Hadoop生态系统图解
Hadoop生态架构图
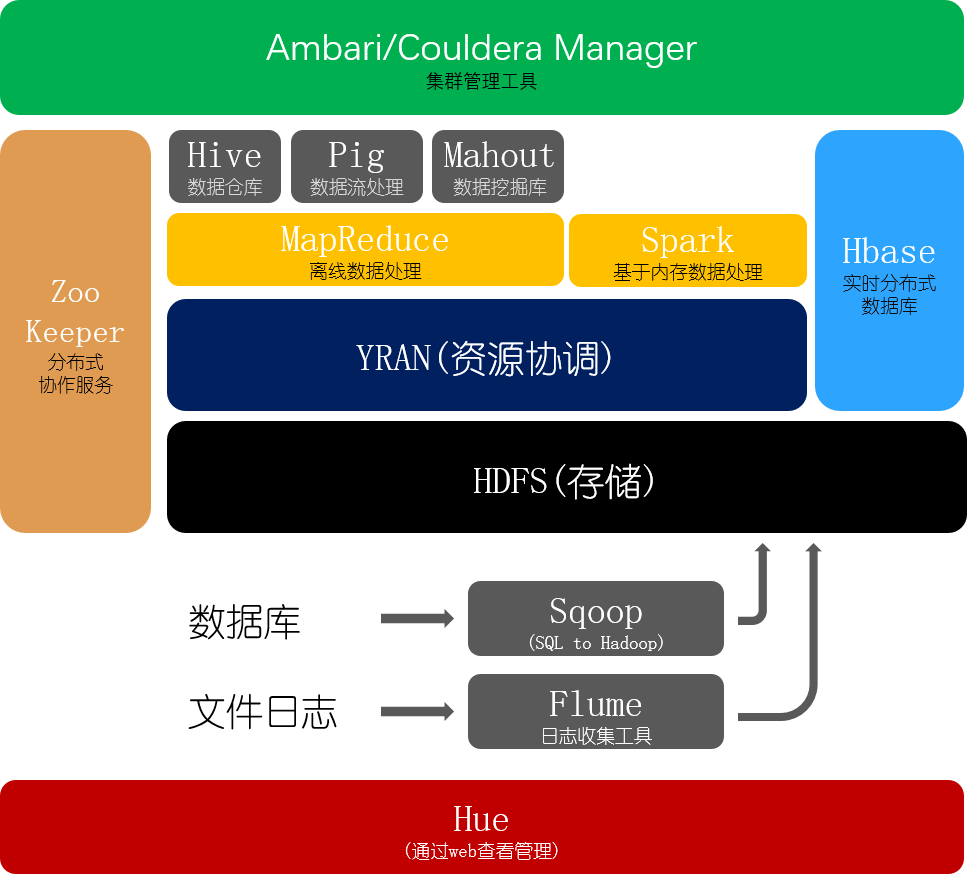
参考文章:
Hadoop生态系统介绍
HDFS架构
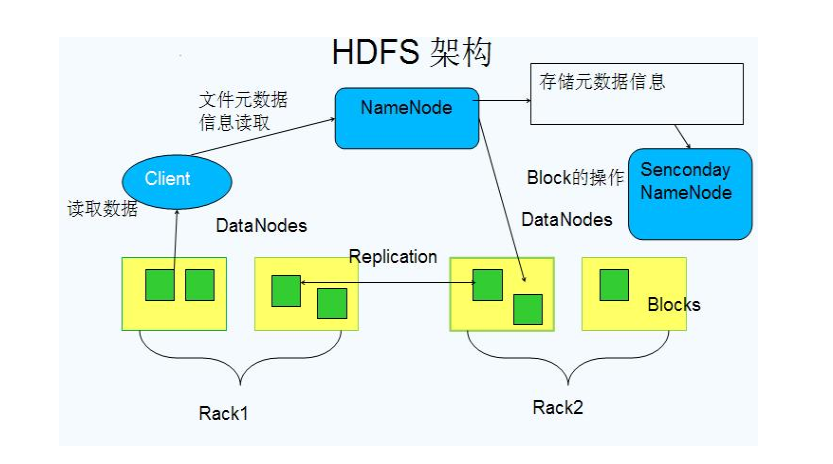
1.NaneDode:主节点,**存储文件的元数据**如文件名,文件目录结构,文件属性(生成时间,副本数量,文件权限),以及每个文件的块列表所在DataNode等
一个JAVA进程:数据存储在内存中,为了速度读写(本地还有备份)
本地磁盘:1、fsimage:镜像文件
2、edits :编辑日志
2.DataNode:数据节点,实际的本地文件系统,**存储文件块数据,以及快数据的检验和**
真正的存储:数据在磁盘中
3.Secondary NameNode用来**监控HDFS状态的辅助后台程序**,每隔一段时间**获取HDFS元数据快照**,就是定时对本地磁盘的 NameNode 的 fsimage 和 edits 进行合并,不断更新镜像
数据以block方式存储
Hadoop2.x块大小:128M
参考文章:
HDFS 原理、架构与特性介绍
谷歌三大核心技术(一)Google File System中文版
YARN架构

1.ResourceManager 资源管理者
*接收客户端请求
*启动/监控ApplicationMaster
*监控NodeManager
*资源分配与调度
2.NodeManager 节点管理者
*管理节点资源
*处理来自ResourceManager的任务
*处理来自ApplicationMaster的任务
3.ApplicationMaster 应用主管
*数据切分
*为应用程序向ResourceManager提出资源申请,并分配给内部任务
*任务监控与容错
4.container 容器
*对任务运行环境的抽象,封装了CPU,内存等多维资源以及环境变量,启动命令等运行任务的相关信息
参考文章:
Hadoop构架概览
MapReduce框架(离线运算框架)
1.将数据计算过程分为两个阶段 Map 和 Reduce
*Map将数据进行并行处理
*Reduce将处理结果进行汇总
2.shuffle 连接 Map 和 Reduce 阶段
*Map Task 将数据存储到本地磁盘
*Reduce Task 将数据从 Map Task 上读一份数据
特点:
*仅适合离线数据处理,有极高的容错性和拓展性,适合简单批处理任务
*启动开销大,过多使用磁盘导致效率低下
MapReduce on YRAN
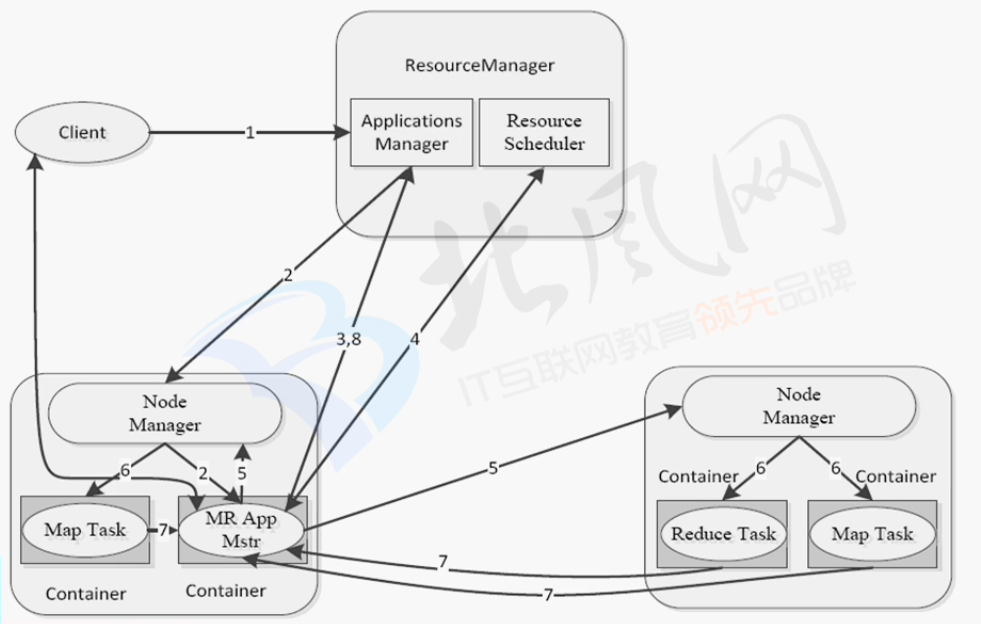
从客户端到客户端中间的过程详解图
注:图片来源见水印,侵删
Hadoop生态系统图解的更多相关文章
- Hadoop概念学习系列之Hadoop 生态系统(十二)
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Hadoop生态系统如何选择搭建
Apache Hadoop项目的目前版本(2.0版)含有以下模块: Hadoop通用模块:支持其他Hadoop模块的通用工具集. Hadoop分布式文件系统(HDFS):支持对应用数据高吞吐量访问的分 ...
- Hadoop 生态系统
1.概述 最近收到一些同学和朋友的邮件,说能不能整理一下 Hadoop 生态圈的相关内容,然后分享一些,我觉得这是一个不错的提议,于是,花了一些业余时间整理了 Hadoop 的生态系统,并将其进行了归 ...
- 从问题域出发认识Hadoop生态系统
近些年来Hadoop生态系统发展迅猛,它本身包含的软件越来越多,同时带动了周边系统的繁荣发展.尤其是在分布式计算这一领域,系统繁多纷杂,时不时冒出一个系统,号称自己比MapReduce或者Hive高效 ...
- hadoop生态系统的详细介绍
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YAR ...
- hadoop 之Hadoop生态系统
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YAR ...
- 04_Apache Hadoop 生态系统
内容提纲: 1)对 Apache Hadoop 生态系统的认识(Hadoop 1.x 和 Hadoop 2.x) 2) Apache Hadoop 1.x 框架架构原理的初步认识 3) Apache ...
- Hadoop概念学习系列之Hadoop 生态系统
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Apache Kudu: Hadoop生态系统的新成员实现对快速数据的快速分析
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop's storage la ...
随机推荐
- Palindrome Number 2015年6月23日
题目: 判断一个数是不是回文数 Determine whether an integer is a palindrome. Do this without extra space. 思路:借助上一道求 ...
- TCP/UDP客户端
Python 网络编程----模块socekt 在渗透测试的过程中,经常会遇到需要创建一个TCP客户端来连接服务器.发送垃圾数据.进行模糊测试活进行其他任务的情况. 简单的TCP客户端代码: #!/u ...
- THE R QGRAPH PACKAGE: USING R TO VISUALIZE COMPLEX RELATIONSHIPS AMONG VARIABLES IN A LARGE DATASET, PART ONE
The R qgraph Package: Using R to Visualize Complex Relationships Among Variables in a Large Dataset, ...
- 安装lnmp集成环境
具体配置看原文,不重新复述: 原文:https://lnmp.org/install.html 因为配置数据库主从,需要保持两台mysql数据库服务器的mysql版本号一致,所以又重新装了一次..重新 ...
- QT环境的搭建
说到QT大家一定要先了解到底什么是QT,我们通常说的QT是包括:Qt-creactor的集成开发环境(IDE)和Qt的开发工具包(SDK),而Qt-creactor就相当于我们的visio studi ...
- javaSE_07Java中类和对象-封装特性--练习
1.编写封装一个学生类,有姓名,有年龄,有性别,有英语成绩,数学成绩,语文成绩,一个学生类,我们关注姓名,年龄,学历等信息,要求年龄必须在19-40岁之间,默认为19,学历必须是大专,本科,研究生这几 ...
- Ionic3新特性--页面懒加载2加载其他组件
在第一节中,我们介绍了页面的懒加载方式,并进行了初步的分析,这里,我们将进一步介绍如何配合页面懒加载进行其他组件Component.Pipe.Directive等的模块化,和加载使用. 首先说明一点, ...
- Nmap原理-01选项介绍
Nmap原理-01选项介绍 1.Nmap原理图 Nmap包含四项基本功能:主机发现/端口扫描/版本探测/操作系统探测.这四项功能之间存在大致的依赖关系,比如图片中的先后关系,除此之外,Nmap还提供规 ...
- Elasticsearch索引和文档操作
列出所有索引 现在来看看我们的索引 GET /_cat/indices?v 响应 health status index uuid pri rep docs.count docs.deleted st ...
- 11.并发包阻塞队列之LinkedBlockingQueue
在上文<10.并发包阻塞队列之ArrayBlockingQueue>中简要解析了ArrayBlockingQueue部分源码,在本文中同样要介绍的是Java并发包中的阻塞队列LinkedB ...