lucene 统计单词次数(词频tf)并进行排序
public class WordCount {
static Directory directory;
// 创建分词器
static Analyzer analyzer = new IKAnalyzer();
static IndexWriterConfig config = new IndexWriterConfig(analyzer);
static IndexWriter writer;
static IndexReader reader;
static {
// 指定索引存放目录以及配置参数
try {
directory = FSDirectory.open(Paths.get("F:/luceneIndex"));
writer = new IndexWriter(directory, config);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
indexCreate();
Map<String, Long> map = getTotalFreqMap();
Map<String, Long> sortMap = sortMapByValue(map);
Set<Entry<String, Long>> entrySet = sortMap.entrySet();
Iterator<Entry<String, Long>> iterator = entrySet.iterator();
while (iterator.hasNext()) {
Entry<String, Long> entry = iterator.next();
System.out.println(entry.getKey() + "----" + entry.getValue());
}
}
/**
* 创建索引
*/
public static void indexCreate() {
// 文件夹检测(创建索引前要保证目录是空的)
File file = new File("f:/luceneIndex");
if (!file.exists()) {
file.mkdirs();
} else {
try {
file.delete();
} catch (Exception e) {
e.printStackTrace();
}
}
// 将采集的数据封装到Document中
Document doc = new Document();
FieldType ft = new FieldType();
ft.setIndexOptions(IndexOptions.DOCS_AND_FREQS);
ft.setStored(true);
ft.setStoreTermVectors(true);
ft.setTokenized(true);
// ft.setStoreTermVectorOffsets(true);
// ft.setStoreTermVectorPositions(true);
// 读取文件内容(小文件,readFully)
File content = new File("f:/qz/twitter.txt");
try {
byte[] buffer = new byte[(int) content.length()];
IOUtils.readFully(new FileInputStream(content), buffer);
doc.add(new Field("twitter", new String(buffer), ft));
} catch (Exception e) {
e.printStackTrace();
}
// 生成索引
try {
writer.addDocument(doc);
// 关闭
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 获得词频map
*
* @throws ParseException
*/
public static Map<String, Long> getTotalFreqMap() {
Map<String, Long> map = new HashMap<String, Long>();
try {
reader = DirectoryReader.open(directory);
List<LeafReaderContext> leaves = reader.leaves();
for (LeafReaderContext leafReaderContext : leaves) {
LeafReader leafReader = leafReaderContext.reader();
Terms terms = leafReader.terms("twitter");
TermsEnum iterator = terms.iterator();
BytesRef term = null;
while ((term = iterator.next()) != null) {
String text = term.utf8ToString();
map.put(text, iterator.totalTermFreq());
}
}
reader.close();
return map;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 使用 Map按value进行排序
*
* @param map
* @return
*/
public static Map<String, Long> sortMapByValue(Map<String, Long> oriMap) {
if (oriMap == null || oriMap.isEmpty()) {
return null;
}
Map<String, Long> sortedMap = new LinkedHashMap<String, Long>();
List<Map.Entry<String, Long>> entryList = new ArrayList<Map.Entry<String, Long>>(oriMap.entrySet());
Collections.sort(entryList, new MapValueComparator());
Iterator<Map.Entry<String, Long>> iter = entryList.iterator();
Map.Entry<String, Long> tmpEntry = null;
while (iter.hasNext()) {
tmpEntry = iter.next();
sortedMap.put(tmpEntry.getKey(), tmpEntry.getValue());
}
return sortedMap;
}
}
class MapValueComparator implements Comparator<Map.Entry<String, Long>> {
@Override
public int compare(Entry<String, Long> me1, Entry<String, Long> me2) {
if (me1.getValue() == me2.getValue()) {
return ;
}
return me1.getValue() > me2.getValue() ? - : ;
// return me1.getValue().compareTo(me2.getValue());
}
}
map排序代码https://www.cnblogs.com/zhujiabin/p/6164826.html
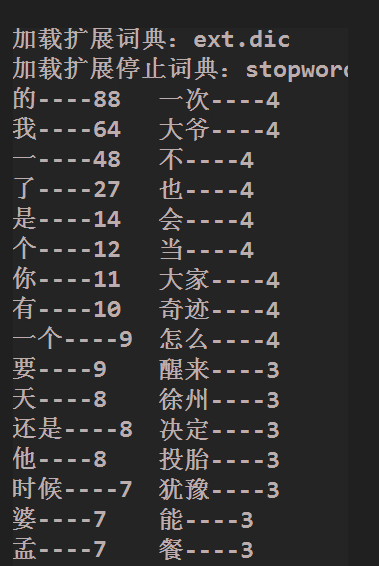
lucene 统计单词次数(词频tf)并进行排序的更多相关文章
- Storm-wordcount实时统计单词次数
一.本地模式 1.WordCountSpout类 package com.demo.wc; import java.util.Map; import org.apache.storm.spout.Sp ...
- C++读取文件统计单词个数及频率
1.Github链接 GitHub链接地址https://github.com/Zzwenm/PersonProject-C2 2.PSP表格 PSP2.1 Personal Software Pro ...
- python 统计单词个数
根据一篇英文文章统计其中单词出现最多的10个单词. # -*- coding: utf-8 -*-import urllib2import refrom collections import Coun ...
- 洛谷 P1308 统计单词数【字符串+模拟】
P1308 统计单词数 题目描述 一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数. 现在,请你编程实现这一功能,具体要求是:给定 ...
- 统计单词Java
功能0:输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位. 功能1:输出文件中所有不重复的单词,按照出现次数由多到少排列,出现次数同样多的,以字 ...
- [luogu]P1026 统计单词个数[DP][字符串]
[luogu]P1026 统计单词个数 题目描述 给出一个长度不超过200的由小写英文字母组成的字母串(约定;该字串以每行20个字母的方式输入,且保证每行一定为20个).要求将此字母串分成k份(1&l ...
- 第六章 第一个Linux驱动程序:统计单词个数
现在进入了实战阶段,使用统计单词个数的实例让我们了解开发和测试Linux驱动程序的完整过程.第一个Linux驱动程序是统计单词个数. 这个Linux驱动程序没有访问硬件,而是利用设备文件作为介质与应用 ...
- 第六章第一个linux个程序:统计单词个数
第六章第一个linux个程序:统计单词个数 从本章就开始激动人心的时刻——实战,去慢慢揭开linux神秘的面纱.本章的实例是统计一片文章或者一段文字中的单词个数. 第 1 步:建立 Linu x 驱 ...
- Java web--Filter过滤器分IP统计访问次数
分IP统计访问次数即网站统计每个IP地址访问本网站的次数. 分析 因为一个网站可能有多个页面,无论哪个页面被访问,都要统计访问次数,所以使用过滤器最为方便. 因为需要分IP统计,所以可以在过滤器中创建 ...
随机推荐
- Hbase技术详细学习笔记
注:转自 Hbase技术详细学习笔记 最近在逐步跟进Hbase的相关工作,由于之前对Hbase并不怎么了解,因此系统地学习了下Hbase,为了加深对Hbase的理解,对相关知识点做了笔记,并在组内进行 ...
- SQL server 错误代码对比表
0 操作成功完毕. 1 功能错误. 2 系统找不到指定的文件. 3 系统找不到指定的路径. 4 系统无法打开文件. 5 拒绝訪问. 6 句柄无效. ...
- 单位转换 inch mm mil
从上面看:英寸(inch)是最大的单位 其次是毫米(mm) 再次是密耳(mil)
- 使用mingw制作dll文件
使用mingw制作dll文件 安装mingw 准备math.c文件 //math.c #include<stdio.h> int add(int a,int b){ return a+b; ...
- 将html转换为word文档的几种方式
1 基于wps直接将页面信息下载成word文档 public void test() { WPS.Application wps = null; try { wps = new WPS.Applica ...
- PL/SQL笔记(一)
PL/SQL概述 PL/SQL是一种高级的数据库程序设计语言,专门使用与Oracle语言基于数据库的服务器的内部,所以PL/SQL代码可以对数据库进行快速的处理. 1.什么是PL/SQL? PL/SQ ...
- 【rlz03】十六进制转十进制
Time Limit: 3 second Memory Limit: 2 MB 问题描述 输入一个十六进制数,编程转换为十进制数. 整数部分不会超过65535,十六进制的小数部分不会超过2位. Sam ...
- 2020发布 .NET 5 下一代全平台 .Net 框架
[翻译] 正式宣布 .NET 5 2019-05-07 01:18 by Rwing, 16515 阅读, 79 评论, 收藏, 编辑 原文: Introducing .NET 5 今天,我们宣布 . ...
- Fragment之一:Fragment入门 分类: H1_ANDROID 2013-11-15 18:16 2799人阅读 评论(2) 收藏
参考自张泽华视频 Fragment是自Android3.0后引入的特性,主要用于在不同的屏幕尺寸中展现不同的内容. Fragment必须被嵌入Activity中使用,总是作为Activity的组成部分 ...
- Oracle 字符集的查看和修改 分类: H2_ORACLE 2013-06-19 16:52 316人阅读 评论(0) 收藏
一.什么是Oracle字符集 Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系.ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据.它使数据库 ...