hadoop-eclipse环境搭建(二)
Eclipse插件配置
第一步:把我们的"hadoop-eclipse-plugin-1.0.0.jar"放到Eclipse的目录的"plugins"中,然后重新Eclipse即可生效。
上面是我的"hadoop-eclipse-plugin"插件放置的地方。重启Eclipse如下图:
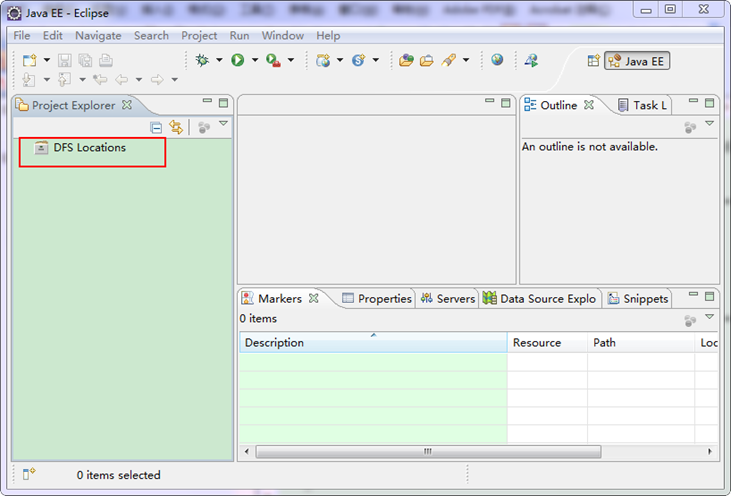
第二步:选择"Window"菜单下的"Preference",然后弹出一个窗体,在窗体的左侧,有一列选项,里面会多出"Hadoop Map/Reduce"选项,点击此选项,选择Hadoop的安装目录(如我的Hadoop目录:E:\HadoopWorkPlat\hadoop-1.0.0)。结果如下图:
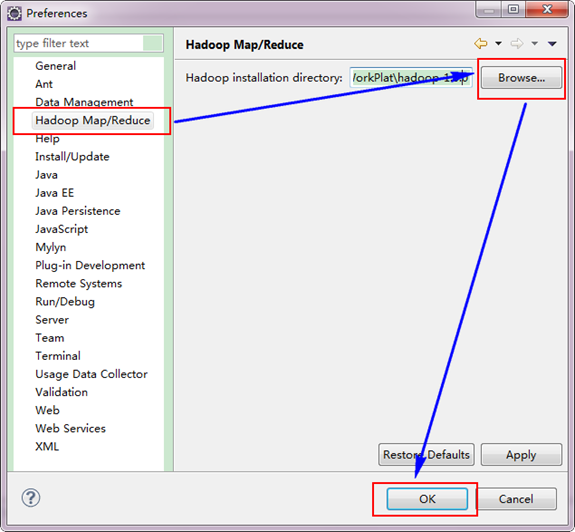
第三步:切换"Map/Reduce"工作目录,有两种方法:
1)选择"Window"菜单下选择"Open Perspective",弹出一个窗体,从中选择"Map/Reduce"选项即可进行切换。
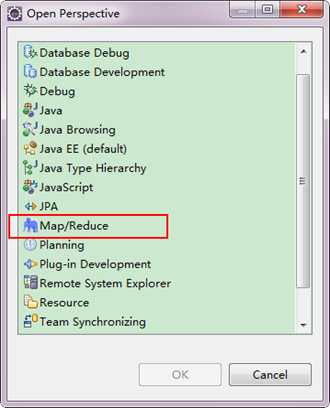
2)在Eclipse软件的右上角,点击图标" "中的"
"中的" ",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
切换到"Map/Reduce"工作目录下的界面如下图所示。
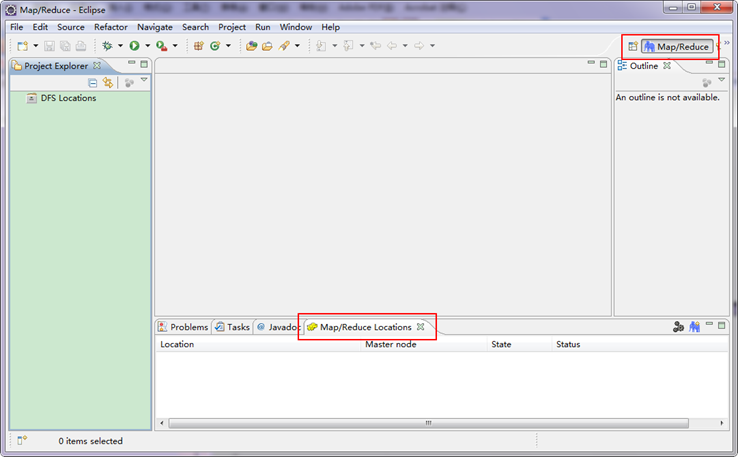
第四步:建立与Hadoop集群的连接,在Eclipse软件下面的"Map/Reduce Locations"进行右击,弹出一个选项,选择"New Hadoop Location",然后弹出一个窗体。

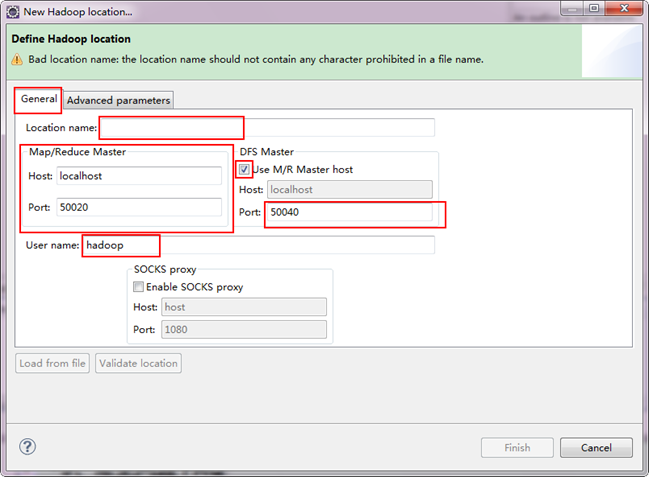
注意上图中的红色标注的地方,是需要我们关注的地方。
- Location Name:可以任意其,标识一个"Map/Reduce Location"
- Map/Reduce Master
Host:192.168.1.2(Master.Hadoop的IP地址)
Port:9001
- DFS Master
Use M/R Master host:前面的勾上。(因为我们的NameNode和JobTracker都在一个机器上。)
Port:9000
- User name:hadoop(默认为Win系统管理员名字,因为我们之前改了所以这里就变成了hadoop。)
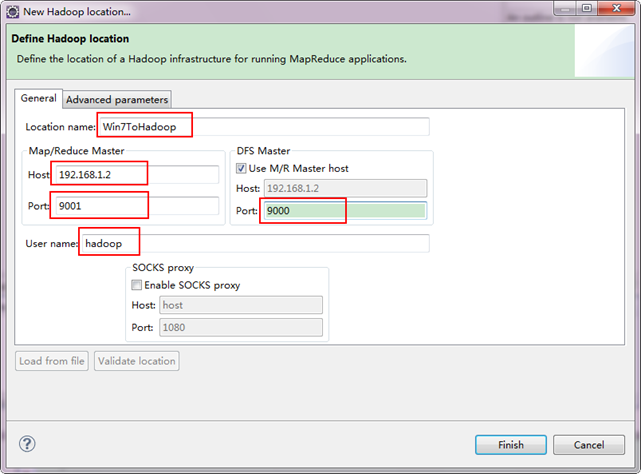
备注:这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。不清楚的可以参考"Hadoop集群_第5期_Hadoop安装配置_V1.0"进行查看。
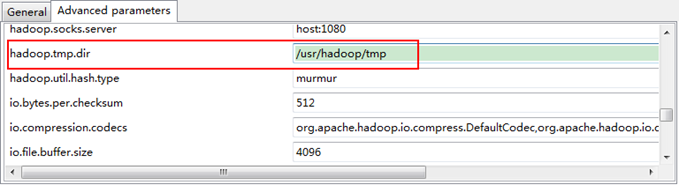
接着点击"Advanced parameters"从中找见"hadoop.tmp.dir",修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是"/usr/hadoop/tmp",这个参数在"core-site.xml"进行了配置。
点击"finish"之后,会发现Eclipse软件下面的"Map/Reduce Locations"出现一条信息,就是我们刚才建立的"Map/Reduce Location"。

第五步:查看HDFS文件系统,并尝试建立文件夹和上传文件。点击Eclipse软件左侧的"DFS Locations"下面的"Win7ToHadoop",就会展示出HDFS上的文件结构。
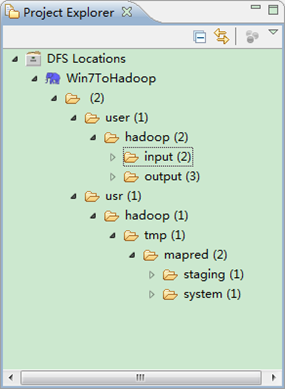
用SecureCRT远程登录"Master.Hadoop"服务器,用下面命令查看是否已经建立一个的文件夹。
hadoop fs -ls
到此为止,我们的Hadoop Eclipse开发环境已经配置完毕,不尽兴的同学可以上传点本地文件到HDFS分布式文件上,可以互相对比意见文件是否已经上传成功。
2、Eclipse上运行WordCount
创建MapReduce项目
从"File"菜单,选择"Other",找到"Map/Reduce Project",然后选择它。
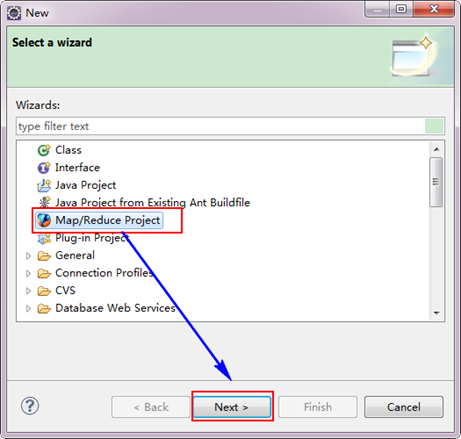
接着,填写MapReduce工程的名字为"WordCountProject",点击"finish"完成。
目前为止我们已经成功创建了MapReduce项目,我们发现在Eclipse软件的左侧多了我们的刚才建立的项目。
建立一个启动类 test包下面的A
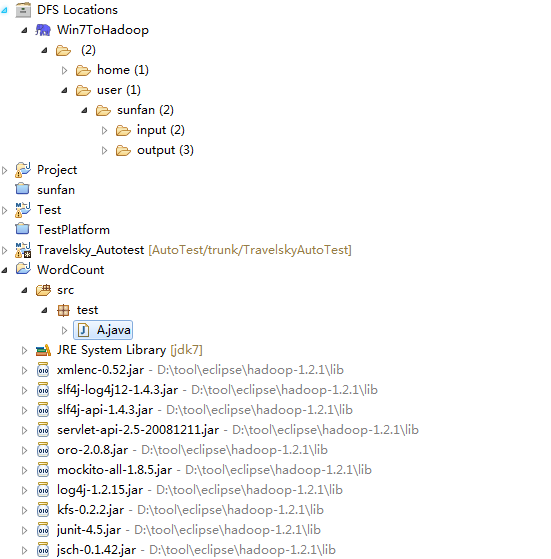
3.4 创建A类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.examples.WordCount;
import org.apache.hadoop.examples.WordCount.IntSumReducer;
import org.apache.hadoop.examples.WordCount.TokenizerMapper;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class A {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "192.168.1.100:9001");
String[] addrs = new String[] { "hdfs://192.168.1.100:9000/user/sunfan/input", "hdfs://192.168.1.100:9000/user/sunfan/out3" };
String[] otherArgs = new GenericOptionsParser(conf, addrs).getRemainingArgs();
if (otherArgs.length != ) {
System.err.println("Usage: wordcount <in> <out>");
System.exit();
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[]));
System.exit(job.waitForCompletion(true) ? : );
}
}
运行
// :: INFO input.FileInputFormat: Total input paths to process :
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: WARN snappy.LoadSnappy: Snappy native library not loaded
// :: INFO mapred.JobClient: Running job: job_201502181818_0033
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: map % reduce %
// :: INFO mapred.JobClient: Job complete: job_201502181818_0033
// :: INFO mapred.JobClient: Counters:
// :: INFO mapred.JobClient: Job Counters
// :: INFO mapred.JobClient: Launched reduce tasks=
// :: INFO mapred.JobClient: SLOTS_MILLIS_MAPS=
// :: INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=
// :: INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=
// :: INFO mapred.JobClient: Launched map tasks=
// :: INFO mapred.JobClient: Data-local map tasks=
// :: INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=
// :: INFO mapred.JobClient: File Output Format Counters
// :: INFO mapred.JobClient: Bytes Written=
// :: INFO mapred.JobClient: FileSystemCounters
// :: INFO mapred.JobClient: FILE_BYTES_READ=
// :: INFO mapred.JobClient: HDFS_BYTES_READ=
// :: INFO mapred.JobClient: FILE_BYTES_WRITTEN=
// :: INFO mapred.JobClient: HDFS_BYTES_WRITTEN=
// :: INFO mapred.JobClient: File Input Format Counters
// :: INFO mapred.JobClient: Bytes Read=
// :: INFO mapred.JobClient: Map-Reduce Framework
// :: INFO mapred.JobClient: Map output materialized bytes=
// :: INFO mapred.JobClient: Map input records=
// :: INFO mapred.JobClient: Reduce shuffle bytes=
// :: INFO mapred.JobClient: Spilled Records=
// :: INFO mapred.JobClient: Map output bytes=
// :: INFO mapred.JobClient: CPU time spent (ms)=
// :: INFO mapred.JobClient: Total committed heap usage (bytes)=
// :: INFO mapred.JobClient: Combine input records=
// :: INFO mapred.JobClient: SPLIT_RAW_BYTES=
// :: INFO mapred.JobClient: Reduce input records=
// :: INFO mapred.JobClient: Reduce input groups=
// :: INFO mapred.JobClient: Combine output records=
// :: INFO mapred.JobClient: Physical memory (bytes) snapshot=
// :: INFO mapred.JobClient: Reduce output records=
// :: INFO mapred.JobClient: Virtual memory (bytes) snapshot=
// :: INFO mapred.JobClient: Map output records=
本文前半部分引用 http://www.cnblogs.com/xia520pi/archive/2012/04/08/2437875.html,感谢原作者。
hadoop-eclipse环境搭建(二)的更多相关文章
- Eclipse环境搭建并且运行wordcount程序
一.安装Hadoop插件 1. 所需环境 hadoop2.0伪分布式环境平台正常运行 所需压缩包:eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz 在Linu ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- Hadoop —— 单机环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
- Hadoop 系列(四)—— Hadoop 开发环境搭建
一.前置条件 Hadoop 的运行依赖 JDK,需要预先安装,安装步骤见: Linux 下 JDK 的安装 二.配置免密登录 Hadoop 组件之间需要基于 SSH 进行通讯. 2.1 配置映射 配置 ...
- Hadoop之环境搭建
初学Hadoop之环境搭建 阅读目录 1.安装CentOS7 2.安装JDK1.7.0 3.安装Hadoop2.6.0 4.SSH无密码登陆 本文仅作为学习笔记,供大家初学Hadoop时学习参考. ...
- Java学习不走弯路教程(7.Eclipse环境搭建)
7.Eclipse环境搭建 在前几章,我们熟悉了DOS环境下编译和运行Java程序,对于大规模的程序编写,开发工具是必不可少的.Java的开发工具比较常用的是Eclipse.在接下来的教程中,我们将基 ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- scala 入门Eclipse环境搭建
scala 入门Eclipse环境搭建及第一个入门经典程序HelloWorld IDE选择并下载: scala for eclipse 下载: http://scala-ide.org/downloa ...
- odoo开发环境搭建(二):安装Ubuntu 17虚拟机
odoo开发环境搭建(二):安装Ubuntu 17虚拟机 下载镜像文件: 配置网络: 安装vmware tools: 配置共享文件夹: 选中虚拟机,右键编辑设置里边配置共享文件夹,指定windows本 ...
随机推荐
- Python 爬虫的工具列表
这个列表包含与网页抓取和数据处理的Python库 网络 通用 urllib -网络库(stdlib). requests -网络库. grab - 网络库(基于pycurl). pycurl - 网络 ...
- 继承FileInputFormat类来理解 FileInputFormat类
import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.had ...
- 项目部署到自己的IIS上
一般我们只能在本机上才可以开到我们的项目,这个是不需要连网的 如果想让我们的项目在网站中打开,别人也可以看到,就需要把我们的项目部署到服务器上了,输入IP就可以看到我们的项目 发布项目 然后发布网站 ...
- 开发SDK注意事项
1. 修改类别文件名及类别方法. 开发SDK时通常会用到比较多的第三方的类别方法, 这样的话, 开发者在使用你的SDK时, 因为他可能也会加一些第三方的开源库, 比如都使用了NSString的md5类 ...
- 在github上查找star最多的项目
如何在github上查找star最多的项目 在search中输入stars:>1 就可以查找所有有star的项目,然后右上角根据自己的需要筛选 当我输入stars:>10000的时候,就会 ...
- CSS设置背景透明字体不透明
写CSS时给容器设置透明度的时候如果使用background-color: #000000; opacity: 0.5;这时会出现容器里的文字也跟着透明.解决办法是不用十六进制的色值和透明度分开写,使 ...
- Python函数及参数
## 函数 - 函数是代码的一种组织形式,一般一个函数完成一个特定功能 - 函数需要先定义后使用 - 函数的定义 def func_name(参数): func_body ... return fun ...
- NC-瑞士军刀NetCat
NC——Telnet/Banner 连接之后可以命令互动,比如POP3\SMTP\HTTP等协议命令 root@kali:/# nc -v pop3..com //-v详细显示 DNS fwd/rev ...
- 9 10mins的投票功能
1.投票的原理 2.投票的数据结构设计 (1)准备工作 导入detail页面 配置静态文件 <link rel="stylesheet" href="../stat ...
- Java中的初始化详细解析
今天所要详细讲解的是Java中的初始化,也就是new对象的过程中,其程序的行走流程. 先说没有静态成员变量和静态代码块的情况. public class NormalInit { public sta ...