Qt 学习之路 2(59):使用流处理 XML
Qt 学习之路 2(59):使用流处理 XML
本章开始我们将了解到如何使用 Qt 处理 XML 格式的文档。
XML(eXtensible Markup Language)是一种通用的文本格式,被广泛运用于数据交换和数据存储(虽然近年来 JSON 盛行,大有取代 XML 的趋势,但是对于一些已有系统和架构,比如 WebService,由于历史原因,仍旧会继续使用 XML)。XML 由 World Wide Web Consortium(W3C)发布,作为 SHML(Standard Generalized Markup Language)的一种轻量级方言。XML 语法类似于 HTML,与后者的主要区别在于 XML 的标签不是固定的,而是可扩展的;其语法也比 HTML 更为严格。遵循 XML 规范的 HTML 则被称为 XHTML(不过这一点有待商榷,感兴趣的话可以详见这里)。
我们说过,XML 类似一种元语言,基于 XML 可以定义出很多新语言,比如 SVG(Scalable Vector Graphics)和 MathML(Mathematical Markup Language)。SVG 是一种用于矢量绘图的描述性语言,Qt 专门提供了 QtSVG 对其进行解释;MathML 则是用于描述数学公式的语言,Qt Solutions 里面有一个 QtMmlWidget 模块专门对其进行解释。
另外一面,针对 XML 的通用处理,Qt4 提供了 QtXml 模块;针对 XML 文档的 Schema 验证以及 XPath、XQuery 和 XSLT,Qt4 和 Qt5 则提供了 QtXmlPatterns 模块。Qt 提供了三种读取 XML 文档的方法:
QXmlStreamReader:一种快速的基于流的方式访问良格式 XML 文档,特别适合于实现一次解析器(所谓“一次解析器”,可以理解成我们只需读取文档一次,然后像一个遍历器从头到尾一次性处理 XML 文档,期间不会有反复的情况,也就是不会读完第一个标签,然后读第二个,读完第二个又返回去读第一个,这是不允许的);- DOM(Document Object Model):将整个 XML 文档读入内存,构建成一个树结构,允许程序在树结构上向前向后移动导航,这是与另外两种方式最大的区别,也就是允许实现多次解析器(对应于前面所说的一次 解析器)。DOM 方式带来的问题是需要一次性将整个 XML 文档读入内存,因此会占用很大内存;
- SAX(Simple API for XML):提供大量虚函数,以事件的形式处理 XML 文档。这种解析办法主要是由于历史原因提出的,为了解决 DOM 的内存占用提出的(在现代计算机上,这个一般已经不是问题了)。
在 Qt4 中,这三种方式都位于 QtXml 模块中。Qt5 则将QXmlStreamReader/QXmlStreamWriter移动到 QtCore 中,QtXml 则标记为“不再维护”,这已经充分表明了 Qt 的官方意向。
至于生成 XML 文档,Qt 同样提供了三种方式:
QXmlStreamWriter,与QXmlStreamReader相对应;- DOM 方式,首先在内存中生成 DOM 树,然后将 DOM 树写入文件。不过,除非我们程序的数据结构中本来就维护着一个 DOM 树,否则,临时生成树再写入肯定比较麻烦;
- 纯手工生成 XML 文档,显然,这是最复杂的一种方式。
使用QXmlStreamReader是 Qt 中最快最方便的读取 XML 的方法。因为QXmlStreamReader使用了递增式的解析器,适合于在整个 XML 文档中查找给定的标签、读入无法放入内存的大文件以及处理 XML 的自定义数据。
每次QXmlStreamReader的readNext()函数调用,解析器都会读取下一个元素,按照下表中展示的类型进行处理。我们通过表中所列的有关函数即可获得相应的数据值:
| 类型 | 示例 | 有关函数 |
StartDocument |
– | documentVersion(),documentEncoding(),isStandaloneDocument() |
EndDocument |
– | |
StartElement |
<item> | namespaceUri(),name(),attributes(),namespaceDeclarations() |
EndElement |
</item> | namespaceUri(),name() |
Characters |
AT&T | text(),isWhitespace(),isCDATA() |
Comment |
<!– fix –> | text() |
DTD |
<!DOCTYPE …> | text(),notationDeclarations(),entityDeclarations(),dtdName(),dtdPublicId(),dtdSystemId() |
EntityReference |
™ | name(),text() |
ProcessingInstruction |
<?alert?> | processingInstructionTarget(),processingInstructionData() |
Invalid |
>&<! | error(), errorString() |
考虑如下 XML 片段:
<quote>Einmal ist keinmal</quote>
</doc>
|
1
2
3
|
<doc>
<quote>Einmal ist keinmal</quote>
</doc>
|
一次解析过后,我们通过readNext()的遍历可以获得如下信息:
StartElement (name() == "doc")
StartElement (name() == "quote")
Characters (text() == "Einmal ist keinmal")
EndElement (name() == "quote")
EndElement (name() == "doc")
EndDocument
|
1
2
3
4
5
6
7
|
StartDocument
StartElement (name() == "doc")
StartElement (name() == "quote")
Characters (text() == "Einmal ist keinmal")
EndElement (name() == "quote")
EndElement (name() == "doc")
EndDocument
|
通过readNext()函数的循环调用,我们可以使用isStartElement()、isCharacters()这样的函数检查当前读取的类型,当然也可以直接使用state()函数。
下面我们看一个完整的例子。在这个例子中,我们读取一个 XML 文档,然后使用一个QTreeWidget显示出来。我们的 XML 文档如下:
<entry term="sidebearings">
<page>10</page>
<page>34-35</page>
<page>307-308</page>
</entry>
<entry term="subtraction">
<entry term="of pictures">
<page>115</page>
<page>244</page>
</entry>
<entry term="of vectors">
<page>9</page>
</entry>
</entry>
</bookindex>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
<bookindex>
<entry term="sidebearings">
<page>10</page>
<page>34-35</page>
<page>307-308</page>
</entry>
<entry term="subtraction">
<entry term="of pictures">
<page>115</page>
<page>244</page>
</entry>
<entry term="of vectors">
<page>9</page>
</entry>
</entry>
</bookindex>
|
首先来看头文件:
{
Q_OBJECT
public:
explicit MainWindow(QWidget *parent = 0);
~MainWindow();
bool readFile(const QString &fileName);
private:
void readBookindexElement();
void readEntryElement(QTreeWidgetItem *parent);
void readPageElement(QTreeWidgetItem *parent);
void skipUnknownElement();
QTreeWidget *treeWidget;
QXmlStreamReader reader;
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class MainWindow : public QMainWindow
{
Q_OBJECT
public:
explicit MainWindow(QWidget *parent = 0);
~MainWindow();
bool readFile(const QString &fileName);
private:
void readBookindexElement();
void readEntryElement(QTreeWidgetItem *parent);
void readPageElement(QTreeWidgetItem *parent);
void skipUnknownElement();
QTreeWidget *treeWidget;
QXmlStreamReader reader;
};
|
MainWindow显然就是我们的主窗口,其构造函数也没有什么好说的:
QMainWindow(parent)
{
setWindowTitle(tr("XML Reader"));
treeWidget = new QTreeWidget(this);
QStringList headers;
headers << "Items" << "Pages";
treeWidget->setHeaderLabels(headers);
setCentralWidget(treeWidget);
}
MainWindow::~MainWindow()
{
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
MainWindow::MainWindow(QWidget *parent) :
QMainWindow(parent)
{
setWindowTitle(tr("XML Reader"));
treeWidget = new QTreeWidget(this);
QStringList headers;
headers << "Items" << "Pages";
treeWidget->setHeaderLabels(headers);
setCentralWidget(treeWidget);
}
MainWindow::~MainWindow()
{
}
|
接下来看几个处理 XML 文档的函数,这正是我们关注的要点:
{
QFile file(fileName);
if (!file.open(QFile::ReadOnly | QFile::Text)) {
QMessageBox::critical(this, tr("Error"),
tr("Cannot read file %1").arg(fileName));
return false;
}
reader.setDevice(&file);
while (!reader.atEnd()) {
if (reader.isStartElement()) {
if (reader.name() == "bookindex") {
readBookindexElement();
} else {
reader.raiseError(tr("Not a valid book file"));
}
} else {
reader.readNext();
}
}
file.close();
if (reader.hasError()) {
QMessageBox::critical(this, tr("Error"),
tr("Failed to parse file %1").arg(fileName));
return false;
} else if (file.error() != QFile::NoError) {
QMessageBox::critical(this, tr("Error"),
tr("Cannot read file %1").arg(fileName));
return false;
}
return true;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
bool MainWindow::readFile(const QString &fileName)
{
QFile file(fileName);
if (!file.open(QFile::ReadOnly | QFile::Text)) {
QMessageBox::critical(this, tr("Error"),
tr("Cannot read file %1").arg(fileName));
return false;
}
reader.setDevice(&file);
while (!reader.atEnd()) {
if (reader.isStartElement()) {
if (reader.name() == "bookindex") {
readBookindexElement();
} else {
reader.raiseError(tr("Not a valid book file"));
}
} else {
reader.readNext();
}
}
file.close();
if (reader.hasError()) {
QMessageBox::critical(this, tr("Error"),
tr("Failed to parse file %1").arg(fileName));
return false;
} else if (file.error() != QFile::NoError) {
QMessageBox::critical(this, tr("Error"),
tr("Cannot read file %1").arg(fileName));
return false;
}
return true;
}
|
readFile()函数用于打开给定文件。我们使用QFile打开文件,将其设置为QXmlStreamReader的设备。也就是说,此时QXmlStreamReader就可以从这个设备(QFile)中读取内容进行分析了。接下来便是一个 while 循环,只要没读到文件末尾,就要一直循环处理。首先判断是不是StartElement,如果是的话,再去处理 bookindex 标签。注意,因为我们的根标签就是 bookindex,如果读到的不是 bookindex,说明标签不对,就要发起一个错误(raiseError())。如果不是StartElement(第一次进入循环的时候,由于没有事先调用readNext(),所以会进入这个分支),则调用readNext()。为什么这里要用 while 循环,XML 文档不是只有一个根标签吗?直接调用一次readNext()函数不就好了?这是因为,XML 文档在根标签之前还有别的内容,比如声明,比如 DTD,我们不能确定第一个readNext()之后就是根标签。正如我们提供的这个 XML 文档,首先是 声明,其次才是根标签。如果你说,第二个不就是根标签吗?但是 XML 文档还允许嵌入 DTD,还可以写注释,这就不确定数目了,所以为了通用起见,我们必须用 while 循环判断。处理完之后就可以关闭文件,如果有错误则显示错误。
接下来看readBookindexElement()函数:
{
Q_ASSERT(reader.isStartElement() && reader.name() == "bookindex");
reader.readNext();
while (!reader.atEnd()) {
if (reader.isEndElement()) {
reader.readNext();
break;
}
if (reader.isStartElement()) {
if (reader.name() == "entry") {
readEntryElement(treeWidget->invisibleRootItem());
} else {
skipUnknownElement();
}
} else {
reader.readNext();
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
void MainWindow::readBookindexElement()
{
Q_ASSERT(reader.isStartElement() && reader.name() == "bookindex");
reader.readNext();
while (!reader.atEnd()) {
if (reader.isEndElement()) {
reader.readNext();
break;
}
if (reader.isStartElement()) {
if (reader.name() == "entry") {
readEntryElement(treeWidget->invisibleRootItem());
} else {
skipUnknownElement();
}
} else {
reader.readNext();
}
}
}
|
注意第一行我们加了一个断言。意思是,如果在进入函数的时候,reader 不是StartElement状态,或者说标签不是 bookindex,就认为出错。然后继续调用readNext(),获取下面的数据。后面还是 while 循环。如果是EndElement,退出,如果又是StartElement,说明是 entry 标签(注意我们的 XML 结构,bookindex 的子元素就是 entry),那么开始处理 entry,否则跳过。
那么下面来看readEntryElement()函数:
{
QTreeWidgetItem *item = new QTreeWidgetItem(parent);
item->setText(0, reader.attributes().value("term").toString());
reader.readNext();
while (!reader.atEnd()) {
if (reader.isEndElement()) {
reader.readNext();
break;
}
if (reader.isStartElement()) {
if (reader.name() == "entry") {
readEntryElement(item);
} else if (reader.name() == "page") {
readPageElement(item);
} else {
skipUnknownElement();
}
} else {
reader.readNext();
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
void MainWindow::readEntryElement(QTreeWidgetItem *parent)
{
QTreeWidgetItem *item = new QTreeWidgetItem(parent);
item->setText(0, reader.attributes().value("term").toString());
reader.readNext();
while (!reader.atEnd()) {
if (reader.isEndElement()) {
reader.readNext();
break;
}
if (reader.isStartElement()) {
if (reader.name() == "entry") {
readEntryElement(item);
} else if (reader.name() == "page") {
readPageElement(item);
} else {
skipUnknownElement();
}
} else {
reader.readNext();
}
}
}
|
这个函数接受一个QTreeWidgetItem指针,作为根节点。这个节点被当做这个 entry 标签在QTreeWidget中的根节点。我们设置其名字是 entry 的 term 属性的值。然后继续读取下一个数据。同样使用 while 循环,如果是EndElement就继续读取;如果是StartElement,则按需调用readEntryElement()或者readPageElement()。由于 entry 标签是可以嵌套的,所以这里有一个递归调用。如果既不是 entry 也不是 page,则跳过位置标签。
然后是readPageElement()函数:
{
QString page = reader.readElementText();
if (reader.isEndElement()) {
reader.readNext();
}
QString allPages = parent->text(1);
if (!allPages.isEmpty()) {
allPages += ", ";
}
allPages += page;
parent->setText(1, allPages);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
void MainWindow::readPageElement(QTreeWidgetItem *parent)
{
QString page = reader.readElementText();
if (reader.isEndElement()) {
reader.readNext();
}
QString allPages = parent->text(1);
if (!allPages.isEmpty()) {
allPages += ", ";
}
allPages += page;
parent->setText(1, allPages);
}
|
由于 page 是叶子节点,没有子节点,所以不需要使用 while 循环读取。我们只是遍历了 entry 下所有的 page 标签,将其拼接成合适的字符串。
最后skipUnknownElement()函数:
{
reader.readNext();
while (!reader.atEnd()) {
if (reader.isEndElement()) {
reader.readNext();
break;
}
if (reader.isStartElement()) {
skipUnknownElement();
} else {
reader.readNext();
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
void MainWindow::skipUnknownElement()
{
reader.readNext();
while (!reader.atEnd()) {
if (reader.isEndElement()) {
reader.readNext();
break;
}
if (reader.isStartElement()) {
skipUnknownElement();
} else {
reader.readNext();
}
}
}
|
我们没办法确定到底要跳过多少位置标签,所以还是得用 while 循环读取,注意位置标签中所有子标签都是未知的,因此只要是StartElement,都直接跳过。
好了,这是我们的全部程序。只要在main()函数中调用一下即可:
w.readFile("books.xml");
w.show();
|
1
2
3
|
MainWindow w;
w.readFile("books.xml");
w.show();
|
然后就能看到运行结果:
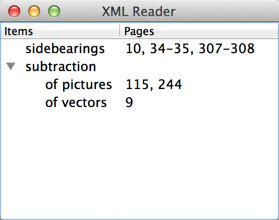
值得一提的是,虽然我们的代码比较复杂,但是思路很清晰,一层一层地处理,这正是递归下降算法的有一个示例。我们曾在前面讲解布尔表达式的树模型章节使用过这个思想。
Qt 学习之路 2(59):使用流处理 XML的更多相关文章
- Qt 学习之路 2(28):坐标系统
Qt 学习之路 2(28):坐标系统 豆子 2012年11月25日 Qt 学习之路 2 59条评论 在经历过实际操作,以及前面一节中我们见到的那个translate()函数之后,我们可以详细了解下 Q ...
- Qt 学习之路 2(67):访问网络(3)
Qt 学习之路 2(67):访问网络(3) 豆子 2013年11月5日 Qt 学习之路 2 16条评论 上一章我们了解了如何使用我们设计的NetWorker类实现我们所需要的网络操作.本章我们将继续完 ...
- Qt 学习之路 2(66):访问网络(2)
Home / Qt 学习之路 2 / Qt 学习之路 2(66):访问网络(2) Qt 学习之路 2(66):访问网络(2) 豆子 2013年10月31日 Qt 学习之路 2 27条评论 上一 ...
- Qt 学习之路 2(61):使用 SAX 处理 XML
Qt 学习之路 2(61):使用 SAX 处理 XML 豆子 2013年8月13日 Qt 学习之路 2 没有评论 前面两章我们介绍了使用流和 DOM 的方式处理 XML 的相关内容,本章将介绍 ...
- Qt 学习之路 2(60):使用 DOM 处理 XML
Qt 学习之路 2(60):使用 DOM 处理 XML 豆子 2013年8月3日 Qt 学习之路 2 9条评论 DOM 是由 W3C 提出的一种处理 XML 文档的标准接口.Qt 实现了 DO ...
- Qt 学习之路 2(53):自定义拖放数据
Qt 学习之路 2(53):自定义拖放数据 豆子 2013年5月26日 Qt 学习之路 2 13条评论上一章中,我们的例子使用系统提供的拖放对象QMimeData进行拖放数据的存储.比如使用QM ...
- Qt 学习之路 2(51):布尔表达式树模型
Qt 学习之路 2(51):布尔表达式树模型 豆子 2013年5月15日 Qt 学习之路 2 17条评论 本章将会是自定义模型的最后一部分.原本打算结束这部分内容,不过实在不忍心放弃这个示例.来自于 ...
- Qt 学习之路 2(36):二进制文件读写
Qt 学习之路 2(36):二进制文件读写 豆子 2013年1月6日 Qt 学习之路 2 20条评论 在上一章中,我们介绍了有关QFile和QFileInfo两个类的使用.我们提到,QIODevice ...
- Qt 学习之路 2(35):文件
Qt 学习之路 2(35):文件 豆子 2013年1月5日 Qt 学习之路 2 12条评论 文件操作是应用程序必不可少的部分.Qt 作为一个通用开发库,提供了跨平台的文件操作能力.从本章开始,我们来了 ...
随机推荐
- C++中不可重载5个运算符
C++中不可重载的5个运算符 C++中的大部分运算符都是可以重载的,只有以下5个运算符不可以重载,他们是: 1 .(点运算符)通常用于去对象的成员,但是->(箭头运算符),是可以重载的 2 ...
- EOFException异常的处理
TOmcat启动后报:IOException while loading persisted sessions: Java.io.EOFException错误 - IOException while ...
- cmd命令删除文件及文件夹
rmdir /s/q wenjianming 其中: /s 是代表删除所有子目录跟其中的档案. /q 是不要它在删除档案或目录时,不再问我 Yes or No 的动作.
- Composert 的命令
(1) php artisan ----查看所有的命令帮助 (2) php artisan make:controller StudentController ----创建一个控 ...
- 19、SOAP安装,运用与比对结果解释
转载:http://www.dengfeilong.com/post/Soap2.html https://blog.csdn.net/zhu_si_tao/article/details/71108 ...
- 关于Rest Framework中View、APIView与GenericAPIView的对比分析
关于Rest Framework中View.APIView与GenericAPIView的对比分析 https://blog.csdn.net/odyssues_lee/article/detail ...
- Entity Framework 6.0 Tutorials(8):Custom Code-First Conventions
Custom Code-First Conventions: Code-First has a set of default behaviors for the models that are ref ...
- 跨库连接报错Server 'myLinkedServer' is not configured for RPC
Solution: Problem is most likely that RPC is not configured for your linked server. That is not a de ...
- C# JackLib系列之字体使用
字体的使用一般我们都是使用系统字体,这样比较方便,直接 Font font=new Font("微软雅黑",16f,FontStyle.Bold); 但是当我们用到一个系统没有的字 ...
- MySQL性能调优与架构设计——第3章 MySQL存储引擎简介
第3章 MySQL存储引擎简介 3.1 MySQL 存储引擎概述 MyISAM存储引擎是MySQL默认的存储引擎,也是目前MySQL使用最为广泛的存储引擎之一.他的前身就是我们在MySQL发展历程中所 ...