关于在scrapy中使用xpath
1. 还是以虎嗅为例,他给我返回的是一个json格式的json串

2.那么我需要操作的就是把json串转换成我们的字典格式再进行操作
str=json.loads(response.body)['data'] #这边是拿到响应体数据,然后进行序列化成字典,拿到字典中key为data的的值.是一个字符串
3.自己导入选择器
from scrapy.selector import Selector
4.使用Selector的xpath方法获取内容
result = Selector(text=你从json提取出来的str).xpath('你的xpath表达式').extract()
5.使用效果
我把上一篇虎嗅的在parse中修改了来示范一下
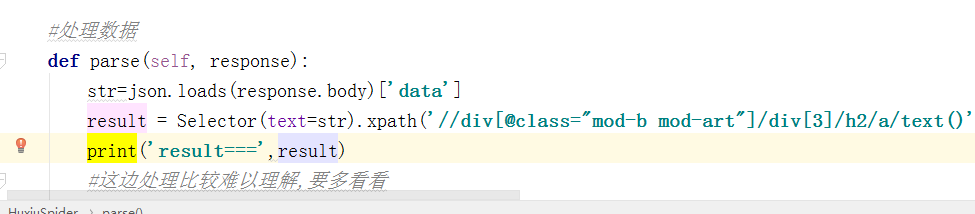
#处理数据
def parse(self, response):
str=json.loads(response.body)['data']
result = Selector(text=str).xpath('//div[@class="mod-b mod-art"]/div[3]/h2/a/text()').extract()
print('result===',result)
#这边处理比较难以理解,要多看看

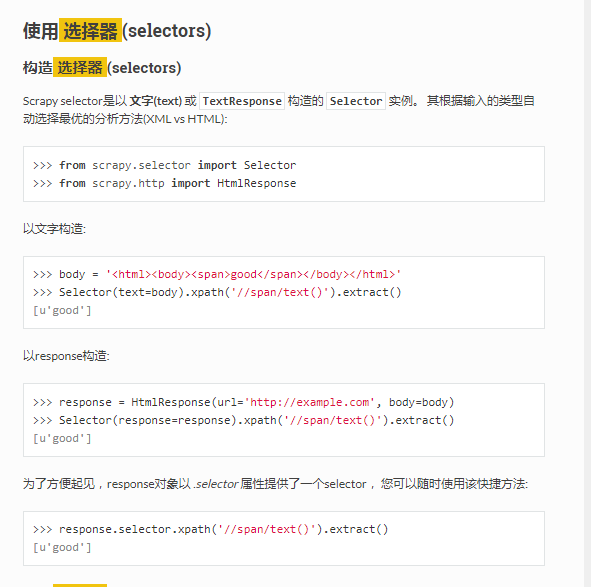
5.文档
当输入 response.selector 时, 您将获取到一个可以用于查询返回数据的selector(选择器),
以及映射到 response.selector.xpath() 、 response.selector.css() 的
快捷方法(shortcut): response.xpath() 和 response.css() 。
关于在scrapy中使用xpath的更多相关文章
- [ 转 ] scrapy 中解决 xpath 中的中文编码问题
1.问题描述: 实现定位<h2>品牌</h2>节点 brand_tag = sel.xpath("//h2[text()= '品牌']") 报错:Value ...
- scrapy中的xpath用法和css的用法
css 不包含那个类 response.css(".list-left dd:not(.page)") 获取属性和文本 img.css("a::text").e ...
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
- 在Scrapy中如何利用Xpath选择器从HTML中提取目标信息(两种方式)
前一阵子我们介绍了如何启动Scrapy项目以及关于Scrapy爬虫的一些小技巧介绍,没来得及上车的小伙伴可以戳这些文章: 手把手教你如何新建scrapy爬虫框架的第一个项目(上) 手把手教你如何新建s ...
- python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制
这篇博客主要是讲一下scrapy框架的使用,对于糗事百科爬取数据并未去专门处理 最后爬取的数据保存为json格式 一.先说一下pyharm怎么去看一些函数在源码中的代码实现 按着ctrl然后点击函数就 ...
- 论Scrapy中的数据持久化
引入 Scrapy的数据持久化,主要包括存储到数据库.文件以及内置数据存储. 那我们今天就来讲讲如何把Scrapy中的数据存储到数据库和文件当中. 终端指令存储 保证爬虫文件的parse方法中有可迭代 ...
- scrapy中对于item的把控
其实很简单,就是想要存储的位置发生改变.直接看例子,然后触类旁通. 以大众点评 评论的内容为例 ,位置:http://www.dianping.com/shop/77489519/review_mor ...
- 15,scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器 ...
- scrapy中的selenium
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
随机推荐
- 利用AdaBoost方法构建多个弱分类器进行分类
1.AdaBoost 思想 补充:这里的若分类器之间有比较强的依赖关系;对于若依赖关系的分类器一般使用Bagging的方法 弱分类器是指分类效果要比随机猜测效果略好的分类器,我们可以通过构建多个弱分类 ...
- 修改laravel中的pagination的样式
运行如下命令,拷贝出pagination样式到public/vendor目录下, 然后在pagination实例上调用links(‘传路径’)方法 使用起来非常方便,同时也可以自定义样式
- python3安装 feedparser
在看<集体智慧编程>时碰到python3环境下安装feedparser的问题,搜索发现很多人碰到此问题,最终找以下方法解决. how to install feedparser on py ...
- MVC异常过滤器在三种作用范围下的执行顺序
对于一般过滤器(即:除了IExceptionFilter ),当同时在Controller和Action中都设置了同一个过滤器后(例如IActionFilter),执行顺序一般是由外到里,即“全局”- ...
- ios7适配--uitableviewcell选中效果
ios7 UITableViewCell selectionStyle won't go back to blue up vote6down votefavorite 2 Xcode 5.0, iOS ...
- jQuery插件编写学习+实例——无限滚动
最近自己在搞一个网站,需要用到无限滚动分页,想想工作两年有余了,竟然都没有写过插件,实在惭愧,于是简单学习了下jQuery的插件编写,然后分享出来. 先说下基础知识,基本上分为两种,一种是对象级别的插 ...
- MongoDB整理笔记の指定命令和指定文件
MongoDB shell 不仅仅是一个交互式的shell,它也支持执行指定javascript 文件,也支持执行指定的命令片断.有了这个特性,就可以将MongoDB 与linux shell 完美结 ...
- 一个数组:1,1,2,3,5,8,13,21...+m,求第30位数是多少?用递归实现;(常考!!!)
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace Cons ...
- ftp操作方法整理
1.整理简化了下C#的ftp操作,方便使用 1.支持创建多级目录 2.批量删除 3.整个目录上传 4.整个目录删除 5.整个目录下载 2.调用方法展示, var ftp ...
- could not read data from '/Users/lelight/Desktop/ViewControllerLife/ViewControllerLife/Info.plist': The file “Info.plist” couldn’t be opened because there is no such file.
1.Info.plist放置至新文件夹下,路径被修改了,报错. could not read data from '/Users/lelight/Desktop/ViewControllerLife/ ...