Python爬虫连载2-reponse\parse简介
一、reponse解析
urlopen的返回对象
(1)geturl:返回网页地址
(2)info:请求反馈对象的meta信息
(3)getcode:返回的http code
from urllib import request
import chardet
"""
解析reponse
"""
if __name__ == "__main__":
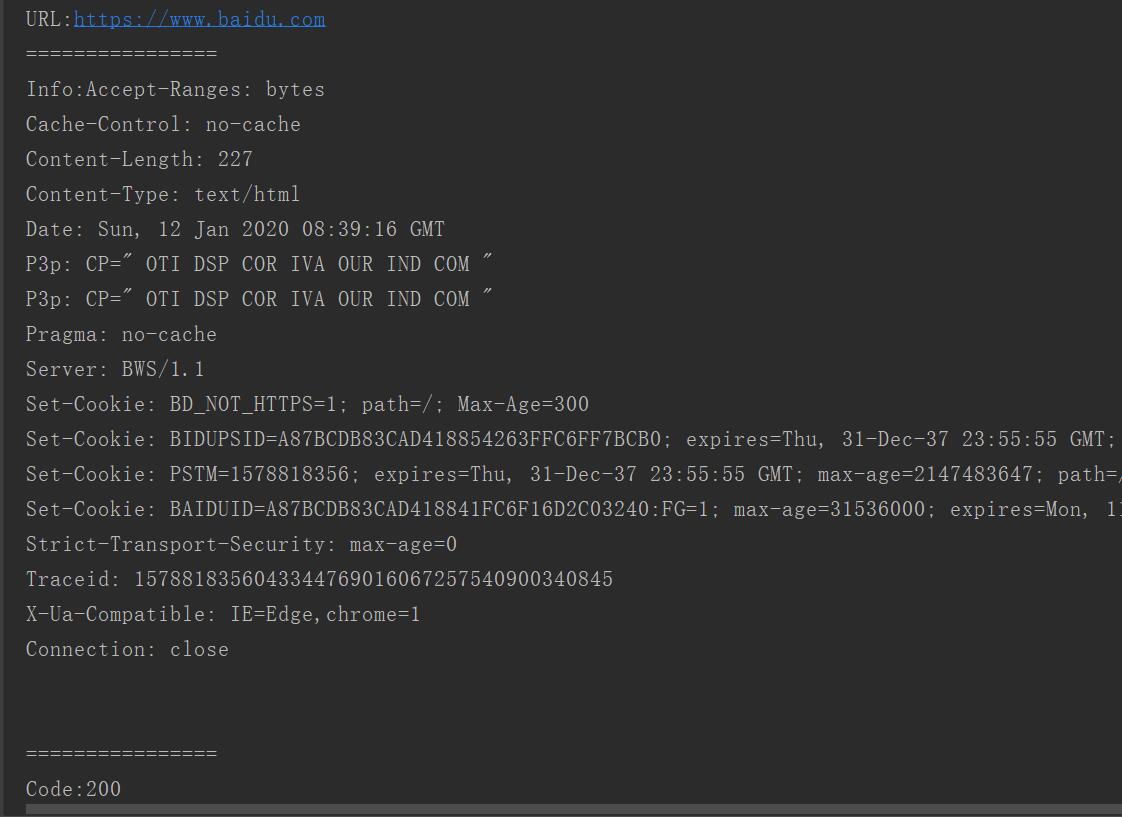
url = "https://www.baidu.com"
rsp = request.urlopen(url)
print("URL:{0}".format(rsp.geturl()))#网页地址
print("================")
print("Info:{0}".format(rsp.info()))#网页头信息
print("================")
print("Code:{0}".format(rsp.getcode()))#请求后返回的状态码
二、parse
1.request.date的使用
访问网络的两种方式
(1)get(2)post
2.url.parse用来解析url
from urllib import request,parse
import chardet
"""
解析reponse
"""
if __name__ == "__main__":
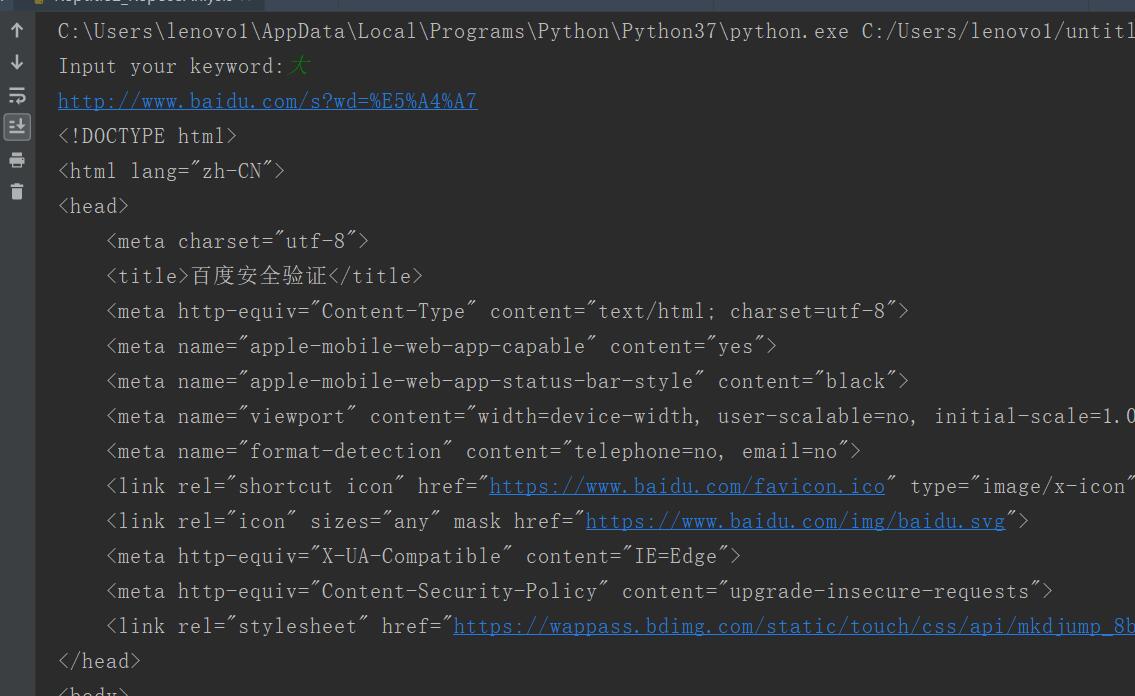
url = "http://www.baidu.com/s?"
wd = input("Input your keyword:")
#要想使用data,需要使用字典结构
qs = {
"wd":wd
}
#转换url编码
qs = parse.urlencode(qs)#对关键字进行编码
fullurl = url + qs#百度搜索传入的地址是基础地址加上关键字的编码形式
print(fullurl)
rsp = request.urlopen(fullurl)
html = rsp.read()
html = html.decode()#解码
#使用get取值保证不会出错
print(html)
三、源码
Reptile2_ReposeAnlysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile2_ReposeAnlysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050(心悦君兮君不知-睿)
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料
Python爬虫连载2-reponse\parse简介的更多相关文章
- Python爬虫连载1-urllib.request和chardet包使用方式
一.参考资料 1.<Python网络数据采集>图灵工业出版社 2.<精通Python爬虫框架Scrapy>人民邮电出版社 3.[Scrapy官方教程](http://scrap ...
- Python爬虫连载10-Requests模块、Proxy代理
一.Request模块 1.HTTP for Humans,更简洁更友好 2.继承了urllib所有的特征 3.底层使用的是urllib3 4.开源地址:https://github.com/req ...
- Python爬虫连载9-JS加密之“盐”、ajax请求
一.JS加密之“盐” 1.salt属性“盐":多用于密码学,比如我们的银行卡是六位密码,但是实际上在银行的系统里,我们输入密码后,会给原始的密码添加若干字符,形成更加难以破解的密码.这个过 ...
- Python爬虫连载8-JS加密(一)
一.JS加密 1.有的反爬虫策略采用js对需要传输的数据进行加密处理. 2.经过加密,传输的就是密文 3.加密函数或者过程一定是在浏览器完成,也就是一定会把代码(js代码)暴露给使用者 4.通多阅读加 ...
- Python爬虫连载7-cookie的保存与读取、SSL讲解
一.cookie的保存与读取 1.cookie的保存-FileCookie.Jar from urllib import request,parse from http import cookieja ...
- Python爬虫入门:Urllib parse库使用详解(二)
文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习 如有侵权,请联系删除 获取url参数 urlparse 和 parse_qs ParseRes ...
- Python爬虫连载3-Post解析、Request类
一.访问网络的两种方法 1.get:利用参数给服务器传递信息:参数为dict,然后parse解码 2.post:一般向服务器传递参数使用:post是把信息自动加密处理:如果想要使用post信息,需要使 ...
- Python爬虫连载6-cookie深入使用实例化实现自动登录
一.使用cookie登录 1.直接把cookie复制下去,然后手动放到请求头 2.http模块包含一些关于cookie的模块,通过他们我们可以自动使用cookie (1)cookieJar 管理存储c ...
- Python爬虫连载5-Proxy、Cookie解析
一.ProxyHandler处理(代理服务器) 1.使用代理IP,是爬虫的常用手段 2.获取代理服务器的地址: www.xicidaili.com www.goubanjia.com 3.代理用来隐藏 ...
随机推荐
- C++面试常见问题——02动态分配内存
动态分配内存 C++动态内存 C++程序中内存分为两个部分 堆:程序中未使用的内存,在程序运行时可用于动态分配内存. 栈:函数内部申明的所有变量都将占用栈内存. 很多时候不知道一个程序到底需要多少内存 ...
- 自动填充IP地址
在windows下的DOS窗口中 要利用Netsh命令,进入到DOS下的网络配置状态,就能实现各种网络配置. 进入IP设置模式 在DOS环境中,设置网络参数之前,必须先进入IP设置模式才可以.先打开系 ...
- Codeforces 460C 二分结果+线段树维护
发现最近碰到好多次二分结果的题目,上次多校也是,被我很机智的快速过了,这个思想确实非常不错.在正面求比较难处理的时候,二分结果再判断是否有效往往柳暗花明. 这个题目给定n个数字的序列,可以操作m次,每 ...
- Flink 历史服务与连接器
History Server(历史服务) Flink提供了记录历史任务运行情况的服务,可用于在关闭Flink群集后依然能够查询已完成作业的相关信息. 配置: # 任务执行信息存储在hdfs目录 job ...
- 逆向-PE重定位表
重定位表 当链接器生成一个PE文件时,会假设这个文件在执行时被装载到默认的基地址处(基地址+RVA就是VA).并把code和data的相关地址写入PE文件.如果像EXE一样首先加载就是它image ...
- 第十三篇Django Logging配置样例
第十三篇Django Logging配置样例 阅读目录(Content) Django 日志配置模板 官方链接 Django Logging Django 日志配置模板 LOGGING = { 've ...
- 实战 迁移学习 VGG19、ResNet50、InceptionV3 实践 猫狗大战 问题
实战 迁移学习 VGG19.ResNet50.InceptionV3 实践 猫狗大战 问题 参考博客:::https://blog.csdn.net/pengdali/article/detail ...
- 11 —— 回顾 JSON 相互转换的知识点
/** * json 转换的两种方式 * * 一,转为字符串 (序列化的过程) * JSON.stringify() * * 二,json 转化为字符串 (反序列化的过程) * JSON.parse( ...
- Vulkan 开发学习资料汇总
开发资料汇总 1.API Reference 2.Vulkan Spec 有详细说明的pdf 文章 1.知乎Vulkan-高性能渲染 2.Life of a triangle - NVIDIA's l ...
- 二十八、CI框架之自己写分页类,符合CI的路径规范
一.参照了CSDN上某个前辈写的一个CI分页类,自己删删改改仿写了一个类似的分页类,代码如下: 二.我们在模型里面写2个数据查询的函数,一个用于查询数据数量,一个用于查询出具体数据 三.我们在控制器里 ...