从零开始学习MySQL全文索引
一、为什么要用全文索引
我们在用一个东西前,得知道为什么要用它,使用全文索引无非有以下原因
- like查询太慢、json字段查询太慢(车太慢了)
- 没时间引入ElasticSearch、Solr或者Sphinx这样的软件,或者根本就不会用(无法将五菱宏光换成兰博基尼,即使有兰博基尼也不会开)
- 加索引、联合索引啥的都已经慢得不行了(限速80,车顶盖都卸了也只能开到30)
- 为了提升一下自己的逼格(人家问你有没有开过法拉利,你说开过肯定更有气质一点)
二、什么是全文索引
简单的说,全文索引就相当于大词典中的目录,通过查询目录可以快速定位到想看的内容。
全文索引通过建立倒排索引来快速匹配文档(仅在mysql5.6版本以上支持)
全文索引将连续的字母、数字和下划线当做一个单词,分割单词一般用空格/逗号/句号
MySQL的全文索引支持以下3种查询模式:
- 自然语言模式(
IN NATURAL LANGUAGE MODE)
通过MATCH AGAINST 传递某个特定的字符串来进行检索 - 布尔模式(
IN BOOLEAN MODE)
支持操作符,例如+表示包含,-表示不包含 - 扩展模式(
WITH QUERY EXPANSION)
相当于自然语言模式下的一个扩展,执行两次检索,第一次使用给定短语检索,第二次是结合第一次相关性比较高的行进行检索.
更多请看:官方文档
下面教大家如何创建全文索引,并创建测试数据演示三种查询模式的使用
三、如何创建全文索引
- 方式一:建表时指定
CREATE TABLE light_weight_baby (
id INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
content TEXT,
FULLTEXT(title, content)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
- 方式二:ALTER添加
ALTER TABLE table_name ADD FULLTEXT INDEX index_name (column1,column2,...);
- 方式三:CRATE INDEX添加
CREATE FULLTEXT INDEX index_name ON table_name (column1,column2,...);
四、创建测试数据
创建一个数据库用来演示这三种模式下的检索
CREATE DATABASE chenqionghe DEFAULT CHARSET utf8;
创建一个文章表并插入测试数据
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
) ENGINE=InnoDB;
插入测试数据
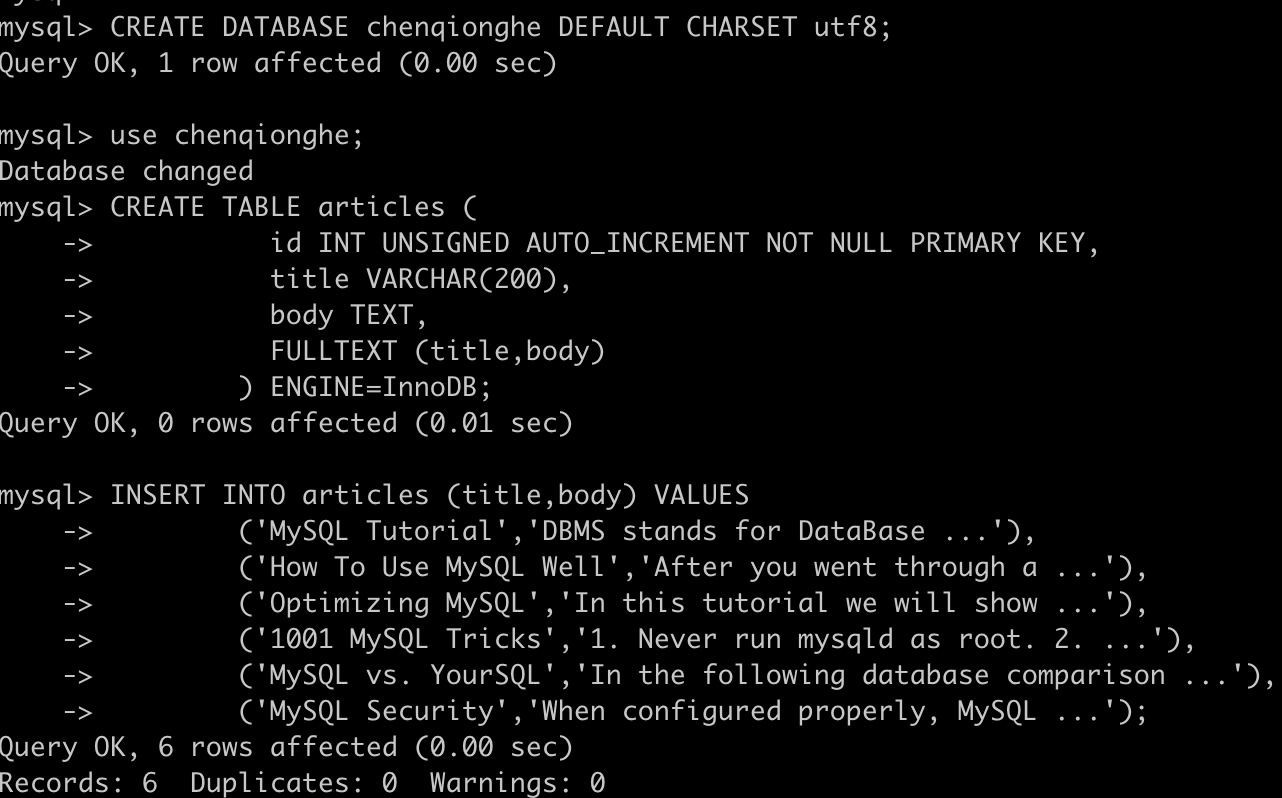
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
执行结果如下
五、查询-使用自然语言模式
这是MySQL的默认查询模式,简单示例如下
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' IN NATURAL LANGUAGE MODE);
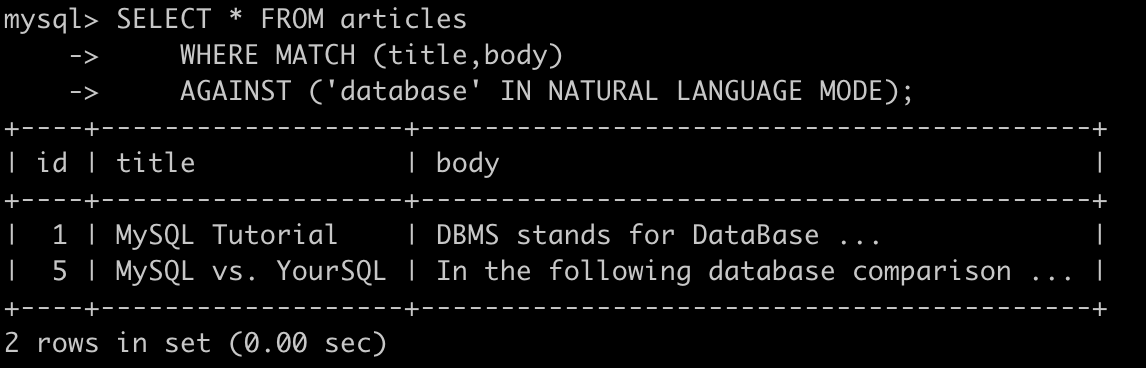
可以看到,不区分大小写,title或body包含database的都返回了,另外,返回的结果将以相关性进行排序。
相关性:根据行中的字段、唯一单词的数量、集合中单词总数和包含特定单词的行数计算。
下面通过两种方式统计数量
# 第一种方式
SELECT COUNT(*) FROM articles
WHERE MATCH (title,body)
AGAINST ('database' IN NATURAL LANGUAGE MODE);
# 第二种方式
SELECT
COUNT(IF(MATCH (title,body) AGAINST ('database' IN NATURAL LANGUAGE MODE), 1, NULL))
AS count
FROM articles;

第一种做了一些额外的工作(按相关性对结果进行排序),但也能使用索引进行查询。
第二种执行了全表扫描,如果搜索项出现在大多数行中,可能比索引查询更快
匹配少数行,第一种快,匹配大多数行,第二种快
下面演示如何检索相关性,但不会进行排序(因为不包含WHERE和ORDER BY)
SELECT id, MATCH (title,body)
AGAINST ('Tutorial' IN NATURAL LANGUAGE MODE) AS score
FROM articles;

下面的示例更复杂,返回倒序后的相关性值,分别在SELECT和WHERE语句中使用了MATCH,但是不会导致额外的开销,因为mysql优化器注意到两次MATCH是相同的,只会使用一次全文搜索
SELECT id, body, MATCH (title,body) AGAINST
('Security implications of running MySQL as root'
IN NATURAL LANGUAGE MODE) AS score
FROM articles WHERE MATCH (title,body) AGAINST
('Security implications of running MySQL as root'
IN NATURAL LANGUAGE MODE);
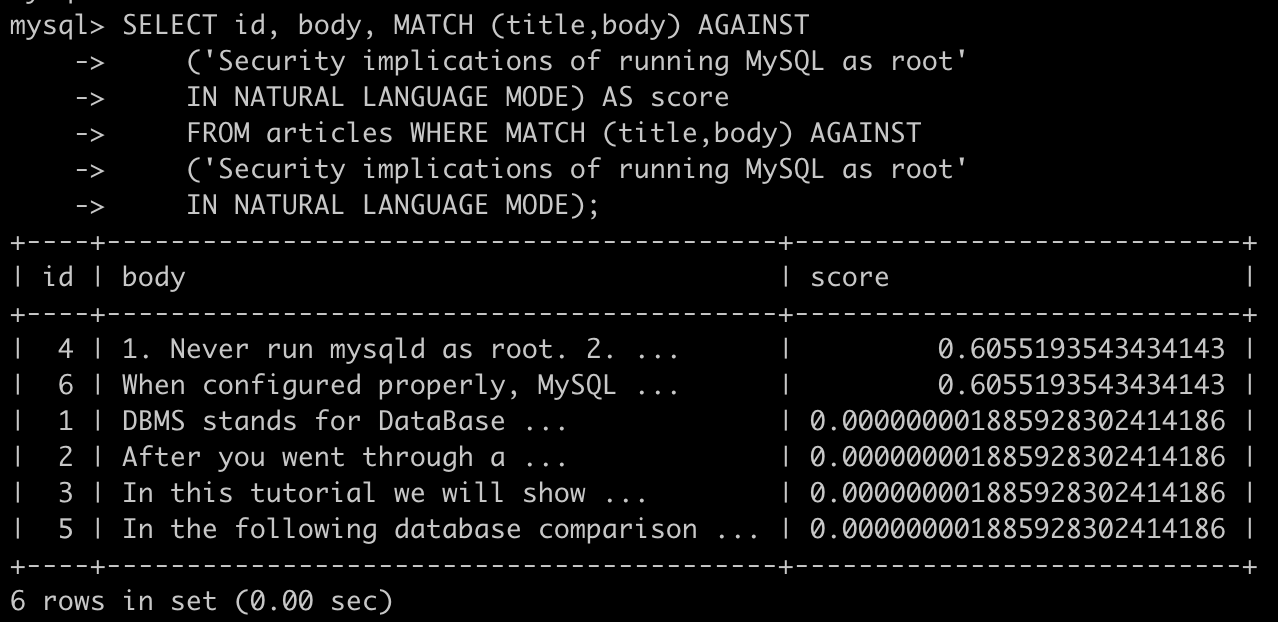
包含在("")中字符中的会被分解为单词,然后在全文索引中进行搜索,简单的说,就是进行OR查询。
六、查询-使用布尔模式(强大的语法)
使用布尔模式需要指定IN BOOLEAN MODE ,不会自动根据相关性排序,一些字符具有特殊的含义,例如可以通过+或-表示一个单词必须存在或不存在。
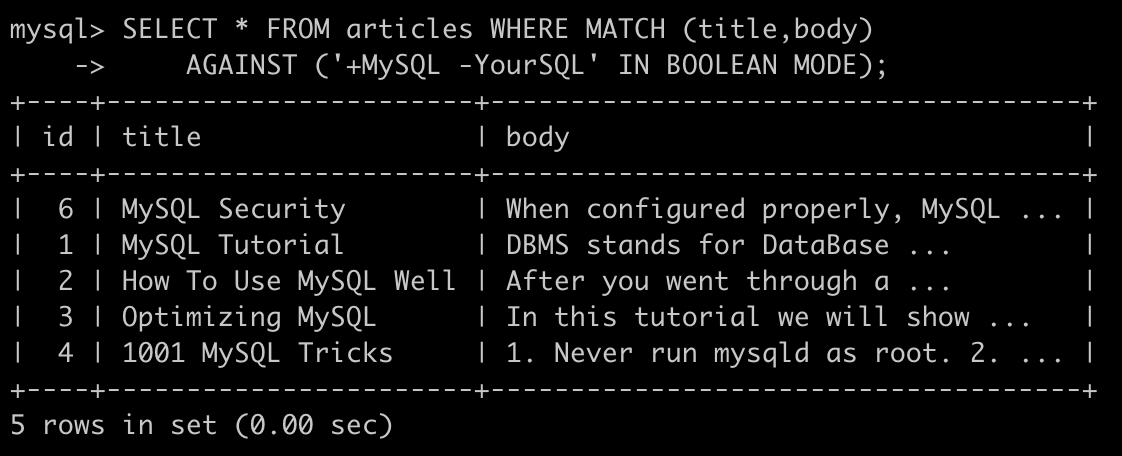
下面的sql语句代表查询必须 包含MySQL但不包含YourSQL
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);
语法
+
必须出现-
必须不出现。
注意:这个操作符是用来排除其他操作符的结果,如果只指定这个,将什么都不返回- 无符号
默认情况,代表或,自动分词搜索。和没有指定IN BOOLEAN MODE的结果一样 @distance
用来测试两个或两个以上的单词是否都在一个指定的距离内,在@距离前指定双引号中的搜索词,例如MATCH(col1) AGAINST('"word1 word2 word3" @8' IN BOOLEAN MODE>
提高该条匹配数据的权重值<
降低该条匹配数据的权重值()
相当于表达式分组,和我们数学中的表达式一个道理~
将其相关性由正转负,表示拥有该字会降低相关性,例如+apple ~macintosh先匹配apple,但如果同时包含macintosh,排名会靠后*
通配符,只能在字符串后面使用"
完全匹配,被双引号包起来的单词必须整个被匹配
示例
apple banana
包含apple或banana其中一个+apple +juice
必须同时包含apple和juice+apple macintosh
包含apple,但是如果同时包含macintosh会给更高的排序+apple -macintosh
包信apple但是不包含macintosh+apple ~macintosh
包含apple,如果同时包含macintosh降低权重+apple +(>turnover <strudel)
1.包含apple和turnover,或,包含apple和strudel
2.包含apple和turnover权重高于包含apple和strudel的记录apple*
包含apple单词的行, “apple”, “apples”, “applesauce”, “applet”都会被匹配到"some words"
完全匹配some words的行,例如 “some words of wisdom”能匹配但“some noise words”匹配不到
七、查询-使用扩展模式
当搜索短语很短时非常有用,例如搜索database可能意味着MySQL、Oracle、DB2、RDBMS都要被匹配到,这就是这个模式能做的。
添加WITH QUERY EXPANSION或 IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION启用,它会执行两次检索,第一次使用给定短语检索,第二次是结合第一次相关性比较高的行进行检索。
例如下面的例子
# 自然语言模式
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' IN NATURAL LANGUAGE MODE);
# 扩展模式
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('database' WITH QUERY EXPANSION);
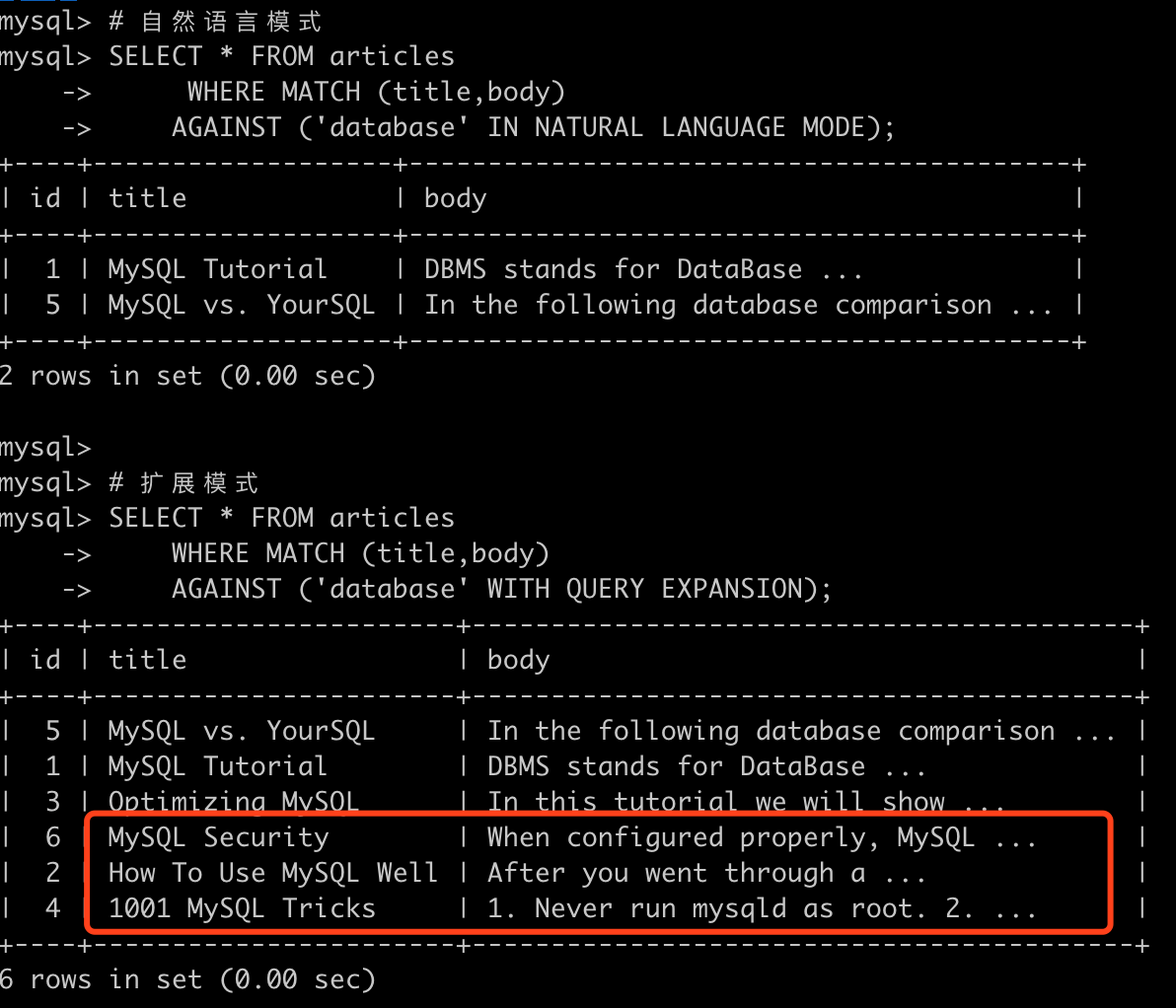
可以看到第二条语句找到了包含MySQL的行,即使该行不包含database,但是因为在第一次的搜索中搜索引擎判断MySQL和database的相关性比较高,所以在执第二次搜索的时候返回了。
八、注意事项
- 只能在类型为CHAR、VARCHAR或者TEXT的字段上创建全文索引
- MATCH (字段) AGAINST (关键词),必须和创建时的字段一起,例如MATCH (light,weight,baby)使用的字段名与全文索引muscle(light,weight,baby)定义的字段名一致。如果只对单个字段查询,需要分别创建全文索引
- 全文索引是以词为基础的,
innodb_ft_min_token_size和innodb_ft_max_token_size用来设置单词的最大和最小长度,不在这个长度区间的将忽略。 - 在停用词stopwords中的将被忽略
- 如果要导入大量数据,先导入数据再建全文索引,比先建全文索引再导入数据的方式快很多。
- 在MySQL 5.7.6之前,全文索引只支持英文全文索引,不支持中文全文索引,MySQL 5.7.6后内置了ngram全文解析器,支持中文、日文、韩文分词。
从零开始学习MySQL全文索引的更多相关文章
- 从零开始学习Mysql的学习记录
2015/06/18 16:23更新,由于QQ邮件的图片链接失效了,请在云笔记链接查看 http://note.youdao.com/share/?id=f0b2ed30a3fc8e57c381e3d ...
- 学习MySQL(下)
具体实例 22.MySQL ALTER命令 当我们需要修改数据表名或者修改数据表字段时,就需要使用到MySQL ALTER命令. 1.如果需要修改数据表的名称,可以在 ALTER TABLE 语句中使 ...
- 重新学习MySQL数据库7:详解MyIsam与InnoDB引擎的锁实现
重新学习Mysql数据库7:详解MyIsam与InnoDB引擎的锁实现 说到锁机制之前,先来看看Mysql的存储引擎,毕竟不同的引擎的锁机制也随着不同. 三类常见引擎: MyIsam :不支持事务,不 ...
- 重新学习MySQL数据库5:根据MySQL索引原理进行分析与优化
重新学习MySQL数据库5:根据MySQL索引原理进行分析与优化 一:Mysql原理与慢查询 MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- 重新学习MySQL数据库4:Mysql索引实现原理
重新学习Mysql数据库4:Mysql索引实现原理 MySQL索引类型 (https://www.cnblogs.com/luyucheng/p/6289714.html) 一.简介 MySQL目前主 ...
- 重新学习MySQL数据库1:无废话MySQL入门
重新学习Mysql数据库1:无废话MySQL入门 开始使用 我下面所有的SQL语句是基于MySQL 5.6+运行. MySQL 为关系型数据库(Relational Database Manageme ...
- 再次学习mysql优化
再次学习mysql优化 表的设计规范化(三范式) 添加索引(普通索引.主键索引.唯一索引.全文索引) 分表(水平分割.垂直分割) 读写分离(写add.update.delete) 存储过程 对mysq ...
- 重新学习Mysql数据库4:Mysql索引实现原理和相关数据结构算法
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- 推荐一些学习MySQL的资源
前言: 在日常工作与学习中,无论是开发.运维.还是测试,对于数据库的学习是不可避免的,同时也是日常工作的必备技术之一.在互联网公司,开源数据库用得比较多的当属MySQL了,相信各位小伙伴关注我的原因也 ...
随机推荐
- P4513 小白逛公园 动态维护最大子段和
题目链接:https://www.luogu.org/problem/P4513 #include<iostream> #include<cstdio> #include< ...
- numpy 读取数据
一.CSV文件 CSV: Comma-Separated Value,逗号分隔值文件 显示:表格状态 源文件:换行和逗号分隔,逗号 列,换行 行 二.读取数据 1.方法 loadtxt(fname, ...
- Java框架之MyBatis 06-全局配置-mapper映射-分步查询
MyBatis MyBatis是Apache的一个开源项目iBatis, iBatis一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架. iBatis 提供的持 ...
- [bzoj2668] [洛谷P3159] [cqoi2012] 交换棋子
Description 有一个n行m列的黑白棋盘,你每次可以交换两个相邻格子(相邻是指有公共边或公共顶点)中的棋子,最终达到目标状态.要求第i行第j列的格子只能参与mi,j次交换. Input 第一行 ...
- 实用代码|javaMail发送邮件(文末重磅资源!)
每天进步一点点,距离大腿又近一步!阅读本文大概需要5分钟 JavaMail发送邮件,简单实用,了解一下呗~ 1.开启邮箱MAP/SMTP服务,获取第三方授权码 以QQ邮箱为例 2.主要代码 maven ...
- UVA 最大面积最小三角形剖分
点击打开题目 题目大意: 以顺时针或逆时针给出一个简单多边形的n个点的坐标,用n-2条互不相交的,且与边不相交的对角线,分成n-2个三角形,要求其中最大三角形的面积最小 开始还汪星人咬乌龟,无从下口, ...
- allegro设置内存分配器的一个坑
看过<游戏引擎架构>后我开始对内存的分配问题关注,一直想用内存分配器来管理游戏的内存.前两天发现了有许多第三方内存分配器可以用.最后挑中了nedmalloc,这个库也是ogre所使用的,测 ...
- 个人第4次作业—Alpha项目测试
这个作业属于哪个课程 课程链接 这个作业要求在哪里 作业要求 团队名称 CTRL_IKUN(团队博客) 这个作业的目标 对非本小组的三个项目进行软件测试 一.测试人员个人信息 学号 201731032 ...
- 创建dynamics CRM client-side (二) - Client API
如果我们想用script来直接在form上做一些修改, 我们需要用到client api 来做交互. 我们可以用以下来理解: Form <---> Client API <---&g ...
- Algorithm: 多项式乘法 Polynomial Multiplication: 快速傅里叶变换 FFT / 快速数论变换 NTT
Intro: 本篇博客将会从朴素乘法讲起,经过分治乘法,到达FFT和NTT 旨在能够让读者(也让自己)充分理解其思想 模板题入口:洛谷 P3803 [模板]多项式乘法(FFT) 朴素乘法 约定:两个多 ...