分类问题(一)MINST数据集与二元分类器
分类问题
在机器学习中,主要有两大类问题,分别是分类和回归。下面我们先主讲分类问题。
MINST
这里我们会用MINST数据集,也就是众所周知的手写数字集,机器学习中的 Hello World。sk-learn 提供了用于直接下载此数据集的方法:
from sklearn.datasets import fetch_openml
minst = fetch_openml('mnist_784', version=1)
minst.keys()
>dict_keys(['data', 'target', 'feature_names', 'DESCR', 'details', 'categories', 'url'])
像这种sk-learn 下载的数据集,一般都有相似的字典结构,包括:
- DESCR:描述数据集
- data:包含一个数组,每行是一条数据,每列是一个特征
- target:包含一个数组,为label值
我们看一下这些数组:
X,y = minst['data'],minst['target']
X.shape, y.shape
>((70000, 784), (70000,))
可以看到一共有 70000 张图片,每张图片包含784个特征。这是因为每张图包含28×28像素点,每个特征代表的是此像素点强度,取值范围从0(白)到255(黑)。我们先看一下其中一条数据。首先获取一条数据的特征向量,然后reshape到一个28×28 的数组,最后用matplotlib 的imshow() 方法显示即可:
import matplotlib as mpl
import matplotlib.pyplot as plt some_digit = X[0]
some_digit_image = some_digit.reshape(28, 28) plt.imshow(some_digit_image, cmap = mpl.cm.binary, interpolation="nearest")
plt.axis("off")
plt.show()
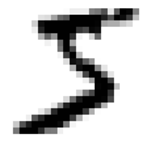
从图片来看,这个应该是数字5,我们可以通过label 进行验证:
y[0]
>''
可以看到这个label的数值是 string,我们需要将它们转换成int:
import numpy as np y = y.astype(np.uint8)
>array([5, 0, 4, ..., 4, 5, 6], dtype=uint8)
现在,我们初步了解了数据集。在训练之前,必须要将数据集分为训练集与测试集。这个MINST数据集已经做好了划分,前60000 为训练接,后10000为测试集,直接取用即可:
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
这个训练集已经做过了shuffle,基本可以确保k-折交叉验证的各个集合基本相似(例如不会出现某个折中缺失一些数字)。另一方面,有些学习算法对于训练数据的顺序比较敏感,所以对数据集进行shuffle的好处是避免数据的顺序对训练造成的影响。
训练二元分类器
我们先简化此问题,仅让我们的模型判断一个数字,例如5。这样的分类器称为二元分类器,仅能将数据分为两个类别:数字5和非数字5。下面我们为这类分类器创建label:
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
现在我们选择一个分类器并进行训练,可以先从一个随机梯度下降(Stochastic Gradient Descent,SGD) 分类器开始,使用sk-learn的SGDClassifer 类。这个分类器的优点是:能够高效地处理非常大的数据集。因为它每次均仅处理一条数据(也正因如此,SGD非常适合online learning 场景)。下面创建一个SGDClassifer 并在整个训练集上进行训练:
from sklearn.linear_model import SGDClassifier sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
SGDClassifier在训练时会随机选择数据,如果要复现结果的话,则需要手动设置random_state 参数。现在我们可以使用已训练好的模型进行预测一个手写数字是否是5:
sgd_clf.predict([X_test[0], X_test[1], X_test[2]])
>array([False, False, False])
看起来结果还不错,我们稍后评估一下这个模型的性能。
分类问题(一)MINST数据集与二元分类器的更多相关文章
- Softmax 回归 vs. k 个二元分类器
如果你在开发一个音乐分类的应用,需要对k种类型的音乐进行识别,那么是选择使用 softmax 分类器呢,还是使用 logistic 回归算法建立 k 个独立的二元分类器呢? 这一选择取决于你的类别之间 ...
- 神经网络中的Heloo,World,基于MINST数据集的LeNet
前言 最近刚开始接触机器学习,记录下目前的一些理解,以及看到的一些好文章mark一下 1.MINST数据集 MNIST 数据集来自美国国家标准与技术研究所, National Institute of ...
- 3.Minst数据集分类
import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.mode ...
- 电影评论分类:二分类问题(IMDB数据集)
IMDB数据集是Keras内部集成的,初次导入需要下载一下,之后就可以直接用了. IMDB数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的250 ...
- ML.NET 示例:二元分类之垃圾短信检测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- PyTorch迁移学习-私人数据集上的蚂蚁蜜蜂分类
迁移学习的两个主要场景 微调CNN:使用预训练的网络来初始化自己的网络,而不是随机初始化,然后训练即可 将CNN看成固定的特征提取器:固定前面的层,重写最后的全连接层,只有这个新的层会被训练 下面修改 ...
- 第三章——分类(Classification)
3.1 MNIST 本章介绍分类,使用MNIST数据集.该数据集包含七万个手写数字图片.使用Scikit-Learn函数即可下载该数据集: >>> from sklearn.data ...
- 机器学习入门12 - 分类 (Classification)
原文链接:https://developers.google.com/machine-learning/crash-course/classification/ 1- 指定阈值 为了将逻辑回归值映射到 ...
- sklearn提供的自带的数据集
sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在线下载的数据集(Downloaded ...
随机推荐
- cobaltstrike使用笔记2
0x01 cs服务端绕过流量检测 定义C2的通信格式,修改CS默认的流量特征 编写Profiles: 开源Profiles:https://github.com/rsmudge/Malleable-C ...
- Java 代码块详解
注:本文出自博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 注:本文原链接:https://www.cnblogs.com/chloneda/p/java-c ...
- ag.百家下三路怎么看,如何玩好百家了
\/Q同号3908914.百家作为风靡全球的一款游戏,这么多年长盛不衰,是世界各地玩家的心头所好,但是你真的知道怎么玩好百家吗?第一点呢就是心态问题,我个人认为心态好一切都好,光是心态就占了百分之五十 ...
- Mac 配置本地SSL
1,执行: && openssl req -new -sha256 -x509 -days -key server.key -out server.crt 2,生成过程中,其它可随便填 ...
- pyqt5-进度条控制
1.基于自定义类的方式 继承自QProgressBar类,然后重写timerEvent方法,当该组件设置定时器的时候,会自己处理定时的处理方法,完成相应的功能 from PyQt5.Qt import ...
- markdown转成word或者pdf
利用typora软件 1.登陆官网下载软件 官网地址:https://typora.io/ 点击download 根据自己的电脑下载64位或者32位 2.安装软件 安装界面如下: 3.转换 3.1首先 ...
- 嵊州D5T3 指令 program 神奇的位运算
指令 program [问题描述] krydom 有一个神奇的机器. 一开始,可以往机器里输入若干条指令: opt x 其中,opt 是 & | ^ 中的一种,0 ≤ x ≤ 1023 . 对 ...
- 嵊州D5T1 鸡翅 chicken
鸡翅 chicken [问题描述] 小 x 非常喜欢小鸡翅. 他得知 NSC 超市为了吸引顾客,举行了如下的活动: 一旦有顾客在其他超市找到更便宜的小鸡翅, NSC 超市将免费送给顾客 1000g ...
- 文件流之输入输出(类似于freopen重定向)
利用标准文件操作函数进行数据的输入输出,所用函数均在stdio.h中,类似于freopen重定向文件. 该方法的思路是: (1)建立文件指针 (2)打开文件,将文件指针指向打开的文件,并决定打开的文件 ...
- HW - VCN 介绍
VCN 是个管理摄像机的平台 用来增删改查摄像机,获取摄像机视频流,获取录像 vcn会基于我们的接口做一次开发,作为相机的统一管理入口,获取相机的信息