Storm-wordcount实时统计单词次数
一、本地模式
1、WordCountSpout类
package com.demo.wc; import java.util.Map; import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values; /**
* 需求:单词计数 hello world hello Beijing China
*
* 实现接口: IRichSpout IRichBolt
* 继承抽象类:BaseRichSpout BaseRichBolt 常用*/
public class WordCountSpout extends BaseRichSpout { //定义收集器
private SpoutOutputCollector collector; //发送数据
@Override
public void nextTuple() {
//1.发送数据 到bolt
collector.emit(new Values("I like China very much")); //2.设置延迟
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
} //创建收集器
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
this.collector = collector;
} //声明描述
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//起别名
declarer.declare(new Fields("wordcount"));
}
}
2、WordCountSplitBolt类
package com.demo.wc; import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; public class WordCountSplitBolt extends BaseRichBolt { //数据继续发送到下一个bolt
private OutputCollector collector; //业务逻辑
@Override
public void execute(Tuple in) {
//1.获取数据
String line = in.getStringByField("wordcount"); //2.切分数据
String[] fields = line.split(" "); //3.<单词,1> 发送出去 下一个bolt(累加求和)
for (String w : fields) {
collector.emit(new Values(w, 1));
}
} //初始化
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector = collector;
} //声明描述
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "sum"));
}
}
3、WordCountBolt类
package com.demo.wc; import java.util.HashMap;
import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple; public class WordCountBolt extends BaseRichBolt{ private Map<String, Integer> map = new HashMap<>(); //累加求和
@Override
public void execute(Tuple in) {
//1.获取数据
String word = in.getStringByField("word");
Integer sum = in.getIntegerByField("sum"); //2.业务处理
if (map.containsKey(word)) {
//之前出现几次
Integer count = map.get(word);
//已有的
map.put(word, count + sum);
} else {
map.put(word, sum);
} //3.打印控制台
System.out.println(Thread.currentThread().getName() + "\t 单词为:" + word + "\t 当前已出现次数为:" + map.get(word));
} @Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector arg2) {
} @Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}
4、WordCountDriver类
package com.demo.wc; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields; public class WordCountDriver {
public static void main(String[] args) {
//1.hadoop->Job storm->topology 创建拓扑
TopologyBuilder builder = new TopologyBuilder();
//2.指定设置
builder.setSpout("WordCountSpout", new WordCountSpout(), 1);
builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(), 4).fieldsGrouping("WordCountSpout", new Fields("wordcount"));
builder.setBolt("WordCountBolt", new WordCountBolt(), 2).fieldsGrouping("WordCountSplitBolt", new Fields("word")); //3.创建配置信息
Config conf = new Config(); //4.提交任务
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcounttopology", conf, builder.createTopology());
}
}
5、直接运行(4)里面的main方法即可启动本地模式。
二、集群模式
前三个类和上面本地模式一样,第4个类WordCountDriver和本地模式有点区别
package com.demo.wc; import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields; public class WordCountDriver {
public static void main(String[] args) {
//1.hadoop->Job storm->topology 创建拓扑
TopologyBuilder builder = new TopologyBuilder();
//2.指定设置
builder.setSpout("WordCountSpout", new WordCountSpout(), 1);
builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(), 4).fieldsGrouping("WordCountSpout", new Fields("wordcount"));
builder.setBolt("WordCountBolt", new WordCountBolt(), 2).fieldsGrouping("WordCountSplitBolt", new Fields("word")); //3.创建配置信息
Config conf = new Config();
//conf.setNumWorkers(10); //集群模式
try {
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
} //4.提交任务
//LocalCluster localCluster = new LocalCluster();
//localCluster.submitTopology("wordcounttopology", conf, builder.createTopology());
}
}
把程序打成jar包放在启动了Storm集群的机器里,在stormwordcount.jar所在目录下执行
storm jar stormwordcount.jar com.demo.wc.WordCountDriver wordcount01
即可启动程序。
三、并发度和分组策略
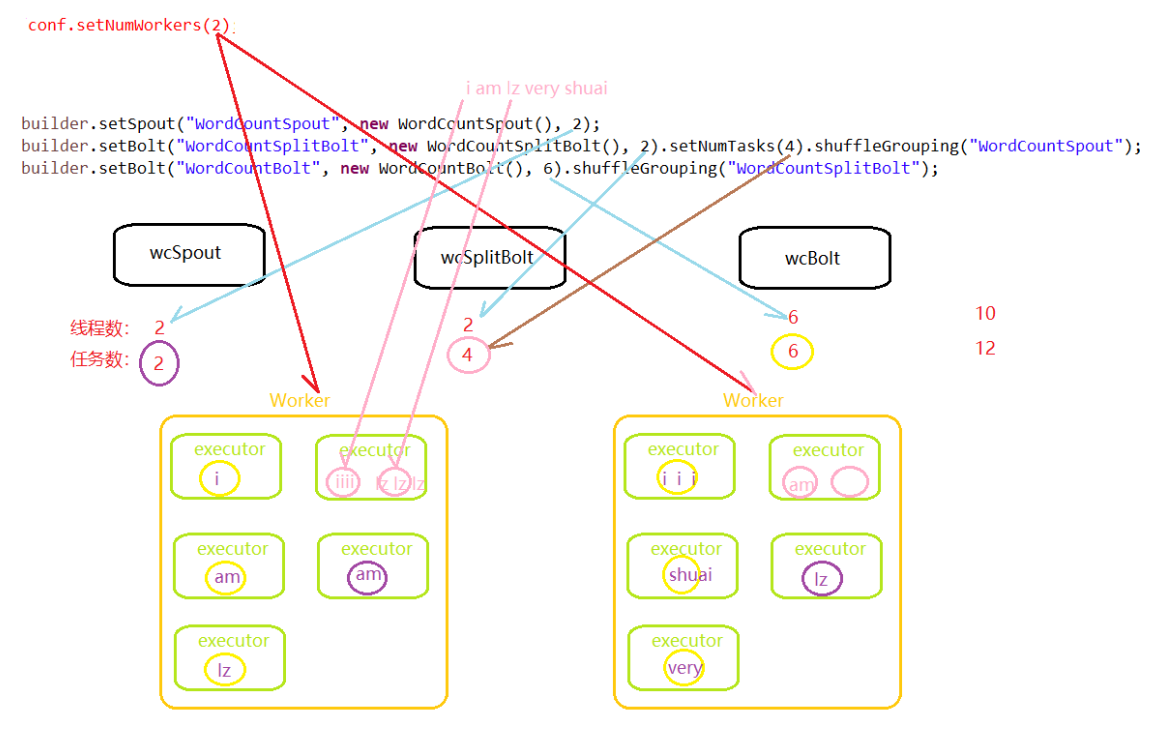
1、WordCountDriver_Shuffle类
package com.demo.wc; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder; public class WordCountDriver_Shuffle {
public static void main(String[] args) {
//1.hadoop->Job storm->topology 创建拓扑
TopologyBuilder builder = new TopologyBuilder();
//2.指定设置
builder.setSpout("WordCountSpout", new WordCountSpout(), 2);
builder.setBolt("WordCountSplitBolt", new WordCountSplitBolt(), 2).setNumTasks(4).shuffleGrouping("WordCountSpout");
builder.setBolt("WordCountBolt", new WordCountBolt(), 6).shuffleGrouping("WordCountSplitBolt"); //3.创建配置信息
Config conf = new Config();
//conf.setNumWorkers(2); //集群模式
// try {
// StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
// } catch (Exception e) {
// e.printStackTrace();
// } //4.提交任务
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcounttopology", conf, builder.createTopology());
}
}
2、并发度与分组策略
Storm-wordcount实时统计单词次数的更多相关文章
- lucene 统计单词次数(词频tf)并进行排序
public class WordCount { static Directory directory; // 创建分词器 static Analyzer analyzer = new IKAnaly ...
- 大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)
1. Spark Streaming 1.1 简介(来源:spark官网介绍) Spark Streaming是Spark Core API的扩展,其是支持可伸缩.高吞吐量.容错的实时数据流处理.Sp ...
- Storm基础概念与单词统计示例
Storm基本概念 Storm是一个分布式的.可靠地.容错的数据流处理系统.Storm分布式计算结构称为Topology(拓扑)结构,顾名思义,与拓扑图十分类似.该拓扑图主要由数据流Stream.数据 ...
- Storm+HBase实时实践
1.HBase Increment计数器 hbase counter的原理: read+count+write,正好完成,就是讲key的value读出,若存在,则完成累加,再写入,若不存在,则按&qu ...
- 3、SpringBoot 集成Storm wordcount
WordCountBolt public class WordCountBolt extends BaseBasicBolt { private Map<String,Integer> c ...
- Storm WordCount Topology学习
1,分布式单词计数的流程 首先要有数据源,在SentenceSpout中定义了一个字符串数组sentences来模拟数据源.字符串数组中的每句话作为一个tuple发射.其实,SplitBolt接收Se ...
- 使用HDFS完成wordcount词频统计
任务需求 统计HDFS上文件的wordcount,并将统计结果输出到HDFS 功能拆解 读取HDFS文件 业务处理(词频统计) 缓存处理结果 将结果输出到HDFS 数据准备 事先往HDFS上传需要进行 ...
- C++读取文件统计单词个数及频率
1.Github链接 GitHub链接地址https://github.com/Zzwenm/PersonProject-C2 2.PSP表格 PSP2.1 Personal Software Pro ...
- Hadoop基础学习(一)分析、编写并执行WordCount词频统计程序
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jiq408694711/article/details/34181439 前面已经在我的Ubuntu ...
随机推荐
- jquery easy ui 验证框架
引入参考最下面API ) var reg = /^1[3|4|5|8|9]\d{9}$/; return reg.test(value); }, message: '输入手机号码格式不准确.' } } ...
- 用广搜实现的spfa
用广搜实现的spfa,如果是用一般的最短路,会发现构图很麻烦,因为它不是路径带权值,而是自身带权值.写起来只要注意,在点出队列的生活将其标记为0,在要压入队列的时候,判断其标记是否为0,为0表示队列中 ...
- 教程-Delphi中的GExperts搜索代码快捷键
Shift+Ait+S 打开搜索 Ctrl+Ait+R 打开上次搜索结果
- C++-教程3-VS2010C++各种后缀说明
相关资料:"http://blog.csdn.net/kibaamor/article/details/18700607""http://blog.chinaunix.n ...
- js鼠标触发事件集合
转载自:http://blog.sina.com.cn/s/blog_627002d101010yb7.html 事件 浏览器支持 解说 一般事件 onclick IE3.N2 鼠标点击时触发此事件 ...
- 【BZOJ】1691: [Usaco2007 Dec]挑剔的美食家(set+贪心)
http://www.lydsy.com/JudgeOnline/problem.php?id=1691 懒得打平衡树了.... 而且multiset是很快的... 排到了rank1 T_T 贪心就是 ...
- Xcode升级后插件失败解决方法
大家都知道每次升级Xcode 然后插件都不能用了,最根本的原因是每一个插件都有个Info.plist文件,这个文件里有个key-DVTPlugInCompatibilityUUIDs记录了能够使用该插 ...
- python爬虫<urlopen error [Errno 10061] >
在网上看了十几篇文章,都是说的是IE的代理设置,具体是: Tools->Internet Options->Connections->Lan Settings 将代理服务器的小勾勾去 ...
- 《随机出题软件》&《随机分队软件》源码(Windows API)
1 引言 1.1 编写目的: 为了对院级活动<最强大脑>提供软件支持,同时为了练习使用windows API. 1.2 项目背景: 来自计算机学院学生会信息部指派的任务,规定时间完成软件的 ...
- KVC/KVO之暴力的KVC
本章将分为三个部分: KVC是什么 KVC之Set/Get KVC键值路径之Set/Get KVC是什么 KVC,即 NSKeyValueCoding,一个非正式的 Protocol,提供一种机制来间 ...