4-29 c语言之栈,队列,双向链表
今天学习了数据结构中栈,队列的知识
相对于单链表来说,栈和队列就是添加的方式不同,队列就相当于排队,先排队的先出来(FIFO),而栈就相当于弹夹,先压进去的子弹后出来(FILO)。
首先看一下栈(Stack)的实现
#include<stdio.h>
#include<stdlib.h>
#define TRUE 1
#define FALES 0
typedef struct NODE
{
int i;
struct NODE *pNext; //指向的是 上一个从栈顶刚压入的结点
}Stack;
typedef int BOOL; //因为c语言里没有布尔类型,所以用int模拟一下
void Push(Stack **pTop,int i);
BOOL IfEmpty(Stack *pTop);
Stack *Pop(Stack **pTop); //出栈操作
int main()
{
Stack *pTop = NULL; }
void Push(Stack **pTop,int i) //压栈操作
{
Stack *pTemp = (Stack *)malloc(sizeof(Stack));
pTemp->i = i;
pTemp->pNext = NULL; pTemp->pNext = *pTop;
*pTop = pTemp; return;
}
BOOL IfEmpty(Stack *pTop) //因为c++的STL容器里存在判断栈是否为空的操作,在这模拟一下
{
if(pTop == NULL)
return TRUE;
return FALES;
}
Stack *Pop(Stack **pTop)
{
Stack *pPop = NULL;
if(IfEmpty(*pTop))
{
return NULL;
}
else
{
pPop = *pTop;
*pTop = (*pTop)->pNext;
return pPop;
}
}
其次队列(Queue)的实现非常简单,队列压入的实现就和单链表尾添加一样,而弹出就和单链表头删除是一样的,只不过不需要free直接返回队首指针即可;
#include<stdio.h>
#include<stdlib.h>
#define TRUE 1
#define FALSE 0
typedef struct NODE
{
int i;
struct NODE *pNext;
}Queue;
typedef int BOOL;
int GetId();
void QueueIn(Queue **ppHead,Queue **ppEnd);
BOOL IfEmpty(Queue *pHead);
Queue *QueueOut(Queue **ppHead,Queue **ppEnd);
int main()
{
Queue *pHead = NULL;
Queue *pEnd = NULL;
Queue *p = NULL; QueueIn(&pHead,&pEnd);
QueueIn(&pHead,&pEnd);
QueueIn(&pHead,&pEnd);
p = QueueOut(&pHead,&pEnd); return ; }
int GetId()
{
static int i = ;
i++;
return i;
}
void QueueIn(Queue **ppHead,Queue **ppEnd)
{
Queue *pTemp = (Queue *)malloc(sizeof(Queue));
pTemp->i = GetId();
pTemp->pNext = NULL; if(*ppHead == NULL)
{
*ppHead = pTemp;
}
else
{
(*ppEnd)->pNext = pTemp;
}
*ppEnd = pTemp;
}
BOOL IfEmpty(Queue *pHead)
{
if(pHead == NULL)
return TRUE;
return FALSE;
}
Queue *QueueOut(Queue **ppHead,Queue **ppEnd)
{
Queue *pOut = NULL;
if(IfEmpty(*ppHead) == TRUE)
return NULL;
else
{
pOut = *ppHead;
*ppHead = (*ppHead)->pNext;
return pOut;
}
}
那么栈和栈区又有什么区别呢?先看这样一段程序
#include<stdio.h>
int main()
{
int i = 1;
printf("%d %d\n ",i,i++); return ;
}
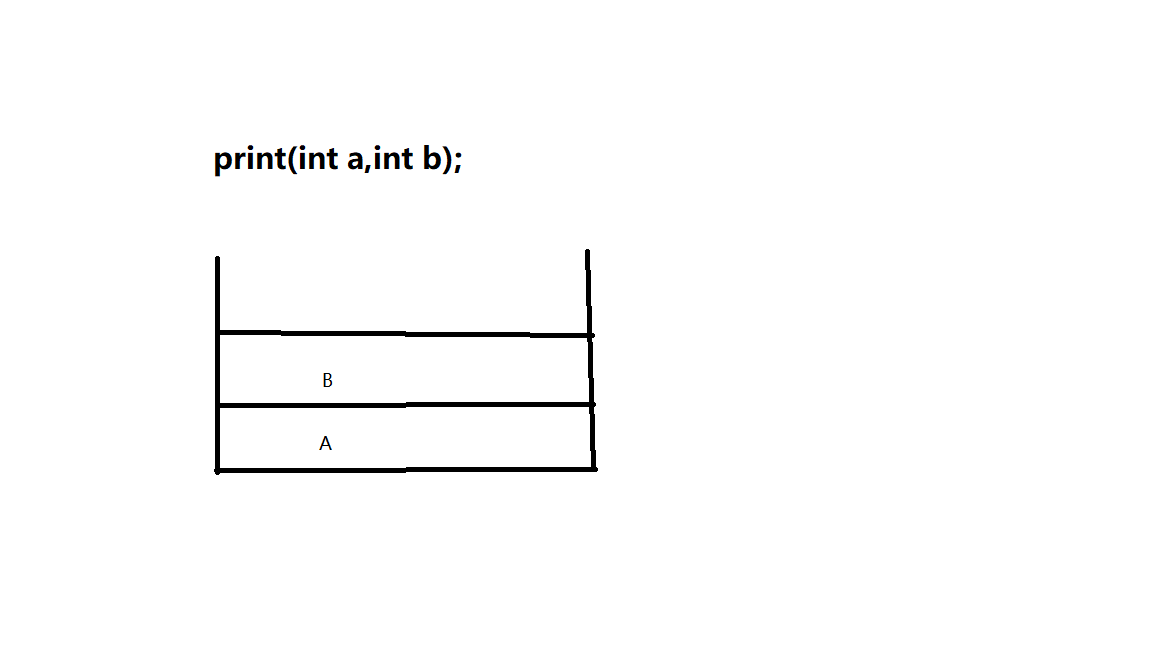
可能一打眼看 就认为是1 1,但测试后发现是 2 1,这就不免让人联想到先进后出的特点了,由于printf是一个标准输出库函数,i 和 i++都算做是两个实参,在函数中,形参也是一个局部变量,在函数这个堆区中存在,按照图中出栈的顺序先B后A,那么先 i++ 出来为 1 ,i 其次出来就为2了(启示就是,在栈区中 若一个函数的参数用了同一个变量 ,记得栈的特点)
双向链表,故名思意就是有一个链表可正向可反向,也就是在添加每个结点的时候,加入一个指针,指向上一个结点的地址,代码如下:
#include<stdio.h>
#include<stdlib.h>
typedef struct NODE
{
int id;
struct NODE *pNext;
struct NODE *pLast; //指向上个结点
}List;
void AddNode(List **ppHead,List **ppEnd,int id);
int main()
{
List *pHead = NULL;
List *pEnd = NULL;
AddNode(&pHead,&pEnd,);
AddNode(&pHead,&pEnd,);
AddNode(&pHead,&pEnd,);
AddNode(&pHead,&pEnd,); while(pHead)
{
printf("%d\n",pHead->id);
pHead = pHead->pNext;
}
printf("\n"); while(pEnd)
{
printf("%d\n",pEnd->id);
pEnd = pEnd->pLast;
} }
void AddNode(List **ppHead,List **ppEnd,int id)
{
List *pTemp = (List *)malloc(sizeof(List));
pTemp->id = id;
pTemp->pLast = NULL;
pTemp->pNext = NULL; if(*ppHead == NULL)
{
*ppHead = pTemp;
*ppEnd = pTemp;
}
else
{
(*ppEnd)->pNext = pTemp;
pTemp->pLast = *ppEnd;
*ppEnd = pTemp;
}
return;
}
最后看到了有两个小问题
第一个 如何用两个栈实现一个队列 这个很简单,先全部压入第一个栈里,然后弹出再压出第二个栈里,最后弹出的就是队列的顺序,反反得正
#include<stdio.h>
#include<stdlib.h>
typedef struct NODE
{
int id;
struct NODE *pNext;
}
Stack;
void Push1(Stack **pTop1);
Stack *Pop1(Stack **pTop1);
void Push2(Stack **pTop2,Stack *pNode);
Stack *Pop2(Stack **pTop2);
Stack *QueueOut(Stack **pTop1,Stack **pTop2);
void InitStack(Stack **pTop1,int n);
int IfEmpty(Stack *pTop1);
int GetId();
int main()
{
Stack *pTop1 = NULL;
Stack *pTop2;
Stack *pTemp = NULL;
InitStack(&pTop1,);
pTemp = QueueOut(&pTop1,&pTop2);
while(pTop2)
{
pTemp = QueueOut(&pTop1,&pTop2);
} return ;
}
int GetId()
{
static int i = ;
i++;
return i;
}
void InitStack(Stack **pTop1,int n)
{
int i;
for(i = ;i < n;i++)
{
Push1(pTop1);
}
return;
}
void Push1(Stack **pTop1)
{
Stack *pTemp = (Stack *)malloc(sizeof(Stack));
pTemp->id = GetId();
pTemp->pNext = NULL; pTemp->pNext = *pTop1;
*pTop1 = pTemp; return;
}
Stack *Pop1(Stack **pTop1)
{
Stack *pPop = NULL;
if(*pTop1 == NULL)
{
return NULL;
}
else
{
pPop = *pTop1;
*pTop1 = (*pTop1)->pNext;
return pPop;
}
}
void Push2(Stack **pTop2,Stack *pNode)
{
pNode->pNext = *pTop2;
*pTop2 = pNode; return; }
Stack *Pop2(Stack **pTop2)
{
Stack *pPop = NULL;
if(*pTop2 == NULL)
{
return NULL;
}
else
{
pPop = *pTop2;
*pTop2 = (*pTop2)->pNext;
return pPop;
}
}
int IfEmpty(Stack *pTop1)
{
if(pTop1 == NULL)
return ;
return ;
}
Stack *QueueOut(Stack **pTop1,Stack **pTop2)
{
while(IfEmpty(*pTop1) != )
Push2(pTop2,Pop1(pTop1)); return Pop2(pTop2);
}
第二个,如何快速的找到链表里倒数第n个结点,设置两个指针指向头,一个先往后走k个结点,然后一起走,当先走的那个到达尾结点时,后走的也就是倒数第k个结点了
#include<stdio.h>
#include<stdlib.h>
typedef struct NODE
{
int id;
struct NODE *pNext;
}List;
int GetId();
void AddNode(List **ppHead,List **ppEnd);
List *Search(List *pHead,List *pEnd,int n);
int main()
{
List *pHead = NULL;
List *pEnd = NULL;
List *pTemp = NULL;
int i;
for(i = ;i < ;i++)
AddNode(&pHead,&pEnd);
pTemp = Search(pHead,pEnd,);
printf("%d\n",pTemp->id); }
int GetId()
{
static int i = ;
i++;
return i;
}
void AddNode(List **ppHead,List **ppEnd)
{
List *pTemp = (List *)malloc(sizeof(List));
pTemp->id = GetId();
pTemp->pNext = NULL; if(*ppHead == NULL)
{
*ppHead = pTemp;
}
else
{
(*ppEnd)->pNext = pTemp; }
*ppEnd = pTemp;
}
List *Search(List *pHead,List *pEnd,int n)
{
int i;
List *pFast = pHead;
List *pSlow = pHead;
for(i = ;i < n;i++)
{
pFast = pFast->pNext;
}
while(pFast)
{
pSlow = pSlow->pNext;
pFast = pFast->pNext;
}
return pSlow; }
2019-04-29 22:32:52 编程菜鸟自我反省,大佬勿喷,谢谢!!!
4-29 c语言之栈,队列,双向链表的更多相关文章
- C语言实现,队列可伸缩
两个栈实现一个队列,C语言实现,队列可伸缩,容纳任意数目的元素. 一.思路:1.创建两个空栈A和B:2.A栈作为队列的入口,B栈作为队列的出口:3.入队列操作:即是入栈A:4.出队列操作:若栈B为空, ...
- C语言函数调用栈
C语言函数调用栈 栈溢出(stack overflow)是最常见的二进制漏洞,在介绍栈溢出之前,我们首先需要了解函数调用栈. 函数调用栈是一块连续的用来保存函数运行状态的内存区域,调用函数(calle ...
- Leetcode栈&队列
Leetcode栈&队列 232.用栈实现队列 题干: 思路: 栈是FILO,队列是FIFO,所以如果要用栈实现队列,目的就是要栈实现一个FIFO的特性. 具体实现方法可以理解为,准备两个栈, ...
- java 集合 Connection 栈 队列 及一些常用
集合家族图 ---|Collection: 单列集合 ---|List: 有存储顺序 , 可重复 ---|ArrayList: 数组实现 , 查找快 , 增删慢 ---|LinkedList: 链表实 ...
- Java 容器之 Connection栈队列及一些常用
集合家族图 ---|Collection: 单列集合 ---|List: 有存储顺序 , 可重复 ---|ArrayList: 数组实现 , 查找快 , 增删慢 ---|LinkedList: 链表实 ...
- java面向对象的栈 队列 优先级队列的比较
栈 队列 有序队列数据结构的生命周期比那些数据库类型的结构(比如链表,树)要短得多.在程序操作执行期间他们才被创建,通常用他们去执行某项特殊的任务:当完成任务之后,他们就会被销毁.这三个数据结构还有一 ...
- C++实现一个简单的双栈队列
双栈队列的原理是用两个栈结构模拟一个队列, 一个栈A模拟队尾, 入队的元素全部压入此栈, 另一个栈B模拟队首, 出队时将栈A的元素弹入栈B, 将栈B的栈顶元素弹出 此结构类似汉诺塔, 非常经典, 这里 ...
- 栈&队列&并查集&哈希表(julyedu网课整理)
date: 2018-11-25 08:31:30 updated: 2018-11-25 08:31:30 栈&队列&并查集&哈希表(julyedu网课整理) 栈和队列 1. ...
- 《数据结构与算法分析:C语言描述》复习——第三章“线性表、栈和队列”——双向链表
2014.06.14 20:17 简介: 双向链表是LRU Cache中要用到的基本结构,每个链表节点左右分别指向上一个和下一个节点,能够自由地左右遍历. 图示: 实现: // My implemen ...
随机推荐
- Java语法基础学习DayTwelve(泛型)
一.泛型(Generic)在集合中的使用 1.作用 (1)解决元素存储的安全问题 (2)解决获取数据元素时,需要类型强转的问题 2.代码案例 //在集合没有使用泛型的情况下 List list = n ...
- Java语法基础学习DayEleven(Map)
一.Map接口 1.概述:Map与Collection并列存在,用于保存具有映射关系的数据Key-Value. Map接口 |- - - - -HashMap:Map的主要实现类 |- - - - - ...
- 自动化测试-12.selenium的弹出框处理
前言 不是所有的弹出框都叫alert,在使用alert方法前,先要识别出到底是不是alert.先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决. alert\confirm\prompt ...
- gitlab修改默认端口
部署gitlab的时候,一启动,发现80和8080端口已经被占用,无奈,只得先将监听80端口的nginx和监听8080端口的jenkins停止.这会儿有空,琢磨一下如何修改gitlab的默认端口. 修 ...
- manhattan plots in qqplot2
###manhattan plots in qqplot2library(ggplot2)setwd("~/ncbi/zm/XPCLR/")read.table("LW. ...
- SQL-存储过程-010
什么是存储过程? 可以理解为数据库中的方法,与C#中的方法一样,具有参数和返回值: 存储过程的优点? 提高运行速度:存储过程在创造是进行编译,以后运行存储过程都不需要再进行编译,极大化的提高了数据库的 ...
- 基于 Jenkins 构建持续集成任务
1.1 Jenkins 配置使用心得 我是在windows10上安装的,安装过程很简单,从官网上下载下来msi安装包,双击执行就好了.安装程序完成后会自动打开http://localhost:8080 ...
- APK重编译
最近沉迷某游戏 尝试了一些不可描述的东西 , 记录一下研究过程 具体是哪个app不公开 ... 准备工具 APKtool && signapk && jre .net ...
- kvm报错集
虚拟机console窗口看到一些报错 也可以在终端使用dmesg命令查看 [17617.701174] kvm [17393]: vcpu0 unhandled rdmsr: 0x1ad [19053 ...
- Window离线环境下如何安装pyhanlp
Hanlp在离线环境下的安装我是没有尝试过的,分享SunJW_2017的这篇文章就是关于如何在离线环境下安装hanlp的.我们可以一起来学习一下! HanLP是一款优秀的中文自然语言处理工具,可以实现 ...