scrapy中对于item的把控
其实很简单,就是想要存储的位置发生改变。直接看例子,然后触类旁通。
以大众点评 评论的内容为例 ,位置:http://www.dianping.com/shop/77489519/review_more?pageno=1
数据存储形式由A 变成B
A:
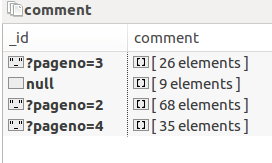
展开的话这样子:
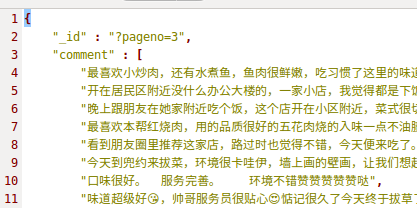
B:
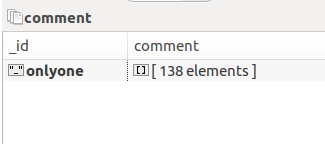
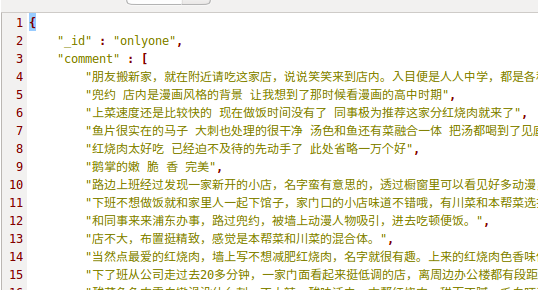
本质上看,就是多个相同类型的item可以合并,不需要那么多,分别来看下各自的代码:
A:
class GengduopinglunSpider(scrapy.Spider):
name = 'gengduopinglun'
start_urls = ['http://www.dianping.com/shop/77489519/review_more?pageno=1'] def parse(self, response):
item=PinglunItem()
comment = item['comment'] if "comment" in item else []
for i in response.xpath('//div[@class="content"]'):
for j in i.xpath('.//div[@class="J_brief-cont"]/text()').extract():
comment.append(j.strip())
item['comment']=comment
next_page = response.xpath(
'//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href').extract_first()
item['_id']=next_page
# item['_id']='onlyone'
if next_page != None:
next_page = response.urljoin(next_page)
# yield Request(next_page, callback=self.shop_comment,meta={'item': item})
yield Request(next_page, callback=self.parse,)
yield item
B:
class GengduopinglunSpider(scrapy.Spider):
name = 'gengduopinglun'
start_urls = ['http://www.dianping.com/shop/77489519/review_more?pageno=1'] def parse(self, response):
item=PinglunItem()
comment = item['comment'] if "comment" in item else []
for i in response.xpath('//div[@class="content"]'):
for j in i.xpath('.//div[@class="J_brief-cont"]/text()').extract():
comment.append(j.strip())
item['comment']=comment
next_page = response.xpath(
'//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href').extract_first()
# item['_id']=next_page
item['_id']='onlyone'
if next_page != None:
next_page = response.urljoin(next_page)
yield Request(next_page, callback=self.shop_comment,meta={'item': item})
# yield Request(next_page, callback=self.parse,)
# yield item def shop_comment(self, response):
item = response.meta['item']
comment = item['comment'] if "comment" in item else []
for i in response.xpath('//div[@class="content"]'):
for j in i.xpath('.//div[@class="J_brief-cont"]/text()').extract():
comment.append(j.strip())
item['comment']=comment
next_page = response.xpath(
'//div[@class="Pages"]/div[@class="Pages"]/a[@class="NextPage"]/@href').extract_first()
if next_page != None:
next_page = response.urljoin(next_page)
yield Request(next_page, callback=self.shop_comment,meta={'item': item})
yield item
B里面是有重复代码的,这个无关紧要,只是演示,注意看两个yield 的区别
以上只是演示scrapy中yield的用法,用来控制item,其余pipline,setting未展示.
scrapy中对于item的把控的更多相关文章
- Scrapy中的item是什么
这两天看Scrapy,看到item这个东西,觉得有点抽象,查了一下,有点明白了. Item 是保存爬取到的数据的容器:其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定 ...
- 关于ListView中item与子控件抢夺焦点的解决方法
1.在开发中,listview可以说是我们使用最频繁的控件之一了,但是关于listview的各种问题也是很多.当我们使用自定义布局的Listview的时候,如果在item的布局文件里面存在Button ...
- 手把手教你进行Scrapy中item类的实例化操作
接下来我们将在爬虫主体文件中对Item的值进行填充. 1.首先在爬虫主体文件中将Item模块导入进来,如下图所示. 2.第一步的意思是说将items.py中的ArticleItem类导入到爬虫主体文件 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- Scrapy中使用cookie免于验证登录和模拟登录
Scrapy中使用cookie免于验证登录和模拟登录 引言 python爬虫我认为最困难的问题一个是ip代理,另外一个就是模拟登录了,更操蛋的就是模拟登录了之后还有验证码,真的是不让人省心,不过既然有 ...
- scrapy中的request
scrapy中的request 初始化参数 class scrapy.http.Request( url [ , callback, method='GET', headers, body, cook ...
- [转]scrapy中的request.meta
作者:知乎用户链接:https://www.zhihu.com/question/54773510/answer/146971644 meta属性是字典,字典格式即{'key':'value'},字典 ...
- 论Scrapy中的数据持久化
引入 Scrapy的数据持久化,主要包括存储到数据库.文件以及内置数据存储. 那我们今天就来讲讲如何把Scrapy中的数据存储到数据库和文件当中. 终端指令存储 保证爬虫文件的parse方法中有可迭代 ...
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
随机推荐
- 给Java新手的一些建议——Java知识点归纳(Java基础部分)
原文出处:CSDN邓帅 写这篇文章的目的是想总结一下自己这么多年来使用java的一些心得体会,主要是和一些Java基础知识点相关的,所以也希望能分享给刚刚入门的Java程序员和打算入Java开发这个行 ...
- python 中的os模块
python os模块 Python os 模块提供了一个统一的操作系统接口函数 一.对于系统的操作 1.os.name 当前使用平台 其中 ‘nt’ 是 windows,’posix’ 是lin ...
- Shell记录-Shell脚本基础(三)
if...fi 语句的基本控制语句,它允许Shell有条件作出决定并执行语句. 语法 if [ expression ] then Statement(s) to be executed if exp ...
- PHP超级全局变量
$_get:地址栏上获取值 $_post:post表单发送数据 $_request:即有get也有post的内容 如果post和get重名:那么由设置项决定,比如request_crder=" ...
- Java并发编程原理与实战三十三:同步容器与并发容器
1.什么叫容器? ----->数组,对象,集合等等都是容器. 2.什么叫同步容器? ----->Vector,ArrayList,HashMap等等. 3.在多线程环境下,为什么不 ...
- [整理]C语言中的static静态对象
1.说明外部对象(静态外部变量和静态函数) (1)static 用于说明外部变量或函数,使该对象的作用域限定为被编译原文件的剩余部分,即从对象说明开始到所在源文件的结束部分: (2)被st ...
- 【Hadoop】Win7上搭建Hadoop开发环境,方法一
在Win7上,编写hadoop程序 操作系统:win7 hadoop版本:CDH3u6 1.下载安装JDK,以及Eclipse 2.新建JAVA Project 3.去cloudera网站下载hado ...
- HDU 2571 命运 (入门dp)
题目链接 题意:二维矩阵,左上角为起点,右下角为终点,如果当前格子是(x,y),下一步可以是(x+1,y),(x,y+1)或者(x,y*k) ,其中k>1.问最大路径和. 题解:入门dp,注意负 ...
- 【leetcode 简单】 第七十四题 缺失数字
给定一个包含 0, 1, 2, ..., n 中 n 个数的序列,找出 0 .. n 中没有出现在序列中的那个数. 示例 1: 输入: [3,0,1] 输出: 2 示例 2: 输入: [9,6,4,2 ...
- 16、DecimalFormat类
DecimalFormat类概述 在一些金融或者银行的业务里面,会出现这样千分位格式的数字,¥123,456.00,表示人民币壹拾贰万叁仟肆佰伍拾陆元整,java.text包下提供了一个Decimal ...