Hadoop(九)Hadoop IO之Compression和Codecs
前言
前面一篇介绍了Java怎么去查看数据块的相关信息和怎么去查看文件系统。我们只要知道怎么去查看就行了!接下来我分享的是Hadoop的I/O操作。
在Hadoop中为什么要去使用压缩(Compression)呢?接下来我们就知道了。
一、压缩(Compression)概述
1.1、压缩的好处
减少储存文件所需要的磁盘空间,并加速数据在网络和磁盘上的传输。这两个在大数据处理大龄数据时相当重要!
1.2、压缩格式总结
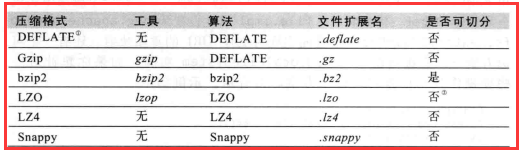
Hadoop对前面三种有默认集成,有就是说Hadoop支持DEFLATE、Gzip、bzip2三种压缩格式。而后面三种Hadoop没有支持,要用的话要自己去官网
下载相应的源码去编译加入到Hadoop才能用。
注意:
1)这里我要说的是“是否分割”,当我们一个文件去压缩即使有非常好的压缩算法,但是它的大小还是超过了一个数据块的大小,这时就涉及到分割了。
所以说在以后的压缩我们大多数情况下会使用bzip2。
2)Gzip和bzip2比较时,bzip2的压缩率(压缩之后的大小除以源文件的大小)要小,所以说bzip2的压缩效果好。而这里就会压缩和解压缩的时候浪费更多的时间。
就是我们常说的“用时间换取空间”。
二、编解码器(Codec)概述
codec实现了一种压缩-加压缩算法(意思就是codec使用相关的算法对数据进行编解码)。在Hadoop中,一个对CompressionCodec接口的实现代表一个codec。
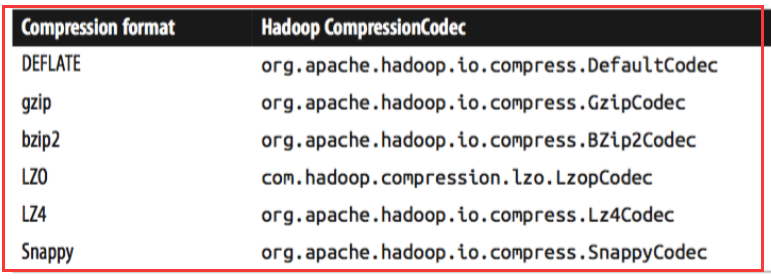
对于不同的压缩算法有不同的编解码器
我们要对一个文件进行压缩需要编码器,对一个压缩文件进行解压需要解码器。那我们怎么样去获取编解码器呢?
有两种方式:
一是:根据扩展名让程序自己去选择相应的编解码器。比如说:我在本地有一个文件是 user.txt我们通过-Dinput=user.txt去上传这个文件到集群,
在集群中我们把它指定到-Doutput=/user.txt.gz.。这是我们程序的相关的类会根据你的扩展名(这里是.gz)获取相应的压缩编解码器。
在Hadoop中有一个CompressionCodecFactory会根据扩展名获取相应的编解码器对象 。
二是:我们自己去指定编解码器。为什么要去指定呢?比如说,我在本地有一个文件是user.txt.gz,其实这个压缩文件是使用的是bzip2的压缩算法压缩的。
(因为我自己去更改了它的扩展名),所以这时候就要自己去指定编解码器。
三、Java编程实现文件的压缩与解压缩
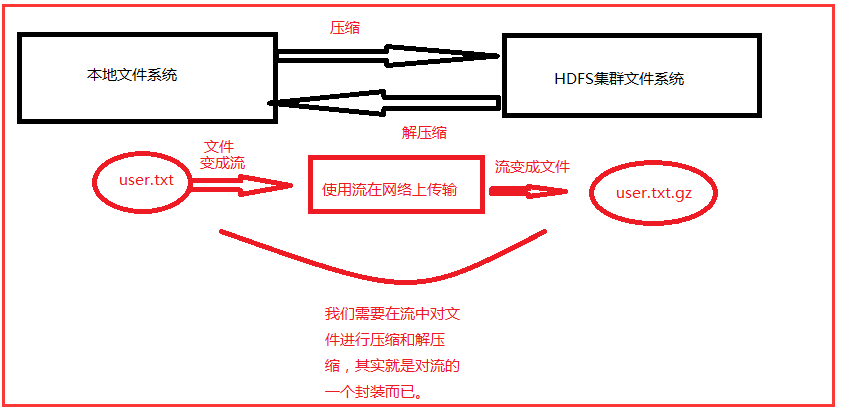
3.1、原理分析
在我们把本地的文件上传的集群的时候,到底是哪里需要压缩,哪里需要解压缩,在哪里压缩?这都是需要明白,下面画一张图给大家理解:
3.2、相关类和方法
在Hadoop中关于压缩和解压缩的包、接口和类:
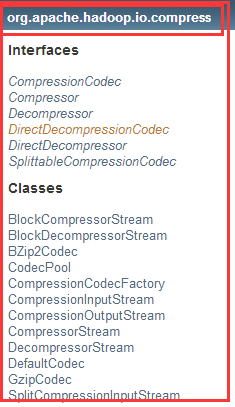
1)CompressionCodec接口中

2)CompressionCodecFactory类

第一个是:根据文件的文件名后缀找到相应的压缩编解码器
第二个是:为编解码器的标准类名找到相关的压缩编解码器。
第三个是:为编解码器的标准类名或通过编解码器别名找到相关的压缩编解码器。
3.3、Java将本地文件压缩上传到集群当中
1)核心代码
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class WriteDemo_0010
extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
String input=conf.get("input");
String output=conf.get("output");
LocalFileSystem lfs=
FileSystem.getLocal(conf);
FileSystem rfs=
FileSystem.get(
URI.create(output),conf);
FSDataInputStream is=
lfs.open(new Path(input));
FSDataOutputStream os=
rfs.create(new Path(output)); CompressionCodecFactory ccf=
new CompressionCodecFactory(conf);
//把路径传进去,根据指定的后缀名获取编解码器
CompressionCodec codec=
ccf.getCodec(new Path(output));
CompressionOutputStream cos=
codec.createOutputStream(os);
System.out.println(
codec.getClass().getName()); IOUtils.copyBytes(is,cos,,true);
//close
return ;
} public static void main(String[] args) throws Exception{
System.exit(
ToolRunner.run(
new WriteDemo_0010(),args));
}
}
2)测试
将IEDA中打好的jar包上传到Linux中(安装了HDFS集群的客户端的服务器中)执行:

结果:
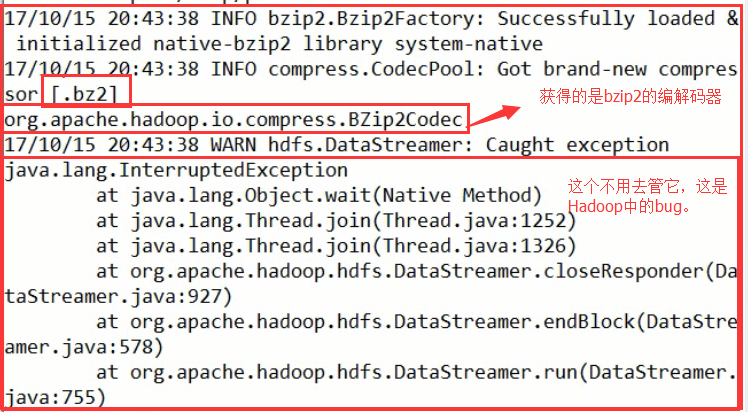
我们可以从前面的那种表中可以看的出来,获取到了相应的编解码器。
再次测试:

结果:

3.4、Java将集群文件解压缩到本地
1)核心代码
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocalFileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class ReadDemo_0010
extends Configured
implements Tool{
@Override
public int run(String[] args) throws Exception{
Configuration conf=getConf();
String input=conf.get("input");
String output=conf.get("output");
FileSystem rfs=
FileSystem.get(
URI.create(input),conf);
LocalFileSystem lfs=
FileSystem.getLocal(conf); FSDataInputStream is=
rfs.open(new Path(input));
FSDataOutputStream os=
lfs.create(new Path(output)); CompressionCodecFactory factory=
new CompressionCodecFactory(conf);
CompressionCodec codec=
factory.getCodec(new Path(input));
CompressionInputStream cis=
codec.createInputStream(is); IOUtils.copyBytes(cis,os,1024,true);
return ;
} public static void main(String[] args) throws Exception{
System.exit(
ToolRunner.run(
new ReadDemo_0010(),args));
}
}
2)测试

结果:

查看结果:

喜欢就点个“推荐”哦!
Hadoop(九)Hadoop IO之Compression和Codecs的更多相关文章
- 【原创】大叔问题定位分享(16)spark写数据到hive外部表报错ClassCastException: org.apache.hadoop.hive.hbase.HiveHBaseTableOutputFormat cannot be cast to org.apache.hadoop.hive.ql.io.HiveOutputFormat
spark 2.1.1 spark在写数据到hive外部表(底层数据在hbase中)时会报错 Caused by: java.lang.ClassCastException: org.apache.h ...
- Hadoop基础-通过IO流操作HDFS
Hadoop基础-通过IO流操作HDFS 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.上传文件 /* @author :yinzhengjie Blog:http://www ...
- hive orc压缩数据异常java.lang.ClassCastException: org.apache.hadoop.io.Text cannot be cast to org.apache.hadoop.hive.ql.io.orc.OrcSerde$OrcSerdeRow
hive表在创建时候指定存储格式 STORED AS ORC tblproperties ('orc.compress'='SNAPPY'); 当insert数据到表时抛出异常 Caused by: ...
- hadoop基础----hadoop实战(九)-----hadoop管理工具---CDH的错误排查(持续更新)
在CDH安装完成后或者CDH使用过程中经常会有错误或者警报,需要我们去解决,积累如下: 解决红色警报 时钟偏差 这是因为我们的NTP服务不起作用导致的,几台机子之间有几秒钟的时间偏差. 这种情况下一是 ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- hadoop记录-Hadoop参数汇总
Hadoop参数汇总 linux参数 以下参数最好优化一下: 文件描述符ulimit -n 用户最大进程 nproc (hbase需要 hbse book) 关闭swap分区 设置合理的预读取缓冲区 ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- hadoop之 hadoop 2.2.X 弃用的配置属性名称及其替换名称对照表
Deprecated Properties 弃用属性 The following table lists the configuration property names that are depr ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
随机推荐
- 201521123068 《java程序设计》 第13周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 2. 书面作业 1.网络基础 1.1 比较ping www.baidu.com与ping cec.jmu. ...
- 关于maven项目的一些报错问题
本文为自己记录的笔记略显粗糙后续会把遇到的问题追加进来.忘大神多指点 1.父工程红色感叹号 此类问题解决方法,一般打开pom文件查看红色标记处是否有报错,也就是看哪个jar包没有下下来.分为两种情况. ...
- 使用Spring的JavaConfig 和 @Autowired注解与自动装配
1 JavaConfig 配置方法 之前我们都是在xml文件中定义bean的,比如: 1 2 3 4 5 6 7 8 <beans xmlns="http://www.springf ...
- GitHub使用(一) - 新建个人网站
1.首先进入“仓库Repositories”,点击“新建New”.
- program 1 : python codes for login program(登录程序python代码)
#improt time module for count down puase time import time #set var for loop counting counter=1 #logi ...
- ThinkPHP中:使用递归写node_merge()函数
需求描述: 现有一个节点集合 可以视为一个二维数组 array(5) { [0] => array(4) { ["id"] => string(1) "1&q ...
- Relocation 状态压缩DP
Relocation Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u Submit ...
- Java课堂作业01
题目:编写一个程序,此程序从命令行接收多个数字,求和之后输出结果. 设计思想:用for循环将string型转换为int型,再用sum求和,使其一直相加,到达最大长度,sum即为所求sum. 程序流程图 ...
- Linux 独立安装subversion-1.8.18
一.所需软件包 1.apr-1.4.6.tar.gz 下载地址:http://apr.apache.org/ 2.apr-util-1.4.1.tar.gz 下载地址:http://apr.apa ...
- 史上前端面试最全知识点(附答案)---html & js & css
史上前端面试最全知识点(附答案) 一.html & js & css 1.AMD和CMD是什么?它们的区别有哪些? AMD和CMD是二种模块定义规范.现在都使用模块化编程,AMD,异步 ...