scrapy-splash抓取动态数据例子十四
一、介绍
本例子用scrapy-splash爬取超级TV网站的资讯信息,输入给定关键字抓取微信资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
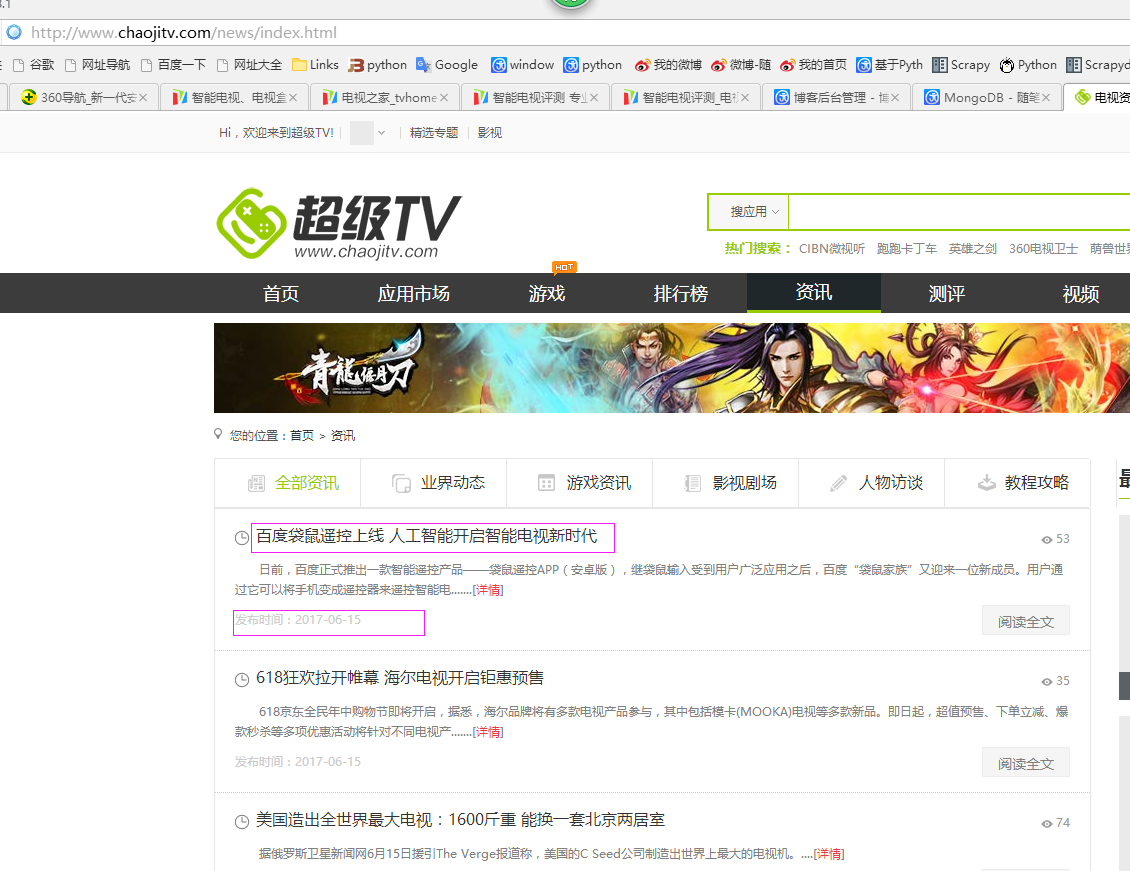
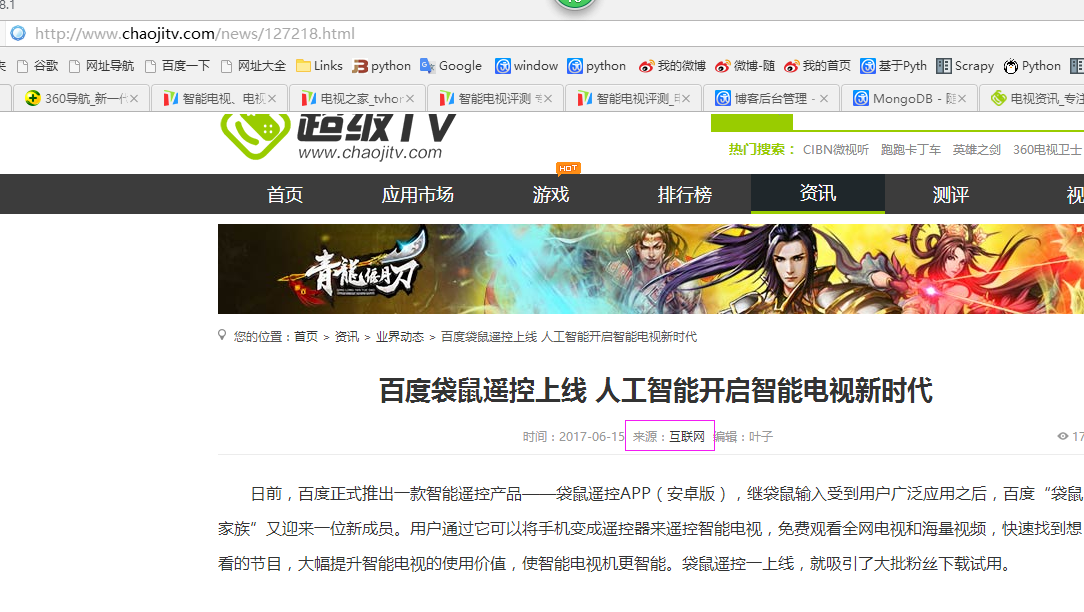

三、数据抓取
针对上面的网站信息,来进行抓取
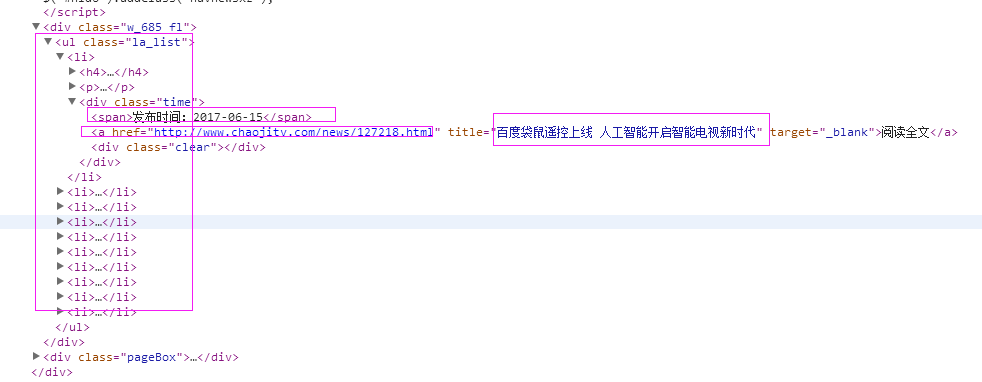
1、首先抓取信息列表
抓取代码:sels = site.xpath('//ul[@class="la_list"]/li')
2、抓取标题
抓取代码:title = str(sel.xpath('.//h4/a/text()')[0].extract())
3、抓取链接
抓取代码:url = str(sel.xpath('.//h4/a/@href')[0].extract())
4、抓取日期
抓取代码:strdates = sel.xpath('.//div[@class="time"]/span/text()')
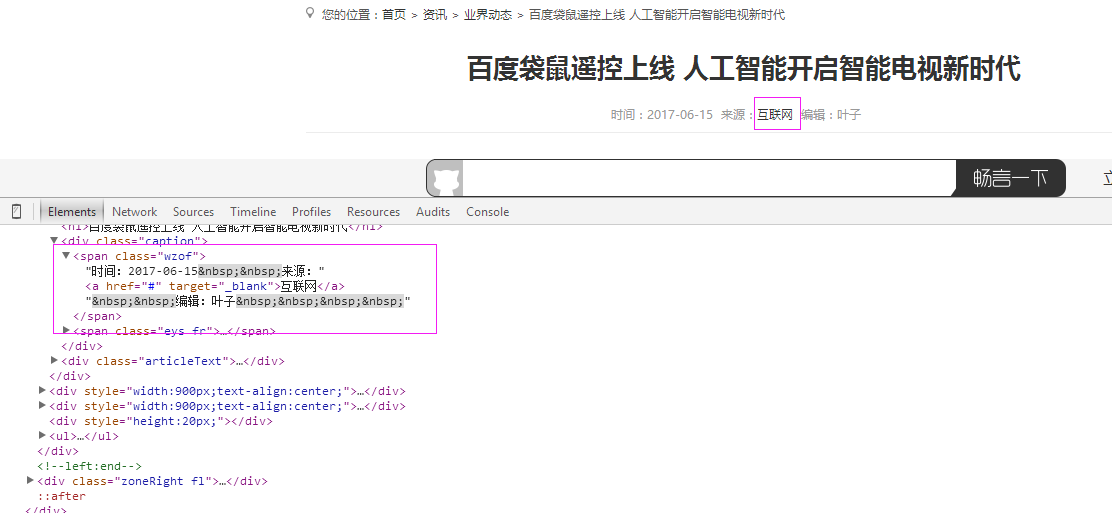
5、抓取来源
抓取代码:sources = site.xpath('//span[@class="wzof"]/a/text()');或sources = site.xpath('//span[@class="wzof"]/text()')
四、完整代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy_splash import SplashRequest
from scrapy_splash import SplashMiddleware
from scrapy.http import Request, HtmlResponse
from scrapy.selector import Selector
from scrapy_splash import SplashRequest
from scrapy_ott.items import SplashTestItem
from scrapy_ott.mongoDB import mongoDbBase
import scrapy_ott.IniFile
import sys
import os
import re
import time reload(sys)
sys.setdefaultencoding('utf-8') # sys.stdout = open('output.txt', 'w') class chaojitvSpider(Spider):
name = 'chaojitv'
db = mongoDbBase() configfile = os.path.join(os.getcwd(), 'scrapy_ott\setting.conf')
cf = scrapy_ott.IniFile.ConfigFile(configfile)
information_wordlist = cf.GetValue("section", "information_keywords").split(';')
websearchurl_list = cf.GetValue("chaojitv", "websearchurl").split(';')
start_urls = []
for url in websearchurl_list:
start_urls.append(url) # request需要封装成SplashRequest
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url
, self.parse
, args={'wait': ''}
)
def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: 四种格式 '2小时前'; '2天前' ; '昨天' ;'2017.2.12 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{2}-\d{2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.Comapre_to_days(currentDate, strDate[0]) <= 1:
return True, strDate[0]
return False, '' def parse(self, response):
site = Selector(response)
sels = site.xpath('//ul[@class="la_list"]/li') for sel in sels:
strdates = sel.xpath('.//div[@class="time"]/span/text()')
if len(strdates)>0: flag, date = self.date_isValid(str(strdates[0].extract()))
if flag:
title = str(sel.xpath('.//h4/a/text()')[0].extract())
for keyword in self.information_wordlist:
if title.find(keyword) > -1:
url = str(sel.xpath('.//h4/a/@href')[0].extract())
yield SplashRequest(url
, self.parse_item
, args={'wait': ''},
meta={'date': date, 'url': url,
'keyword': keyword, 'title': title}
) def parse_item(self, response):
site = Selector(response)
it = SplashTestItem()
it['title'] = response.meta['title']
it['url'] = response.meta['url']
it['date'] = response.meta['date']
it['keyword'] = response.meta['keyword']
sources = site.xpath('//span[@class="wzof"]/a/text()')
if len(sources)>0:
it['source'] = sources[0].extract()
else:
#时间:2017-06-15 来源:环球网 编辑:叶子
sources = site.xpath('//span[@class="wzof"]/text()')
if len(sources)>0:
ss= str(sources[0].extract()).split(':')
if len(ss)>2:
it['source']= ss[2].replace(u'编辑: ','').replace(' ','') self.db.SaveInformation(it)
return it
scrapy-splash抓取动态数据例子十四的更多相关文章
- scrapy-splash抓取动态数据例子十六
一.介绍 本例子用scrapy-splash爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电 ...
- scrapy-splash抓取动态数据例子十五
一.介绍 本例子用scrapy-splash爬取电视之家(http://www.tvhome.com/news/)网站的资讯信息,输入给定关键字抓取微信资讯信息. 给定关键字:数字:融合:电视 抓取信 ...
- scrapy-splash抓取动态数据例子十二
一.介绍 本例子用scrapy-splash通过搜狗搜索引擎,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二. ...
- scrapy-splash抓取动态数据例子十
一.介绍 本例子用scrapy-splash抓取活动行网站给定关键字抓取活动信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子一
目前,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面都无 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- scrapy-splash抓取动态数据例子七
一.介绍 本例子用scrapy-splash抓取36氪网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子六
一.介绍 本例子用scrapy-splash抓取中广互联网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信 ...
- scrapy-splash抓取动态数据例子五
一.介绍 本例子用scrapy-splash抓取智能电视网网站给定关键字抓取咨询信息. 给定关键字:打通:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站 ...
随机推荐
- Ubuntu破解开机密码
使用Ubuntu和使用windows系列产品一样,会忘记开机密码.难道我们在忘记开机密码的时候就必须重装系统吗?当然不是了!既然在windows下面我们可以破解开机密码,那么在Ubuntu里面一样可行 ...
- 关于might_sleep的一点说明---CONFIG_DEBUG_ATOMIC_SLEEP【转】
转自:http://blog.chinaunix.net/uid-23769728-id-3157536.html 这个函数我在看代码时基本上是直接忽略的(因为我知道它实际上不干什么事),不过因为内核 ...
- UVA 10183 How Many Fibs?
高精度推出大概600项fabi数,就包含了题目的数据范围,对于每组a,b,从1到600枚举res[i]即可 可以直接JAVA大数.我自己时套了C++高精度的版 JAVA 复制别人的 import ja ...
- python基础===map和zip的用法
>>> list1=[1,45,232,45,666,64] >>> list2=["ss","kein","to ...
- spring 声明式事务中try catch捕获异常
原文:http://heroliuxun.iteye.com/blog/848122 今天遇到了一个这个问题 最近遇到这样的问题,使用spring时,在业务层需要捕获异常(特殊需要),当前一般情况下不 ...
- linux环境下,双击直连ping私有地址时候出现Destination host unreachable 解决办法
在确保网线无故障的情况下,采取以下步骤 1.查看本机的hostname vim /etc/sysconfig/network 2.编辑/etc/hosts vim /etc/hosts 加入以下 ...
- html的表格
表格元素及相关样式 1.<table>标签:声明一个表格 2.<tr>标签:定义表格中的一行 3.<td>和<th>标签:定义一行中的一个单元格,td代 ...
- KVM(二)CPU 和内存虚拟化
1. 为什么需要 CPU 虚拟化 X86 操作系统是设计在直接运行在裸硬件设备上的,因此它们自动认为它们完全占有计算机硬件.x86 架构提供四个特权级别给操作系统和应用程序来访问硬件. Ring 是指 ...
- 阿里云ECS(Ubuntu)安装Docker
新购买的阿里云ECS主机,想使用云主机做一些Docker方面的配置及管理 首先测试是否能够远程登陆至主机 第一步:更新系统 查看系统版本及内核,Docker需要运行在3.8以上的内核 第二步:安装do ...
- Web.Config文件配置之限制上传文件大小和时间
在邮件发送系统或者其他一些传送文件的网站中,用户传送文件的大小是有限制的,因为这样不但可以节省服务器的空间,还可以提高传送文件的速度.下面介绍如何在Web.Config文件中配置限制上传文件大小与时间 ...