Python爬虫-代理池-爬取代理入库并测试代理可用性
目的:建立自己的代理池。可以添加新的代理网站爬虫,可以测试代理对某一网址的适用性,可以提供获取代理的 API。
整个流程:爬取代理 ----> 将代理存入数据库并设置分数 ----> 从数据库取出代理并检测 ----> 根据响应结果对代理分数进行处理 ----> 从 API 取出高分代理 ----> 用高分代理爬取目标网站
分析:
1、爬虫类的编写:负责抓取代理并返回。
- 因为不同的代理网站的网页结构不同,所以需要单独为每一个代理网页写爬虫。
- 调用每个爬取方法,依次返回结果。
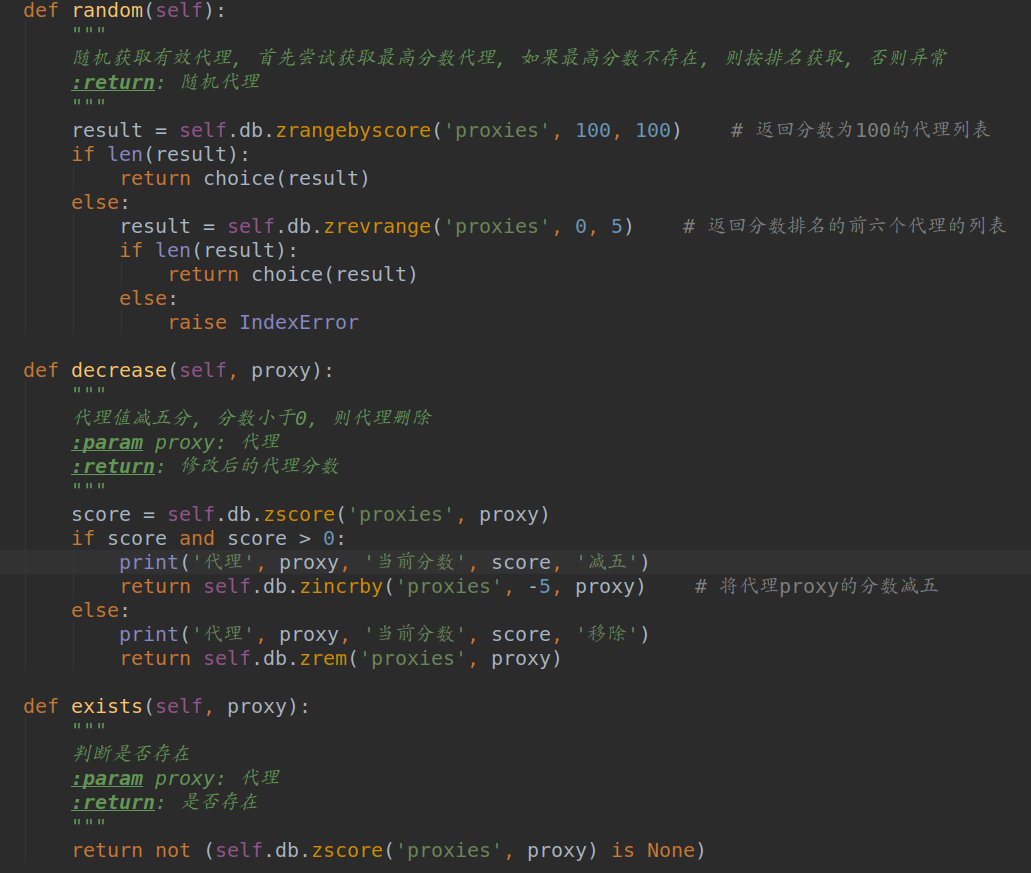
2、数据库类的编写:负责代理的存取与代理分数的设置。
- 判断待存入代理是否存在,不存在便存入数据库。
- 将代理存入数据库,首次入库的代理分数设置为100。
- 代理测试失败时,代理分数做相应的扣除,分数低于指定值时从数据库中移除。代理测试成功时,将代理分数重新设置为100。
- 需要使用代理时,从数据库中随机取出高分代理。
3、保存类的编写:负责执行爬取,并将结果存入数据库。
- 判断数据库是否已经达到满足值,根据返回值决定是否执行爬取。
- 将爬取得到的结果存入数据库
4、测试代理类的编写:负责测试代理对目标网站的可用性。
- 用每一个代理爬取目标网站,根据响应状态码对代理分数进行设置。
5、提取代理 API 的编写:负责提供获取代理信息的接口。
具体实现:
1、Crawler:

2、RedisClient:
3、Saver:

4、Tester:

5、API:

总结:这里我只爬取了两个代理网站的代理,西刺和快代理,可以在 Crawler 类中添加名称以 crwal_ 开始的方法来扩充。详细代码我放到 Github上了,https://github.com/ysl125963/proxy-pool
Python爬虫-代理池-爬取代理入库并测试代理可用性的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
随机推荐
- Luogu P1850换教室【期望dp】By cellur925
题目传送门 首先这个题我们一看它就是和概率期望有关,而大多数时候在OI中遇到他们时,都是与dp相关的. \(Vergil\)学长表示,作为\(NOIp2016\)的当事人,他们考前奶联赛一定不会考概率 ...
- 一个关于国密SM4的故事
一个关于国密SM4的故事 我的名字叫SM4,我还有三位兄长,分别是大哥SM1, 二哥SM2, 和三哥SM3.说起我的名字,故事要回到2006年的时候,我出生的时候并不是叫SM4的,而是叫做SMS4.只 ...
- 易爆物(X-Plosives )基础并查集
#include <iostream> #include <algorithm> using namespace std; + ; int fa[maxn]; int Find ...
- oracle 10g standby 设置
##########sample alter system set log_archive_dest_1 = 'LOCATION=USE_DB_RECOVERY_FILE_DEST' scope=bo ...
- req.getParameter()无法获取参数(附前端json序列化)
问题:前端用Ajax的post方式想servlet传递参数,servlet的getParameter()方法无法获取参数. 前端代码: $.ajax({ url: '/TestWeb/addBook' ...
- 02.第二章_C++ Primer学习笔记_变量和基本类型
2.1 基本内置类型 2.1.1 算术类型 算术类型包括两类:整型和浮点型 2.2 变量 2.3 复合类型 2.4 const限定符 2.5 处理类型 2.6 自定义数据结构
- 【C#】.net 发送get/post请求
基础学习 /// <summary> /// Http (GET/POST) /// </summary> /// <param name="url" ...
- 用户控件引用Entity Framework
背景: 今天在做软件的时候,出现了问题,我在项目里面添加了Entity Framework,在form的代码里引用没有问题,在userControl里引用就出了问题. 我检查app.config文件 ...
- Java断点续传(基于socket与RandomAccessFile的简单实现)
Java断点续传(基于socket与RandomAccessFile的简单实现) 这是一个简单的C/S架构,基本实现思路是将服务器注册至某个空闲端口用来监视并处理每个客户端的传输请求. 客户端先获得用 ...
- 命令模式和php实现
命令模式: 命令模式(Command Pattern):将一个请求封装为一个对象,从而使我们可用不同的请求对客户进行参数化:对请求排队或者记录请求日志,以及支持可撤销的操作.命令模式是一种对象行为型模 ...