hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接!
一、前期准备:
1、jdk安装 不要用centos7自带的openJDK
2、hostname 配置 配置位置:/etc/sysconfig/network文件
3、hosts 配置 配置位置 : /etc/hosts
4、date 配置 date -s "....."设置日期一致
5、 关闭安全机制 /etc/sysconfig/selinux
6、 关闭防火墙:firewall iptables off
7、映射文件更改 :windows 域名映射 /etc/hosts文件
本环境的搭建角色:主结点node01,从结点node02,、node03,、node04,第二主节点secondaryNameNode的位置:node02
密匙文件分发到从结点
分发命令举例:
[root@node01 hadoop-2.6.]# scp id_dsa.pub node02:`pwd`/node01.pub
这些都设置好了之后才具备全分布式搭建的条件
二、环境搭建
节点: node01/02/03/04全分布分配方案:
NN SNN DN
NODE01 *
NODE02 * *
NODE03 *
NODE04 *
节点状态:
node01: 伪分布
node02/03/04 : ip配置完成
建立各节点通讯(hosts) 可以通过Ping 结点主机的别名来检查是否结点之间能够通讯成功
设置时间同步:date -s “xxxx-x-xx xx:xx:xx”
秘钥分发:
在每个节点上登录一下自己:产生.ssh目录 ------------------------具体的从新登陆代码:
从node01向node02/node03/node04分发公钥 (公钥的名称要变化)
scp id_dsa.pub node03:`pwd`/node06.pub ---------------------》要明白这里的主结点分发给从结点的公钥文件的名称为啥要变化,是为了如果有其他的结 点 也想要管理这个几点的话, 也会发公钥文件给从结点,如果不改名的话,第二个管理结 点的分发的公钥文件会覆盖掉第一个下发的公钥文件。
各节点把node01的公钥追加到认证文件里:
cat ~/node06.pub >> ~/.ssh/authorized_keys ----------------------》这样之后才会能够实现主结点到从结点的免密登录
node02/node03/node04安装jdk环境,node01分发profile给其他节点,并重读配置文件 :通过source 或者. /etc/profile的形式
分发hadoop部署程序2.6.5 到其他节点
copy node06 下的 hadoop 为 hadoop-local (管理脚本只会读取hadoop目录)
[root@node06 etc]# cp -r hadoop/ hadoop-pesudo --------------->作为分布式集群的备份目录,如果以后想要启动伪分布式集群的话,则可以将这个备份文件改名为hadoop
配置core-site.xml ---------------------》需要配置的是产生的dataNode、DataNode等结点的数据文件,如fsimage文件的位置
配置hdfs-site.xml ---------------------》配置从结点的个数和,第二主结点的位置,如可以将第二个主结点放到其他的某个从结点的位置 之上
配置slaves
分发sxt目录以及他一下的所有的内容及目录 到其他07,08,09节点 ----------------》这样做的好处就是,不用在其他的每个从结点上再去一一的建立一个相同的目录了
格式化集群:hdfs namenode -format ----------------->注意这里格式化完毕之后仅仅是产生一个头结点的数据文件,其他的服务器上 的从结点的数据文 件 和存放数据文件的目录是集群启动的时候才会产生的
至此集群搭建完毕!!!
三、集群启动
启动集群:start-dfs.sh
Jps 查看各节点进程启动情况
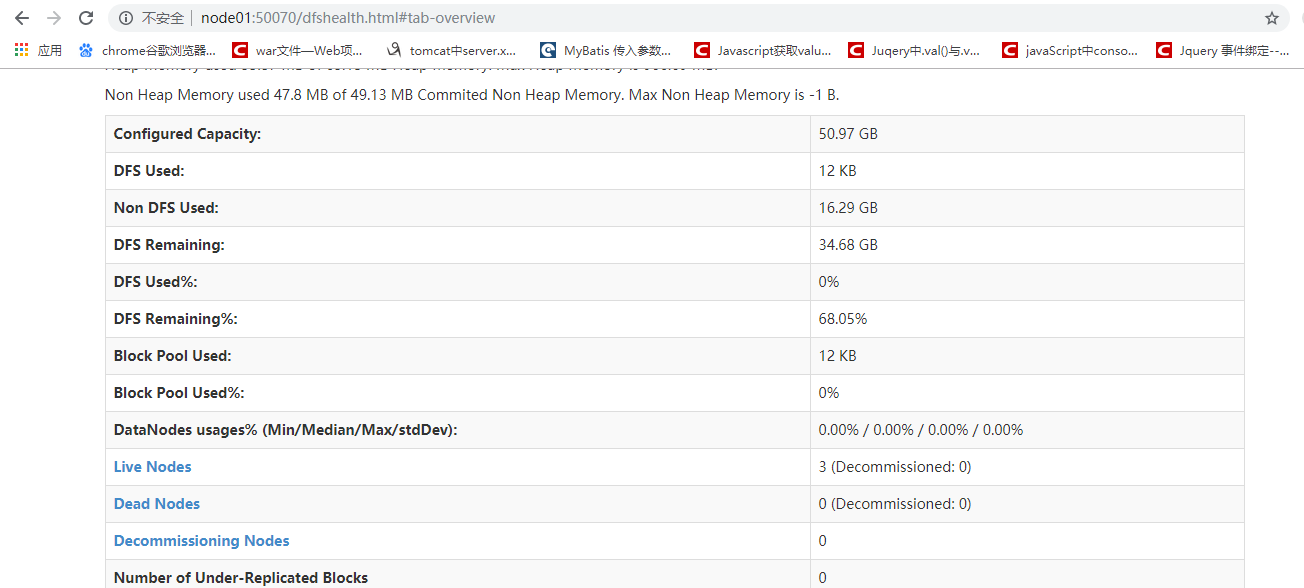
之后如果想要浏览器访问集群的话,需要查询集群和浏览器交互的端口号,一般是50070 ------------》ss -nal
浏览器成功的访问分布式存储系统
四、文件上传
- 上传文件到分布式存储系统
先创建一个用于上传的1.4M大小的文件
[root@node01 hadoop-2.6.]# for i in `seq `;do echo "hello sxt $i" >> test.txt;done
效果

具体的对于上传的文件的分割的大小可以做规定,一般的是默认128M每一块,我们可以通过以下的命令来设置
命令意义:将test.txt文件分割上传,并设置分割大小为1M,所以比如这个文件的总的大小是1.4M 的话,会分成两块
[root@node01 software]# hdfs dfs -D dfs.blocksize= -put test.txt
上传之后的效果
1)从浏览器上看
块1的存储效果
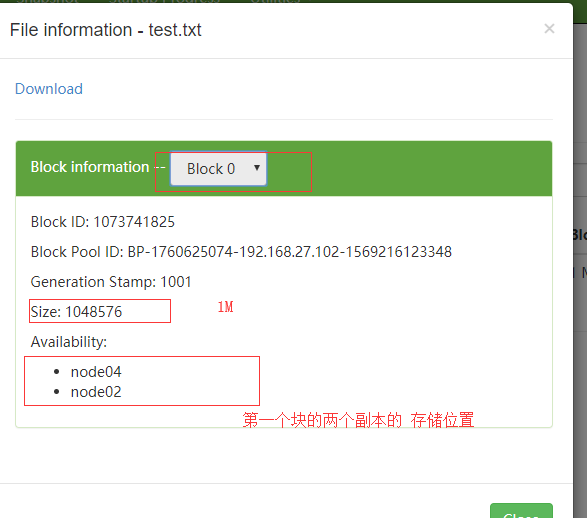
块2的存储效果

2)从xshell中看
输入命令
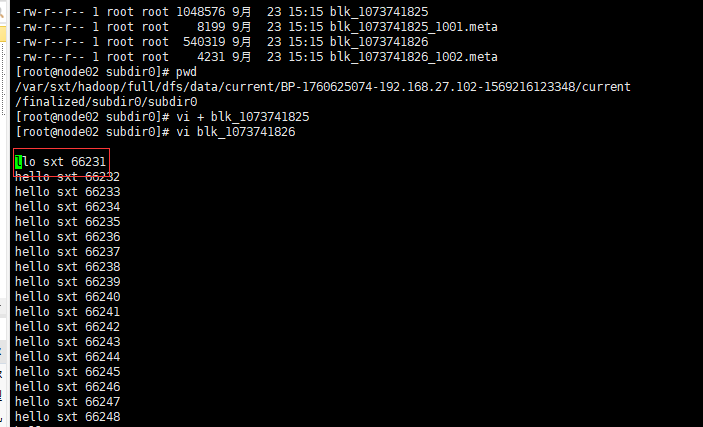
所在目录:存储有数据块的从结点的/var/sxt/hadoop/full/dfs/data/current/BP-1760625074-192.168.27.102-1569216123348/current路径下的文件,如下图

打开底层存储的文本文件test.txt 的blk_107341825的效果
block0

block1
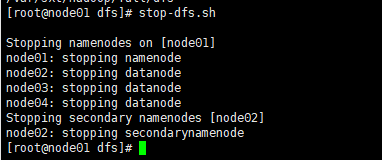
集群停止:
[root@node01 dfs]# stop-dfs.sh
hadoop学习笔记(六):hadoop全分布式集群的环境搭建的更多相关文章
- hadoop学习笔记(九):mr2HA高可用环境搭建及处步使用
本文原创,如需转载,请注明原文链接和作者 所用到的命令的总结: yarn:启动start-yarn.sh 停止stop-yarn.sh zk :zkServer.start ;:zkServer. ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- centos 8 集群Linux环境搭建
一.集群Linux环境搭建 1. 注意事项 1.1 windows系统确认所有的关于VmWare的服务都已经启动 打开任务管理器->服务,查看五个VM选项是否打开. 1.2 确认好VmWare生 ...
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
随机推荐
- python3练习100题——037
原题链接:http://www.runoob.com/python/python-exercise-example37.html 题目:对10个数进行排序. 程序分析:可以利用选择法,即从后9个比较过 ...
- 363. 矩形区域不超过 K 的最大数值和(利用前缀和转化为最大子序和问题)
题目: 链接:https://leetcode-cn.com/problems/max-sum-of-rectangle-no-larger-than-k/ 给定一个非空二维矩阵 matrix 和一个 ...
- QuerySet的常用方法
QuerySet常用方法 使用 connection.queries 可以查看sql语句 filter 将满足条件的结果返回,返回值为QuerySet对象 exclude 将满足条件的结果过滤掉,返回 ...
- R Tidyverse dplyr包学习笔记2
Tidyverse 学习笔记 1.gapminder 我理解的gapminder应该是一个内置的数据集 加载之后使用 > # Load the gapminder package > li ...
- 0002 增加APP配置
创建好工程后的第一步就是配置APP,目前有两个APP,配置APP的步骤如下: 01 APP目录配置 01.1 在APP目录下创建Templates目录,用于存储模板文件 01.2 在APP目录下创建v ...
- pandas模块详解
Pandas模块 1.什么是pandas pandas是基于numpy构建的,用来做数据分析的 2.pandas能干什么 具备对其功能的数据结构DataFrame,Series 集成时间序列功能 提供 ...
- 洛谷P1223 排队接水
https://www.luogu.org/problem/P1223 #include<bits/stdc++.h> using namespace std; struct st { i ...
- VS 2017 mscorlib.dll 加载元数据时发生严重错误,需要终止调试
VS 2017 mscorlib.dll 加载元数据时发生严重错误,需要终止调试 C:\Windows\Microsoft.Net\assembly\GAC_64\mscorlib\v4.0_4.0. ...
- Java 中的 匿名类
什么是内部类? 在一个类中定义另一个类,这样定义的类称为内部类.包含内部类的类称为内部类的外部类. 如果想要通过一个类来使用另一个类,可以定义为内部类. 内部类的外部类的成员变量在内部类仍然有效,内部 ...
- Grafana展示zabbix监控数据
一.安装步骤 (1)进入官网选择合适的操作系统版本下载Grafana:https://grafana.com/grafana/download?platform=linux [root@zabbix- ...