15,scrapy中selenium的应用
引入
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器进行url请求发送则会加载出对应的动态加载的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
1,案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链接进入对应页面时,会发现当前页面展示的新闻数据是被动态加载出来的。需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的数据。
2,selenium在scrapy中使用的原理分析:
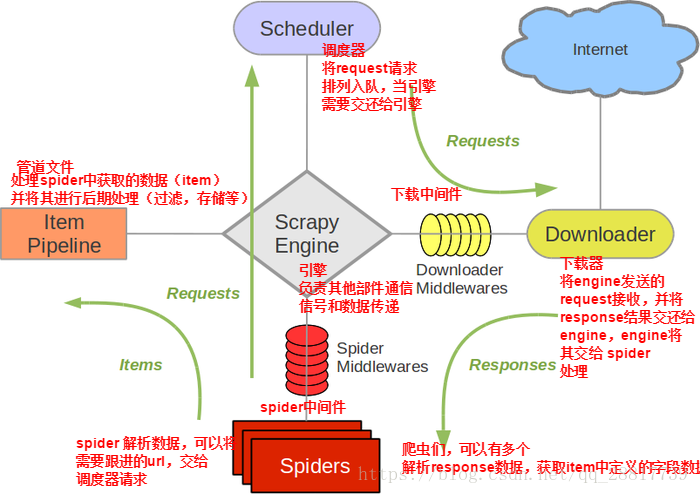
当引擎将国内板块url对应的请求提交给下载器后,下载进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接收到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获得动态数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,且对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3,selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件中的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启中间件
4,代码展示:
创建项目:
scrapy startproject wangyi
cd wangyi
scrapy genspider wangyinews http://war.163.com scrapy crawl wangyinews 完成代码编写后运行项目
- 爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver class WangyinewsSpider(scrapy.Spider):
name = 'wangyinews'
# allowed_domains = ['http://war.163.com/']
start_urls = ['http://war.163.com/'] def __init__(self):
self.bro = webdriver.Chrome(executable_path=r'E:\Google\Google\Chrome\Application\chromedriver.exe') def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title) def closed(self, spider):
print('关闭浏览器对象!')
self.bro.quit()
- 中间件文件(只需要修改下载中间件的process_response函数)
from time import sleep
from scrapy import signals
from scrapy.http import HtmlResponse def process_response(self, request, response, spider):
print('即将返回一个新的响应对象!!!')
bro = spider.bro
bro.get(url=request.url)
sleep(3)
page_text = bro.page_source
sleep(3)
return HtmlResponse(url=spider.bro.current_url,body=page_text, encoding='utf-8', request=request)
- setting文件
DOWNLOADER_MIDDLEWARES = {
'wangyi.middlewares.WangyiDownloaderMiddleware': 543,
}
15,scrapy中selenium的应用的更多相关文章
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中 selenium(中间件) + 语言处理 +mysql
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- 14 Scrapy中selenium的应用
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
随机推荐
- 极飞P20农业无人机多机协同作业飞行
来自为知笔记(Wiz)
- Java正则表达式—小应用—简易爬虫
在上一篇中,学习了正则表达式的四个功能.即匹配.分割.替换.获取. 利用获取功能,可以实现简单的网页爬虫. 4,获取:将字符串中的符合规则的子串取出. 获取功能的操作步骤: 1,将正则表达式 ...
- java常用框架总结
一.SpringMVC http://blog.csdn.net/evankaka/article/details/45501811 Spring Web MVC是一种基于Java的实现了Web MV ...
- 几个重要的开源视频会议SIP协议栈
视频会议系统由于需要与不同的终端进行连接,因此我们需要视频会议终端遵循统一的协议,H.323协议是视频会议软件使用最广泛的协议栈,但H.323设计得较为复杂,用户在调用H.323协议过程较多,因此利用 ...
- hdu-1856 More is better---带权并查集
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1856 题目大意: 一个并查集 计算每个集合的元素 找出元素最多的那个集合,输出元素的个数 解题思路: ...
- Android(java)学习笔记90:TextView 添加超链接(两种实现方式)
1. TextView添加超链接: TextView添加超链接有两种方式,它们有区别于WebView: (1)方式1: LinearLayout layout = new LinearLayout(t ...
- Android(java)学习笔记87:Android音视频MediaRecorder用法
1. Android语音录制可以通过 MediaRecorder 和 AudioRecorder: MediaRecorder本来是多媒体录制控件,可以同时录制视频和语音,当不指定视频源时就只录制语 ...
- java Socket 客户端服务端对接正确写法(BIO)
之前在工作中写过一些Socket客户端与服务端的代码,但是当时没有时间仔细研究,只能不报错先过的态度,对其细节了解不深,写的代码有各种问题也浑然不知,只是业务量级以及对接方对接代码没有出现出格的情况所 ...
- 多线程中使用HttpContext.Current为null的解决办法
HttpContext.Current.Server.MapPath(logFile) 这个是得到具体路径的方法 正常情况下是可以的 多线程情况下就为null 下边的代码原本的作用是把网站的异常 ...
- vue组件-使用插槽分发内容(slot)
slot--使用插槽分发内容(位置.槽口:作用: 占个位置) 官网API: https://cn.vuejs.org/v2/guide/components.html#使用插槽分发内容 使用组件时,有 ...