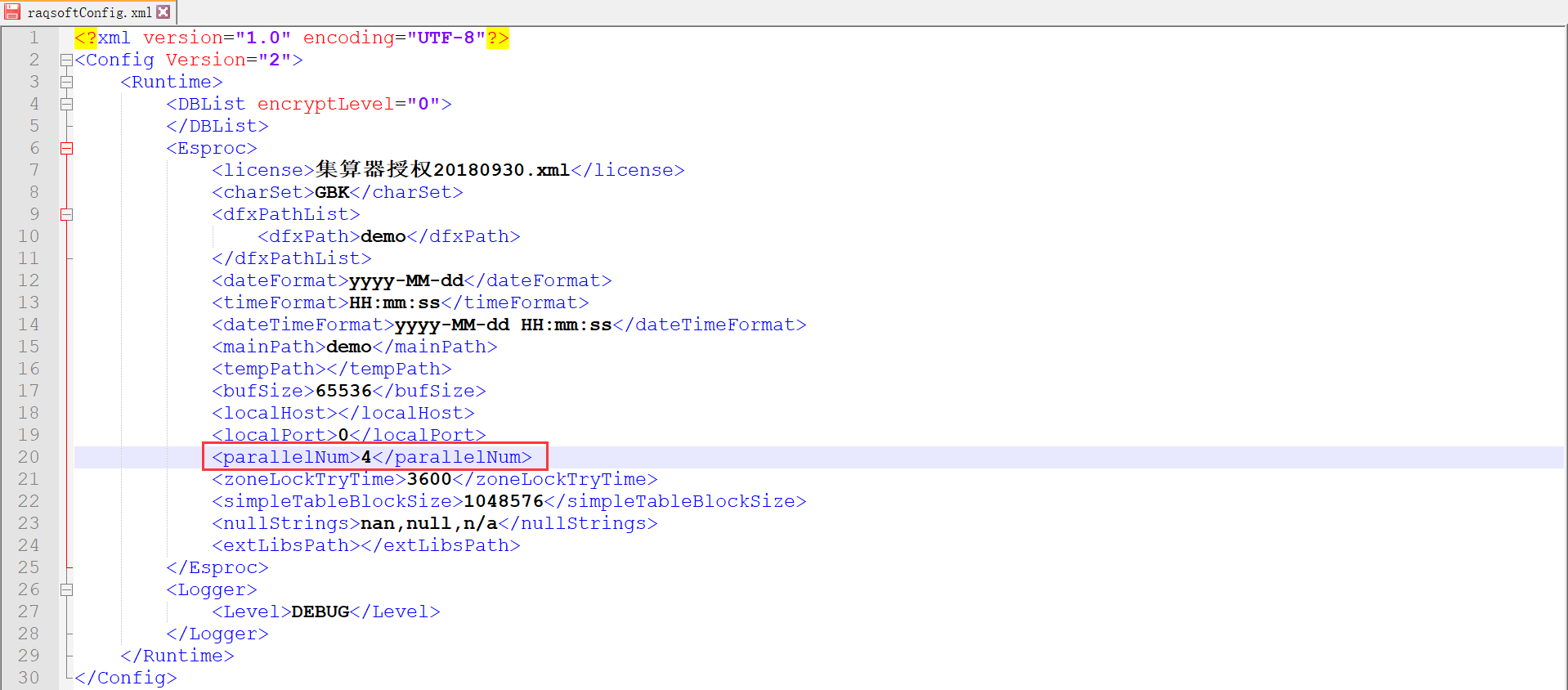
单表并行取数
有时我们查询的某个表数据量较大、时间较长,这时就可以通过集算器针对单表并行取数提升性能。这里所谓的单表是指通过条件并行读取一份(单表)数据。
全内存
假设内存可以容纳全部要读取的数据,并行取数后再进行下一步运算(全内存的计算速度最快)。
举例
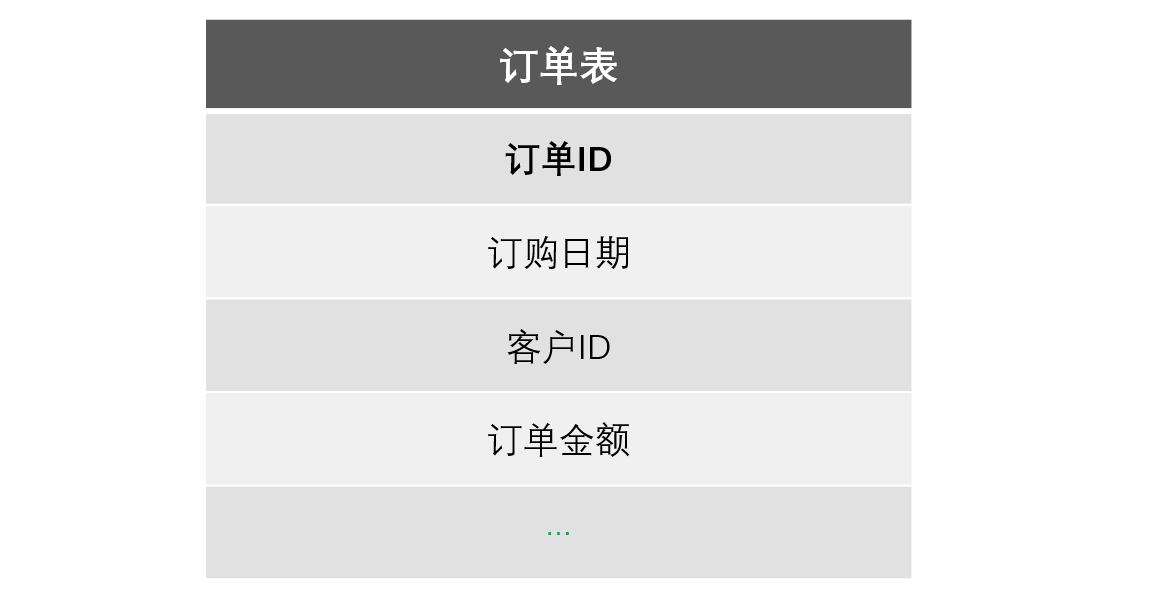
订单(Orders)有订单 ID,订购日期,订单金额等字段,其中订单 ID 是递增的整数逻辑主键。
【计算目标】 并行读取某时间段内订单数
面向单表(单条 SQL)并行取数需要通过参数将源数据拆分多段,建立多个数据库连接并行查询。往往需要将数据尽可能平均拆分以避免查询时间不均导致任务等待,同时分段参数尽可能建立在索引字段上以保证分段效率。
集算器实现
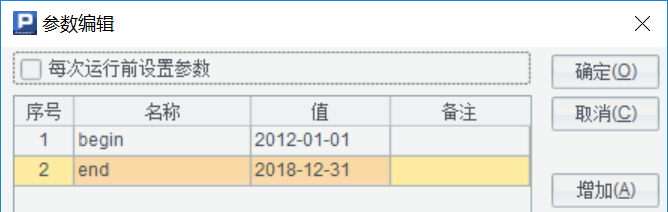
集算器参数
根据查询时间段建立脚本参数,查询起止日期
集算器实现
分段策略(一)基于索引字段分段
基于单表(单 SQL)并行取数前需要进行数据分段,尽量保证每个分段的数据平均。而分段参数尽量基于建立索引的字段(如订单编号)。之所以要使用索引字段来分段,是因为使用索引并不会真地遍历整个表,而是直接定位,当数据量较大时优势明显。
集算器脚本
编写并行取数脚本,这里按照建立索引的订单编号进行分段:
| A | B | C | |
|---|---|---|---|
| 1 | =connect(“db”) | ||
| 2 | =A1.query(“select min( 订单 ID) 最小 ID,max(订单 ID) 最大 ID from 订单 where 订购日期 >=? and 订购日期 <=?”,begin,end) | =b=A2. 最小 ID | =e=A2. 最大 ID |
| 3 | =p=4 | / 并行数 | |
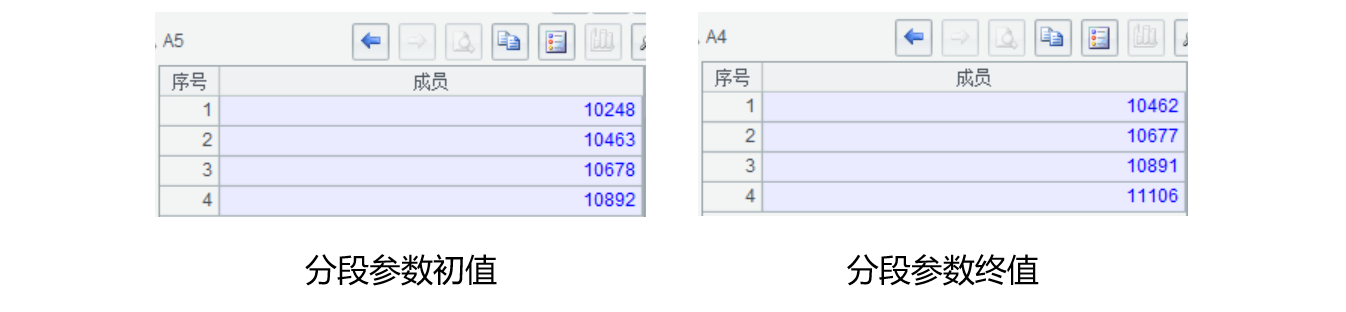
| 4 | =p.(b+(e-b)*~\p) | / 分段参数终值 | |
| 5 | =b | A4.to(,p-1).(~+1) | / 分段参数初值 |
| 6 | fork A5,A4 | ||
| 7 | =connect(“db”) | ||
| 8 | =B7.query@x(“select * from 订单 where 订单 ID>=? and 订单 ID<=? and 订购日期 >=? and 订购日期 <=?”,A6(1),A6(2),begin,end) | ||
| 9 | =A6.conj() | / 合并查询结果 |
脚本解析:
1、A2 根据查询起止日期获得最大订单编号和最小订单编号,用于后面分段
2、B2-C2 将最小订单号和最大订单号分别赋值给变量 b 和 e

3、A3 设置并行数,使用并行取数前应检查集算器的并行数配置以及授权中对并行数量的许可
4、A4-A5 根据起止订单编号和并行数计算每个并行任务的起止分段参数(序列)
5、通过 fork 启动多个(4 个)线程,参数为分段起止参数序列,这里可以看到 fork 启动的线程数与参数序列成员数相同。在集算器中,经常将序表、序列作为参数值参与运算,非常方便
6、B7 为每个线程(子任务)建立数据库连接,需要注意连接必须在 fork 子句中建立,以便为多线程分别使用,若共用一个连接无法起到加速取数的效果,数据库会自动把同一连接上的多个请求改为串行执行。因此只有当数据库负担不重,有足够多连接可用时才可以使用并行取数提升性能
7、B8 分别查询每个分段数据,查询结果返回到 A6 格。这里 fork 子句直接返回查询结果(子句最后一行),如果想返回其中某个或某几个计算值可以显示使用 return 关键字返回子线程计算结果
8、返回结果的 A6 格结果,4 个线程返回 4 个结果集
9、A9 合并所有子线程查询结果,以便进行下一步计算
基于索引字段进行数据分段,并且数据分段比较平均时,使用多线程并行查询数据库几乎可以获得线程数倍(线性)的性能提升。
分段策略(二)基于非索引字段分段
如果数据库负担不重时,也可以基于非索引字段进行分段(如日期),相对 JDBC 取数时间,多次遍历库表时间也并不是很大,而这样做的好处是不需要事先查询数据库以确定起止段界(如最大最小订单编号)。
集算器脚本
| A | B | C | ||
|---|---|---|---|---|
| 1 | =connect(“db”) | |||
| 2 | =n=interval(begin,end) | |||
| 3 | =p=4 | / 并行数 | ||
| 4 | =p.(n*~\p).(elapse(begin,~)) |
/ 分段参数终值 | ||
| 5 | =begin | A4.to(,p-1).(after(~,-1)) | / 分段参数初值 | |
| 6 | fork A5,A4 | |||
| 7 | =connect(“db”) | |||
| 8 | =B7.query@x(“select * from 订单 where 订购日期 >=? and 订购日期 <=?”,A6(1),A6(2)) | |||
| 9 | =A6.conj() | / 合并查询结果 |
脚本解析:
与上述使用索引字段订单 ID 分段不同,这里使用非索引字段订购日期进行分段。设起止日期为:2012-01-01 和 2015-12-31。
1、A2 计算起止日期查询参数间隔天数,用于分段;interval 函数还可以计算年、季度、月、时、分、秒等间隔,用于日期时间处理很方便
2、A3-A5 根据并行数和日期间隔计算分段起止参数序列
3、A6 根据参数序列启动多线程,B8 完成查询并将结果返回到 A6 格,A9 合并查询结果
分段策略(三)并行线程数多于 CPU 核数
前面我们提到:建议并行任务数不要超过 CPU 核数,因为更多的任务数并不会增加并行度,而且还可以避免 CPU 进行线程切换带来的额外时间开销。但有时也可以将任务数设置到远大于 CPU 核数,可以设置为 CPU 核数的倍数个,这样多 CPU 负载也可以达到动态平衡,而且某些计算还可以简化分段。如上述例子中,若只查询某一年数据就可以把线程数设置为 12(月),从而简化分段。
集算器提供了多线程任务动态平衡机制,当任务数大于并行数配置时,集算器会自动为计算结束的线程分配下一个任务,这时可以保证某个线程会多跑几个小任务,另一个线程只跑少量大任务,达到总体平衡,而不必拘泥于必须把数据量平均分配。
集算器脚本
| A | B | C | |
|---|---|---|---|
| 1 | fork to(1,12) | ||
| 2 | =connect(“demo”) | ||
| 3 | =B2.query@x(“select * from 订单 wheremonth( 订购日期)=? and 订购日期 >=? and 订购日期 <=?”,A1,begin,end) | ||
| 4 | =A1.conj() | / 合并查询结果 |
脚本解析:
1、A1 根据 1 到 12 的序列启动 12 个线程
2、B3 每个线程查询一个月的数据并返回结果到 A1
关于 fork 语句
在集算器中,通过 fork 语句可以启动多个线程实施并行计算,而且集算器还提供了多种 merge 函数可以很方便合并并行结果,十分方便。
外存
有时某一条语句(一个表)的数据量较大,分段后并行子任务仍然无法全部加载到内存中,这时需要使用集算器提供的外存计算机制,基于游标查询数据。
举例
沿用上面的例子,假设分段后的数据量很大需要使用游标分批读取处理数据。
集算器实现
| A | B | C | |
|---|---|---|---|
| 1 | =connect(“db”) | ||
| 2 | =A1.query(“select min( 订单 ID) 最小 ID,max(订单 ID) 最大 ID from 订单 where 订购日期 >=? and 订购日期 <=?”,begin,end) | =b=A2. 最小 ID | =e=A2. 最大 ID |
| 3 | =p=4 | / 并行数 | |
| 4 | =p.(b+(e-b)*~\p) | / 分段参数终值 | |
| 5 | =b|A4.to(,p-1).(~+1) |
/ 分段参数初值 | |
| 6 | fork A5,A4 | ||
| 7 | =connect(“db”) | ||
| 8 | =B7.cursor@x(“select * from 订单 where 订单 ID>=? and 订单 ID<=? and 订购日期 >=? and 订购日期 <=?”,A6(1),A6(2),begin,end) | ||
| 9 | =A6.mcursor() | / 合并查询结果 | |
| 10 | =file(“D:\\ 订单.txt”).export@t(A9) | / 基于游标写入文件 |
脚本解析:
1、B8 建立数据库游标,查询并不真正取数,多个游标返回到 A6 格
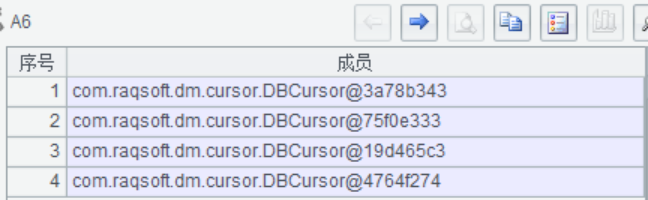
2、A9 合并多路游标,接下来就可以当做一个游标继续使用
3、A10 基于游标,将查询数据分批写入文件中。因为各个线程的运行速度无法保证规律性,所以基于多线程导出数据时次序不可控,对数据顺序有要求时不能使用这个方法。
基于外存游标并行查询与全内存方式非常类似,当内存资源较紧张时可以通过外存计算的方式减少内存占用。
多表并行取数
除了通过条件针对单条 SQL(单表)进行并行取数外,在一些多 SQL 查询场景(如报表多数据集)下仍然可以通过并行同时执行多条语句进行取数。
举例
有多个查询 SQL 基于多个表查询数据,需要提升查询性能。
【计算目标】 并行读取 5 个表数据,并完成关联
这里我们使用 5 条非常简单(基于单表)的查询 SQL,实际业务中多条SQL 可以任意复杂。
集算器实现
| A | B | C | |
|---|---|---|---|
| 1 | =connect(“db”) | ||
| 2 | =”select * from 订单 where 订购日期 >=date(‘”/begin/”‘) and 订购日期 <=date(‘”/end/”‘)” | ||
| 3 | select 订单 ID, 产品 ID, 单价, 数量 from 订单明细 | ||
| 4 | select 客户 ID, 公司名称 from 客户 | ||
| 5 | select 雇员 ID, 姓名 from 雇员 | ||
| 6 | select 产品 ID, 产品名称 from 产品 | ||
| 7 | fork [A2:A6] | ||
| 8 | =connect(“db”) | ||
| 9 | =B8.query@x(A7) | ||
| 10 | = 订单 =A7(1) | = 明细 =A7(2) | |
| 11 | = 客户 =A7(3) | = 雇员 =A7(4) | = 产品 =A7(5) |
| 12 | > 订单.switch(客户 ID, 客户: 客户 ID; 雇员 ID, 雇员: 雇员 ID) | ||
| 13 | = 明细.switch(订单 ID, 订单: 订单 ID; 产品 ID, 产品: 产品 ID) | ||
| 14 | =A13.new(订单 ID. 客户 ID. 公司名称: 客户名称, 订单 ID. 订单 ID: 订单编号, 订单 ID. 雇员 ID. 姓名: 销售, 产品 ID. 产品名称: 产品, 单价: 价格, 数量) |
脚本解析:
1、A2-A6 为查询用 SQL 语句串
2、A7 根据多条 SQL 组成序列启动多线程(5 个)
3、B9 每个线程执行 SQL 查询数据将结果返回到 A7 格(5 个结果集组成的序列)
4、A10-C11 通过序号分别获取 5 个结果集
5、为了保证完整性,A12-A14 对 5 个结果集进行关联并通过外键属性化的方式创建结果序表
以上是集算器并行取数的部分示例,事实上集算器还可以做更复杂的并行计算和结果归并。集算器多线程并行的意义在于使用简单、成本低,相对 JAVA 复杂的多线程编程集算器可以简单到几行脚本,相对数据库集群方案集算器的成本更加可控,而且即使部署数据库集群仍然可以使用集算器加速集群单个数据库节点的取数速度。
作者:lisongbo
链接:http://c.raqsoft.com.cn/article/1533291083840?r=shiguang
来源:乾学院
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
加速JDBC的快捷方法的更多相关文章
- ThinkPHP单字母函数(快捷方法)使用总结
在ThinkPHP中有许多使用简便的单字母函数(即快捷方法),可以很方便开发者快速的调用,但是字母函数却不方便记忆,本文将所有的字母函数总结一下,以方便以后查找. 1.U() URL组装 支持不同UR ...
- JDBC连接MySQL 方法 实例及资料收集
JDBC连接MySQL 方法 实例及资料收集 准备工作 首先,安装MySQL,配置用户名和密码,创建数据库. 可参见之前的文章: http://www.cnblogs.com/mengdd/p/315 ...
- 批量产生ssh2项目中hibernate带注解的pojo类的快捷方法
近几个月一直在忙于项目组的ios应用项目的开发,没有太多时间去研究web应用方面的问题了.刚好,昨天有网友问到如何批量产生hibernate带注解的pojo类的快捷方法,所谓批量就是指将当前数据库中所 ...
- Photoshop CC 常用快捷方法有哪些?
Photoshop CC 常用快捷方法有哪些? 属性栏 工具栏 控制面板 绘图区 1. 多个图层如何快速居中? 在 控制面板 中选中多个图层创建 链接图层 在 工具栏 选择 移动工具 在 属性栏 点击 ...
- Docker配置国内加速器加速镜像下载的方法
在搭建hyperledger fabric的开发环境的时候,用docker去下载镜像,好慢好慢,慢到下了一个下午没有下载完成,最后还是失败了.最后去网上找了一下,发现有配置国内加速器加速镜像下载的方法 ...
- jQuery-显示与隐藏不用判断的快捷方法
功能:显示被隐藏的元素,隐藏已显示的元素. 常规方法:(需要先判断元素状态) $("button").click(function(){ if ($(".content& ...
- iTerm 2打造ssh完美连接Linux服务器快捷方法
iTerm 2打造ssh完美连接Linux服务器快捷方法 2019年05月02日 10:40:19 Mars0908 阅读数 213更多 个人分类: Mac下开发 版权声明:本文为博主原创文章,遵 ...
- JDBC基本使用方法
JDBC基本使用方法 JDBC固定步骤: 加载驱动 String url="jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true& ...
- Dictionary读取键值的快捷方法
对泛型集合Dictionary<T,T> 进行读取键值是经常的操作,一般情况下,都是通过keys 和values进行键值的读取操作: eg: foreach (var item in di ...
随机推荐
- Delphi:程序自己删除自己,适用于任何windows版本(含源码)
Delphi:程序自己删除自己,适用于任何windows版本(含源码) function Suicide: Boolean; var sei: TSHELLEXECUTEINFO; szMod ...
- Spring4 mvc+maven 框架搭建(3)
经过前面两个环节,spring mvc的原料已经准备好了,现在就可以正式开始搭建springmvc框架了. 首先先介绍介绍搭建的框架具有的功能: 1)集成log4j,配置好日志相关并可以打印出相关的日 ...
- JS获取当前时间和日期
当前时间和日期 var myDate = new Date(); myDate.getYear(); //获取当前年份(2位) myDate.getFullYear(); //获取完整的年份(4位,1 ...
- Java类加载顺序
很长时间没看这方面的内容了,写篇文章让自己牢记一下,顺便分享一下. 首先,写代码以便检验结果.测试代码: public class Test { public static void main(Str ...
- Android 开发服务类 05_ ApkPatchDemo
APP 增量更新服务端[https://github.com/cundong/SmartAppUpdates] import com.cundong.common.Constants; import ...
- 全网最详细的再次或多次格式化导致namenode的ClusterID和datanode的ClusterID之间不一致的问题解决办法(图文详解)
不多说,直接上干货! java.io.IOException: Incompatible clusterIDs in /opt/modules/hadoop-2.6.0/data/tmp/dfs/da ...
- 世界上最短的bash脚本
世界上最短的bash脚本长这样: #!/bin/bash 为啥呢?见下图: 推荐一篇文章,讲解为啥shell脚本开头总是"#!/bin/bash".文风太清奇,不好翻译,看原文吧: ...
- Java NIO 基础知识
前言 前言部分是科普,读者可自行选择是否阅读这部分内容. 为什么我们需要关心 NIO?我想很多业务猿都会有这个疑问. 我在工作的前两年对这个问题也很不解,因为那个时候我认为自己已经非常熟悉 IO 操作 ...
- 查看mongodb的状态
1.mongotop #mongotop -h 127.0.0.1:27017 -u test -p test123 --authenticationDatabase admin 输出说明: ns:包 ...
- eclipse下查看java源码设置
myway: 1.选择一函数,按住ctrl,显示open declaration(或按F3); 2.点进去: 如果未配置,点 source attachment configuration -- ex ...