HADOOP HA 踩坑 - org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /mnt/data1/hadoop/dfs/journal/hdfscluster not formatted
报错:在journalnode的log中:
org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /mnt/data1/hadoop/dfs/journal/hdfscluster not formatted
状况:
大多数情况是namenode起不来
方案:
情况一:只有部分journalnode报这个错,原因是这些journalnode的journal数据不同步
解决:将无错的journalnode下的journal文件夹拷贝覆盖之
情况二:由非HA转为HA
情况三:你的所有journalnode都报这个错,并且journal文件夹为空
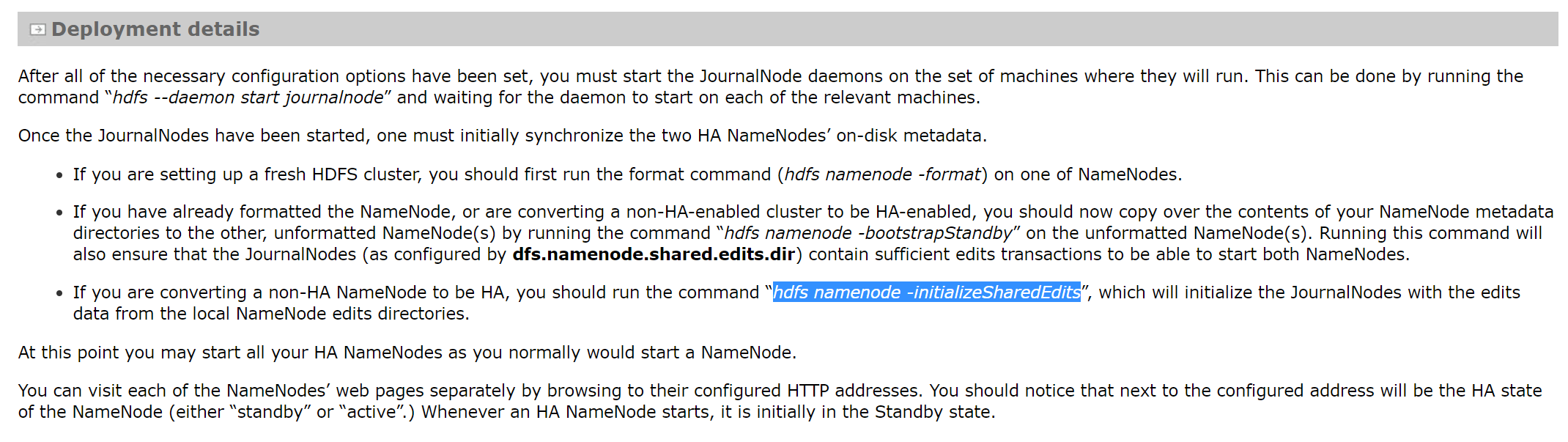
解决:情况二和情况三一样,都是需要初始化 journalnode。那么,将所有journalnode守护进程启动后,在其中一台namenode下,执行 hdfs namenode -initializeSharedEdits
HADOOP HA 踩坑 - org.apache.hadoop.hdfs.qjournal.protocol.JournalNotFormattedException: Journal Storage Directory /mnt/data1/hadoop/dfs/journal/hdfscluster not formatted的更多相关文章
- HADOOP HA 踩坑 - 所有 namenode 都是standby
报错: 无明显报错 状况: 所有namenode都是standby,即ZK服务未生效 尝试一:手动强制转化某个namenode为active 操作:在某台namenode上,执行 hdfs haadm ...
- Hadoop编程踩坑
Hadoop踩坑 在hadoop所有组件编程中,遇到在Windows下运行程序出现 java.io.IOException: Could not locate executable null\bin\ ...
- Hadoop错误集:Journal Storage Directory not formatted
类型一: 当你从异常信息中看到JournalNode not formatted,如果在异常中看到三个节点都提示需要格式化JournalNode. 如果你是新建集群,你可以重新格式化NameNode, ...
- Hadoop EC 踩坑 :data block 缺失导致的 HDFS 传输速率下降
环境:hadoop-3.0.2 + 11 机集群 + RS-6-3-1024K 的EC策略 状况:某天,往 HDFS 上日常 put 业务数据时,发现传输速率严重下降 分析: 检查集群发现,在之前的传 ...
- Ubuntu搭建Hadoop的踩坑之旅(一)
本文将介绍如何使用虚拟机一步步从安装Ubuntu到搭建Hadoop伪分布式集群. 本文主要参考:在VMware下安装Ubuntu并部署Hadoop1.2.1分布式环境 - CSDN博客 一.所需的环境 ...
- hadoop系列 第一坑: hdfs JournalNode Sync Status
今天早上来公司发现cloudera manager出现了hdfs的警告,如下图: 解决的思路是: 1.首先解决简单的问题,查看警告提示的设置的阀值时多少,这样就可以快速定位到问题在哪了,果然Journ ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
- Hadoop 配置及hadoop HA 的配置
注:本文中提到的ochadoop 不要感到奇怪,是亚信公司内部自己合成的一个包.把全部的组件都放在一个包内了.免去了组件的下载过程和解决兼容问题.事实上也能够自己下载的.不要受到影响. 另,转载请注明 ...
- Hadoop 学习之路(六)—— HDFS 常用 Shell 命令
1. 显示当前目录结构 # 显示当前目录结构 hadoop fs -ls <path> # 递归显示当前目录结构 hadoop fs -ls -R <path> # 显示根目录 ...
随机推荐
- elementUI中table组件会出现空白部分
先上图: 造成原因: width全部都写死了,(注释:不要全部都写死width,没写width的会自动分配宽度)
- ELK之使用heartbeat监控WEB站点
简介 无论您要测试同一台主机上的服务,还是要测试开放网络上的服务,Heartbeat 都能轻松生成运行时间数据和响应时间数据 Heartbeat 能够通过 ICMP.TCP 和 HTTP 进行 pin ...
- 分库分表、读写分离——用Sql和ORM(EF)来实现
分库:将海量数据分成多个库保存,比如:2017年的订单库——Order2017,2018年的订单库——Order2018... 分表:水平分表(Order拆成Order1.....12).垂直分表(O ...
- Java之事务的基本应用
基本介绍 事务是数据一致性最基本的保证,也就是说一个事务中的操作要么都成功,要么都失败,不允许部分成功.我们常说的事务就是jdbc事务,当然Java中还有其他事务,并且在使用jdbc事务有很多注意点, ...
- 转载的web server实例
asp.net—web server模拟网上购物 2014-05-08 我来说两句 来源:asp.net—web server模拟网上购物 收藏 我要投稿 在学vb的时候学到了a ...
- JavaScript 数组插入元素并排序
1.插入类排序 插入类排序的思想是:在一个已排好序的序列区内,对待排序的无序序列中的记录逐个进行处理,每一步都讲待排序的记录和已排好的序列中的记录进行比较,然后有序的插入到该序列中,直到所有待排序的记 ...
- Cisco Packet Tracer
---恢复内容开始--- 1.简单局域网组建 交换机:2960 s1 终端设备:generic pc 配置 pc1 单击>>Descktop>>IP configur ...
- 《linux就该这么学》第八节课:第六章存储结构与磁盘划分
笔记 (借鉴请修改) 6.3.文件系统与数据资料 目前linux最常见的文件系统: ext3:日志文件系统.宕机时可自动恢复数据资料,容量越大恢复时间越长,且不能保证百分百不丢失. ext4:e ...
- sublime-text3打造markdown编辑器
编辑插件 sublime自带的markdown语法高亮并不是很友好,推荐安装Markdown Editing,github主页然后在视图->语法里选择MarkdownEditing启用,支持三种 ...
- hdu5517 二维树状数组
题意是给了 n个二元组 m个三元组, 二元组可以和三元组 合并生成3元组,合并条件是<a,b> 与<c,d,e>合并成 <a,c,d> 前提是 b==e, 如果存在 ...