scrapy系列(三)——基础spider源码解析
前面两章介绍了scrapy的安装和项目的新建,那么这一章就讲讲spider吧。
scrapy有个命令是runspider, 这个命令的作用就是将一个spider当做一个python文件去执行,而不用创建一个完整的项目。可以说是最简单的一个爬虫项目了,只有一个文件,这也体现出了spider对于scrapy的重要性,item和pipline可有可无,settings等也可以使用默认的,可是spider必须自己构造。而我们写爬虫的时候大部分时间和精力也是耗费在这里,所以spider的重要性就不言而喻了。
这次教程将结合官方文档和源码一起来讲解,希望大家能够喜欢。
首先看看官方文档对于spider的介绍:

最上面一段就不解释了,就是介绍spider的作用和功能。对于spider来说主要经历如下几件事:
1.根据url生成Request并指定回调方法处理Response。第一个Request是通过start_requests()产生的,该方法下面会讲到。
2. 在回调方法中,解析页面的Response,返回Item实例或者Request实例,或者这两种实例的可迭代对象。
3.在回调方法中,通常使用Selectors(也可以使用BeautifulSoup,lxml等)来提取数据。
4.最后spider会return item给Pipline完成数据的清洗,持久化等操作。
scrapy为我们提供了几款基础的spider,我们需要继承这些来实现自己的spider。我们接下来就根据资料及源码来了解它们。
class scrapy.spiders.Spider 下面是它的源码:
class Spider(object_ref):
"""Base class for scrapy spiders. All spiders must inherit from this
class.
""" name = None
custom_settings = None def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = [] @property
def logger(self):
logger = logging.getLogger(self.name)
return logging.LoggerAdapter(logger, {'spider': self}) def log(self, message, level=logging.DEBUG, **kw):
"""Log the given message at the given log level This helper wraps a log call to the logger within the spider, but you
can use it directly (e.g. Spider.logger.info('msg')) or use any other
Python logger too.
"""
self.logger.log(level, message, **kw) @classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = cls(*args, **kwargs)
spider._set_crawler(crawler)
return spider def set_crawler(self, crawler):
warnings.warn("set_crawler is deprecated, instantiate and bound the "
"spider to this crawler with from_crawler method "
"instead.",
category=ScrapyDeprecationWarning, stacklevel=)
assert not hasattr(self, 'crawler'), "Spider already bounded to a " \
"crawler"
self._set_crawler(crawler) def _set_crawler(self, crawler):
self.crawler = crawler
self.settings = crawler.settings
crawler.signals.connect(self.close, signals.spider_closed) def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url) def make_requests_from_url(self, url):
return Request(url, dont_filter=True) def parse(self, response):
raise NotImplementedError @classmethod
def update_settings(cls, settings):
settings.setdict(cls.custom_settings or {}, priority='spider') @classmethod
def handles_request(cls, request):
return url_is_from_spider(request.url, cls) @staticmethod
def close(spider, reason):
closed = getattr(spider, 'closed', None)
if callable(closed):
return closed(reason) def __str__(self):
return "<%s %r at 0x%0x>" % (type(self).__name__, self.name, id(self)) __repr__ = __str__
该类的基类是object_ref,其定义如下图所示:
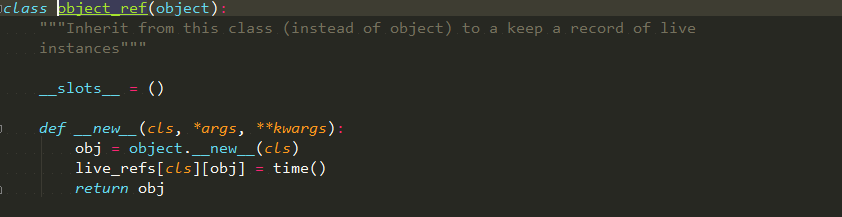
从源码中可以看到这个类的子类的实例都会记录它本身的存活状况,这个作用会在以后讲解,目前用不到。
类scrapy.spiders.Spider 是最简单的spider,所有的spider包括自己定义的和scrapy提供的都会继承它。它只是提供最基本的特性,也是我最常用的spider类。
name:
这个属性是字符串变量,是这个类的名称,代码会通过它来定位spider,所以它必须唯一,它是spider最重要的属性。回头看看源码中__init__的定义,可以发现这个属性是可以修改的,如果不喜欢或者有需要重命名spider的name,可以在启动的时候传参修改name属性。
allowed_domains:
这个属性是一个列表,里面记载了允许采集的网站的域名,该值如果没定义或者为空时表示所有的域名都不进行过滤操作。如果url的域名不在这个变量中,那么这个url将不会被处理。不想使用域名过滤功能时可以在settings中注释掉OffsiteMiddleware, 个人不建议这么做。
start_urls:
这个属性是一个列表或者元组,其作用是存放起始urls,相当于这次任务的种子。使用默认模板创建spider时,该值是个元组,创建元组并且只有一个元素时需要在元素后面添加“,”来消除歧义,不然会报错:“ValueError: Missing scheme in request url: h”。这边经常有人出错,为了避免这个错误可以根据上一章内容,将模板中start_urls的值设置为列表。
custom_settings:
这个属性值是一个字典,存放settings键值对,用于覆盖项目中的settings.py的值,可以做到在一个项目中的不同spider可以有不同的配置。不过这个值要慎用,有些settings的值覆盖也没有起作用,eg:“LOG_FILE”。如果想每个spider都有自己的log文件的话就不能这么做。因为日志操作在这个方法执行之前,那么无论怎么改都改不了之前的行为。不过这个问题scrapy研发团队已经注意到了,相信不久的将来会进行处理的。
crawler:
这个值从源码可以看出来自于方法from_crawler()。该值是一个Crawler 实例, 其作用后面的教程会讲解,这边就不细说了。
settings:
这个值也是来自于方法from_crawler()。是一个Settings 实例,这个后面也会细说,稍安勿躁哈。
logger:
顾名思义,记录日志用的,也是后面讲,耐心等候哈。
from_crawler:
这是一个类方法,scrapy创建spider的时候会调用。调用位置在crawler.py 的类Crawler中,源码可以自己去看看,就不带大家看了。这个方法的源码在上面,我们可以看到,在实例化这个spider以后,这个实例才有的settings和crawler属性,所以在__init__方法中是没法访问这俩属性的。如果非要在__init__方法中使用相关属性,那么只能重写该方法,大家可以尝试写写。
start_requests():
这个方法必须返回一个可迭代对象,切记!!!!上面就有源码很简单,就不细说了。如果想对属性start_urls做一些操作(增删改),并希望结果作为种子url去采集网站的时候,可以重写这个方法来实现。有了这个方法,甚至都不用在代码中定义start_urls。比如我们想要读取持久化的url执行采集操作,那么就没必要转存进start_urls里面,可以直接请求这些urls。当种子urls需要post请求的话,也需要重写该方法。
make_requests_from_url(url):
这个方法顾名思义,要是还不懂就看看上面的源码。这里只说一点,因为这里的Request初始化没有回调方法,就是默认采用parse方法作为回调。另外这里的dont_filter值为True,这个值的作用是该url不会被过滤,至于具体细节请听下回分解。
parse(self, response):
这个方法对于有经验的同学来说再熟悉不过了,我就简单的说说。这个方法作为默认回调方法,Request没有指定回调方法的时候会调用它,这个回调方法和别的回调方法一样返回值只能是Request, 字典和item对象,或者它们的可迭代对象。
log(message[, level, component]):
这个方法是对logger的包装,看看源码就好,没什么什么可说的。
closed(reason):
当这个spider结束时这个方法会被调用,参数是一个字符串,是结束的原因。这种用法以后会介绍,这里只需记住,想在spider结束时做一些操作时可以写在这里。
scrapy基础spider算是介绍完了,有兴趣的小伙伴可以对照一个好的实例来看这个文章,或许帮助更大。如果有什么疑问,大家可以在评论区讨论,共同进步。
scrapy系列(三)——基础spider源码解析的更多相关文章
- ThreadPoolExecutor系列<三、ThreadPoolExecutor 源码解析>
本文系作者原创,转载请注明出处:http://www.cnblogs.com/further-further-further/p/7681826.html 在源码解析前,需要先理清线程池控制的运行状态 ...
- 老生常谈系列之Aop--Spring Aop源码解析(一)
老生常谈系列之Aop--Spring Aop源码解析(一) 前言 上一篇文章老生常谈系列之Aop--Spring Aop原理浅析大概阐述了动态代理的相关知识,并且最后的图给了一个Spring Aop实 ...
- 老生常谈系列之Aop--Spring Aop源码解析(二)
老生常谈系列之Aop--Spring Aop源码解析(二) 前言 上一篇文章老生常谈系列之Aop--Spring Aop源码解析(一)已经介绍完Spring Aop获取advice切面增强方法的逻辑, ...
- 小学徒成长系列—StringBuilder & StringBuffer关键源码解析
在前面的博文<小学徒成长系列—String关键源码解析>和<小学徒进阶系列—JVM对String的处理>中,我们讲到了关于String的常用方法以及JVM对字符串常量Strin ...
- 【vuejs深入三】vue源码解析之二 htmlParse解析器的实现
写在前面 一个好的架构需要经过血与火的历练,一个好的工程师需要经过无数项目的摧残. 昨天博主分析了一下在vue中,最为基础核心的api,parse函数,它的作用是将vue的模板字符串转换成ast,从而 ...
- Java 集合系列Stack详细介绍(源码解析)和使用示例
Stack简介 Stack是栈.它的特性是:先进后出(FILO, First In Last Out). java工具包中的Stack是继承于Vector(矢量队列)的,由于Vector是通过数组实现 ...
- 第三章 CopyOnWriteArrayList源码解析
注:在看这篇文章之前,如果对ArrayList底层不清楚的话,建议先去看看ArrayList源码解析. http://www.cnblogs.com/java-zhao/p/5102342.html ...
- java容器三:HashMap源码解析
前言:Map接口 map是一个存储键值对的集合,实现了Map接口的主要类有以下几种 TreeMap:用红黑树实现 HashMap:数组和链表实现 HashTable:与HashMap类似,但是线程安全 ...
- 第三章 LinkedList源码解析
一.对于LinkedList需要掌握的八点内容 LinkedList的创建:即构造器 往LinkedList中添加对象:即add(E)方法 获取LinkedList中的单个对象:即get(int in ...
随机推荐
- linux下tar.bz2文件的 解压缩方法
一 使用bzip2解压缩命令进行解压缩: bzip2 -d gcc-4.1.0.tar.bz2 二 上面解压完之后执行下面的命令. tar -xvf gcc-4.1.0.tar 或 tar -xvf ...
- static加载顺序简介
1.先执行父类的静态代码块和静态变量初始化,并且静态代码块和静态变量的执行顺序只跟代码中出现的顺序有关. 2.执行子类的静态代码块和静态变量初始化. 3.执行父类的实例变量初始化 4.执行父类的构造函 ...
- redis内部分享ppt
作者:青客宝团队 Redis:最好的缓存数据库 说Redis是缓存服务,估计有些人会不开心,因为Redis也可以把数据库持久化,但是在大多数情况Redis的竞争力是提供缓存服务.说到缓存服务必然会想到 ...
- Linux编程 3 (初识bash shell与man查看手册)
一.初识bash shell 1.1 启动 shell GNU bash shell 能提供对Linux系统的交互式访问.通常是在用户登录终端时启动,登录时系统启动shell依赖于用户账户的配置. ...
- java对文件的检索
先说下思路吧. 1.先把xls等文件转换为静态html文件:可以用很多插件,类似我的博客地址: http://www.cnblogs.com/Alandre/p/3221006.html 2.再对转的 ...
- 一文了解JAVA虚拟机的重要组成
JVM是JAVA平台的重要组成之一,因涉及知识点太多,故从以下几个方面对JVM进行浅层面的介绍,如果需要深入理解,推荐学习机械工业出版社的<深入理解JAVA虚拟机>. 请尊重作者劳动成果, ...
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(二十四):权限控制(Shiro 注解)
在线演示 演示地址:http://139.196.87.48:9002/kitty 用户名:admin 密码:admin 技术背景 当前,我们基于导航菜单的显示和操作按钮的禁用状态,实现了页面可见性和 ...
- Linux系列教程(三)——Linux学习技巧
前面我们讲了Linux系统的详细安装教程,大家跟着教程一步一步的操作,应该能完美的完成安装.那么这篇博客跟大家聊聊如何来学习Linux. 1.工欲善其事必先利其器 ①.第一个问题:通过前面在虚拟软件中 ...
- 如何在线显示php源代码
通过php提供的函数highlight_file和highlight_string实现
- 关于wepack的使用总结以及优化探讨
一.前言 不知不觉,webpack版本已经到4.0了.使用它也有很长一段时间了,回头看看,自己木有总结webpack方面的知识,现在有空起个头,主要是总结自己常用的配置和一下优化的探讨,以后有啥想法也 ...