python接口自动化:requests+ddt+htmltestrunner数据驱动框架
一、xc_datas:存放数据,xc_report:存放生成的报告,xc_tools:存放一些工具,get_api.py为执行程序
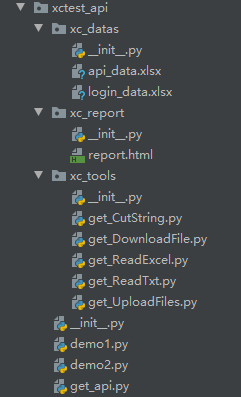
二、执行程序的实现代码如下:
#无token情况下,只支持get、post请求
import unittest
from HTMLTestRunner import HTMLTestRunner
from ddt import ddt,data
from xctest_api.xc_tools.get_CutString import *
from xctest_api.xc_tools.get_ReadExcel import *
import requests
import time @ddt
class get_apitest(unittest.TestCase):
@classmethod
def setUpClass(cls):
print('测试开始')
cls.s=requests.session()
@classmethod
def tearDownClass(cls):
print('测试结束')
def test_login(self):
lo=ReadExcel().read_excel('./xc_datas/login_data.xlsx')
if lo[3] == 'post':
result = self.s.post(lo[2], get_string().cut_string(lo[5]))
self.assert_login(lo[8],result.text)
elif lo[3]=='get':
result = self.s.get(lo[2])
self.assert_login(lo[8], result.text)
else:
print('暂无此请求类型方法')
@data(*ReadExcel().read_excel('./xc_datas/api_data.xlsx'))
def test_start(self, li):
if li[3] == 'post':
self.post_requests(li[4],li)
elif li[3] == 'get':
result = self.s.get(li[2])
self.assertIn(li[8], result.text)
else:
print('暂无此请求类型方法')
def assert_login(self,a,b):
if a in b.text:
print('登录成功')
else:
print('登录失败') def post_requests(self,c,li):
if c == 'application/x-www-form-urlencode':
result = self.s.post(li[2], get_string().cut_string(li[5]))
self.assertIn(li[8], result.text)
elif c == 'application/json':
result = self.s.post(li[2], json=get_string().cut_string(li[5]))
self.assertIn(li[8], result.text)
elif c == 'text/xml':
result = self.s.post(li[2], get_string().cut_string(li[5]).encode('utf-8'))
self.assertIn(li[8], result.text)
elif c == 'multipart/form-data':
if li[6]=='':
result = self.s.post(li[2],get_string().cut_string(li[5]))
self.assertIn(li[8], result.text)
else:
result = self.s.post(li[2], get_string().cut_string(li[5]),files=li[6])
self.assertIn(li[8], result.text)
else:
print('暂无此数据类型方法') if __name__ == '__main__':
suite = unittest.TestSuite()
suite.addTests(unittest.TestLoader().loadTestsFromTestCase(get_apitest))
name=time.strftime('%Y%m%d%H%M%S')
f = open('./xc_report/%d.html'%name, 'wb')
r = HTMLTestRunner(stream=f, title=u'EMS1.5', description=u'测试报告')
r.run(suite)
f.close()
python接口自动化:requests+ddt+htmltestrunner数据驱动框架的更多相关文章
- python接口自动化之用HTMLTestRunner生成html测试报告
[第一步]:引入HTMLTestRunner包 1.下载HTMLTestRunner,下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html ...
- 【python接口自动化】- DDT数据驱动测试
简单介绍 DDT(Date Driver Test),所谓数据驱动测试,简单来说就是由数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变.通过使用数据驱动测试的方法,可以在需要验证多组数据 ...
- 【python接口自动化-requests库】【三】优化重构requests方法
一.重构post请求方法 上一张讲了如何使用requests库发送post请求,但是有时候,我们写脚本,不可能这么简单,代码完全不可复用,重复工作,那我们是不是可以想象,把我们的get,post请求, ...
- 【python接口自动化-requests库】【二】requests库简单使用(入门)
一.post请求 前面讲了,我们get请求的时候,引入requests的包,然后直接使用get方法,那么post是不是一样的? 1.首先我们先引入requests import requests 2. ...
- 【python接口自动化-requests库】【一】requests库安装
1.概念 requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满 ...
- Python接口自动化--requests 2
# _*_ encoding:utf-8 _*_ import json import requests #post请求 payload = {"cindy":"hell ...
- Python接口自动化--requests 1
# _*_ encoding:utf-8 _*_ import requests #请求博客园首页,无参数的get请求 r = requests.get('http://www.cnblogs.com ...
- python接口自动化28-requests-html爬虫框架
前言 requests库的好,只有用过的人才知道,最近这个库的作者又出了一个好用的爬虫框架requests-html.之前解析html页面用过了lxml和bs4, requests-html集成了一些 ...
- python接口自动化24-有token的接口项目使用unittest框架设计
获取token 在做接口自动化的时候,经常会遇到多个用例需要用同一个参数token,并且这些测试用例跨.py脚本了. 一般token只需要获取一次就行了,然后其它使用unittest框架的测试用例全部 ...
随机推荐
- keras,在 fit 和 evaluate 中 都有 verbose 这个参数
1.fit 中的 verbose verbose:该参数的值控制日志显示的方式verbose = 0 不在标准输出流输出日志信息verbose = 1 输出进度条记录verbose = 2 ...
- SpringFramework中的BeanWrapper丶PropertyEditor
BeanWrapper是org.springframework.beans包下的一个借口,对应的实现类为BeanWrapperImpl,提供对应的get/set方法,并且设置属性的可读性和可写性. p ...
- DirectX屏幕捕获和输出视频
#include <Windows.h> #include <mfapi.h> #include <mfidl.h> #include <Mfreadwrit ...
- 【GDOI2017模拟12.9】最近公共祖先
题目 分析 首先,将这些节点按dfs序建一棵线段树. 因为按dfs序,所以在同一子树上的节点会放在线段树相邻的位置. 发现,对于一个位置x,它的权值只会对以x为根的子树造成影响. 当修改x时,用w[x ...
- AQS源码分析笔记
经过昨晚的培训.对AQS源码的理解有所加强,现在写个小笔记记录一下 同样,还是先写个测试代码,debug走一遍流程, 然后再总结一番即可. 测试代码 import java.util.concurre ...
- 原生JS获取li中的内容
- 文件操作:rewind()
函数名: rewind() 功 能: 将文件内部的位置指针重新指向一个流(数据流/文件)的开头 注意:不是文件指针而是文件内部的位置指针,随着对文件的读写文件的位置指针(指向当前读写字节)向后移动 ...
- 3D Computer Grapihcs Using OpenGL - 15 Draw Element Instanced
友情提示:继续本节之前,需要保存此前的代码,本节为了试验,会对代码做一些修改,但后续的修改需要我们把代码返回之前的进度. OpenGL内置支持Instancing,有专门的函数来处理这件事情. 为了方 ...
- React用dangerouslySetInnerHTML动态渲染HTML
React用dangerouslySetInnerHTML动态渲染HTML React项目,需要把后台返回的一段html代码在页面上显示 在render获取内容, //在render里获取内容 con ...
- java.sql.SQLException: The server time zone value 'Öùú±ê׼ʱ¼ä' is unrecognized or repr
在数据库连接配置文件中加入以下: 解决办法为在application文件中添加serverTimezone=UTC spring.datasource.url=jdbc:mysql://localho ...