scrapy项目5:爬取ajax形式加载的数据,并用ImagePipeline保存图片
1.目标分析:
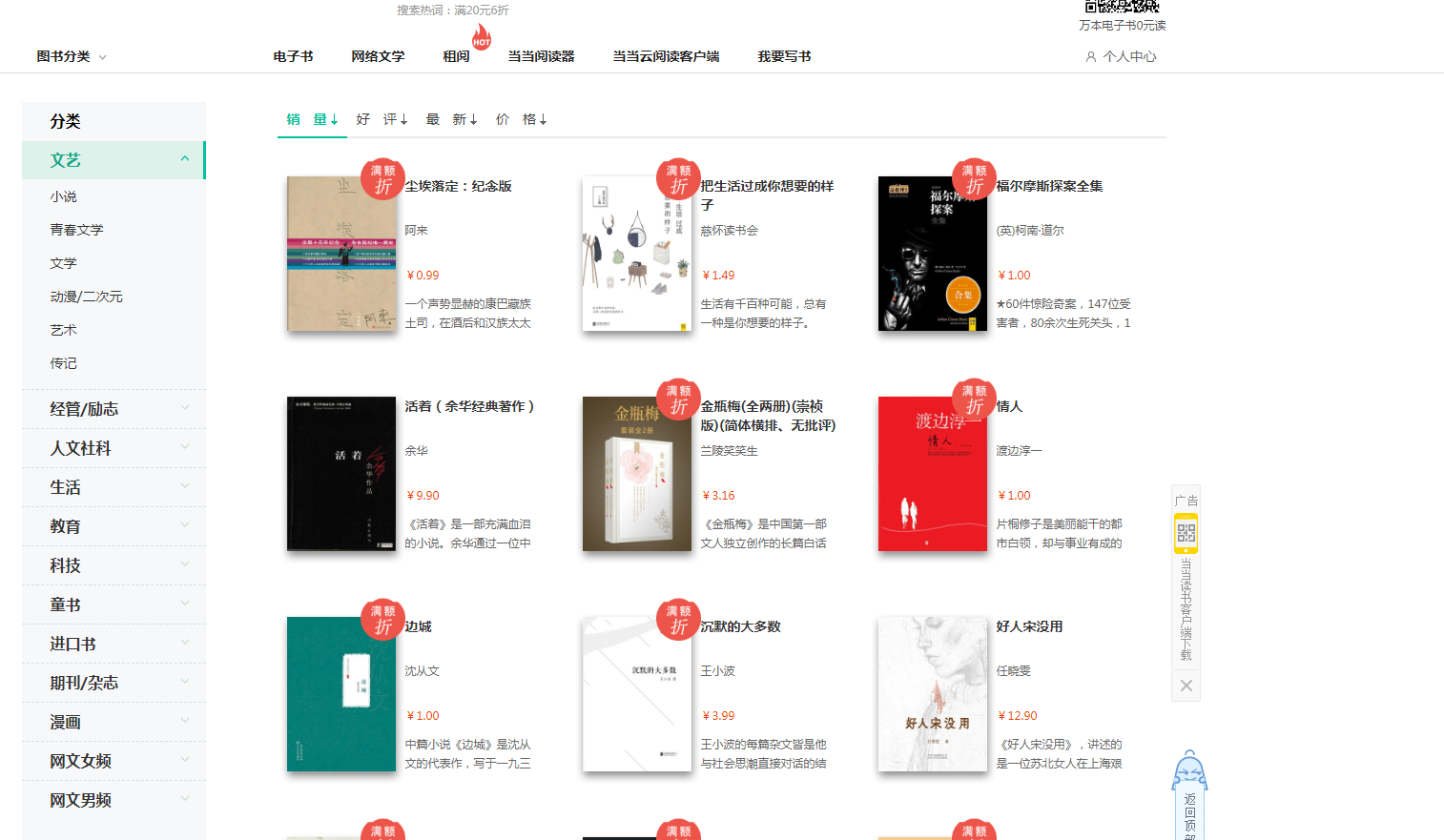
我们想要获取的数据为如下图:
1).每本书的名称
2).每本书的价格
3).每本书的简介

2.网页分析:
网站url:http://e.dangdang.com/list-WY1-dd_sale-0-1.html
如下图所示,每当我们将滚动条滚动到页面底部是,会自动加载数据,并且url不发生变化,诸如此种加载方式即为ajax方式加载的数据
第一步:通过Fiddler抓取加载过程中的数据,并观察规律:
图一:如下图:滚动鼠标让数据加载3次,下图是三次数据加载过程中Fiddler抓取的数据信息,对三次数据加载过程中的抓包信息中的 三个聚焦点进行关注并对比分析
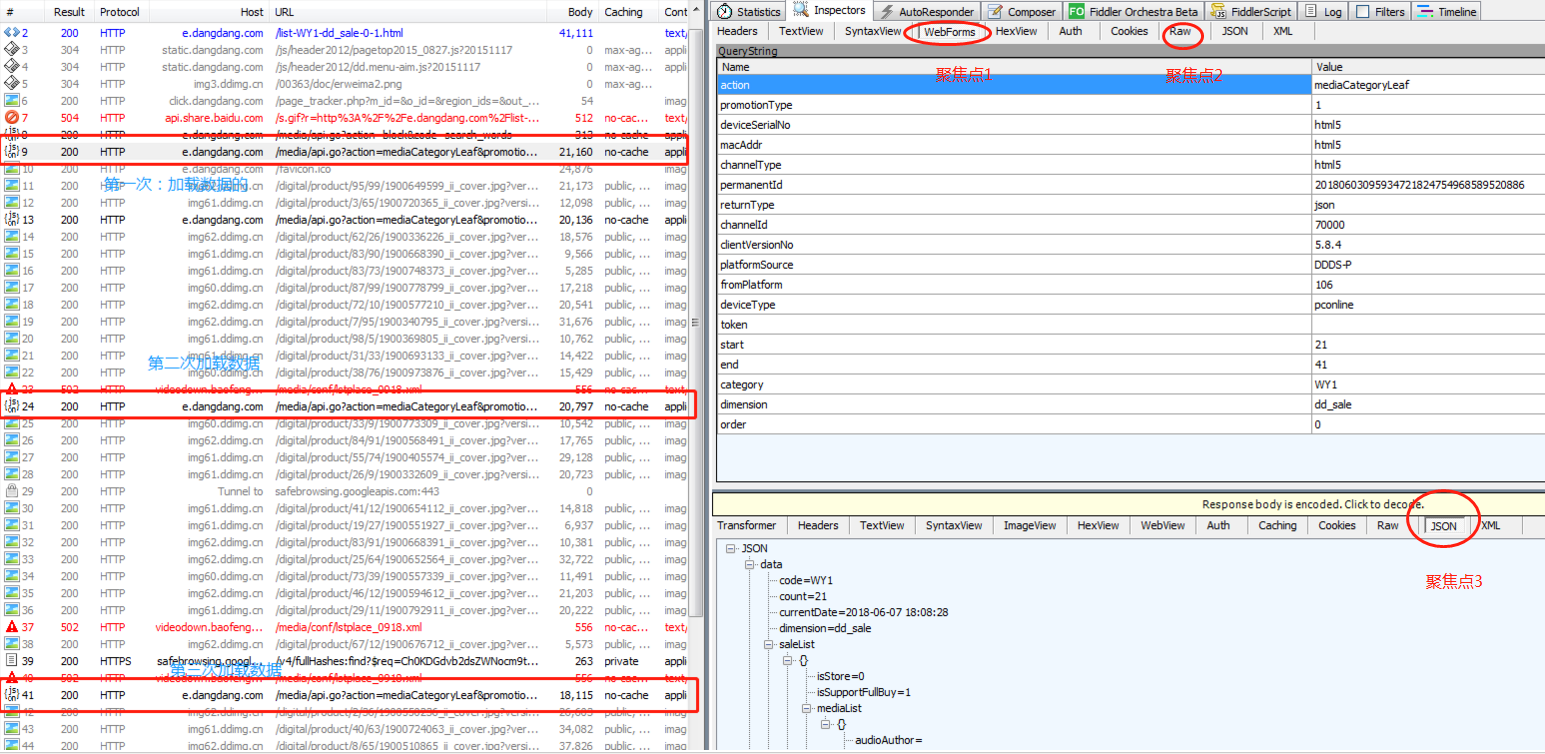
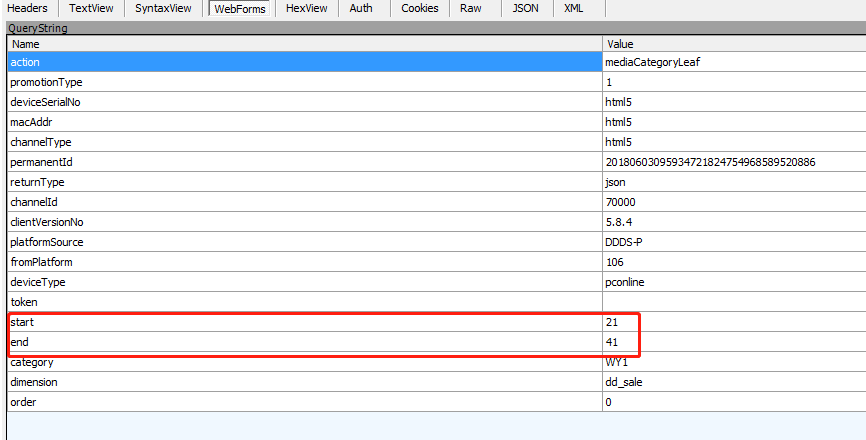
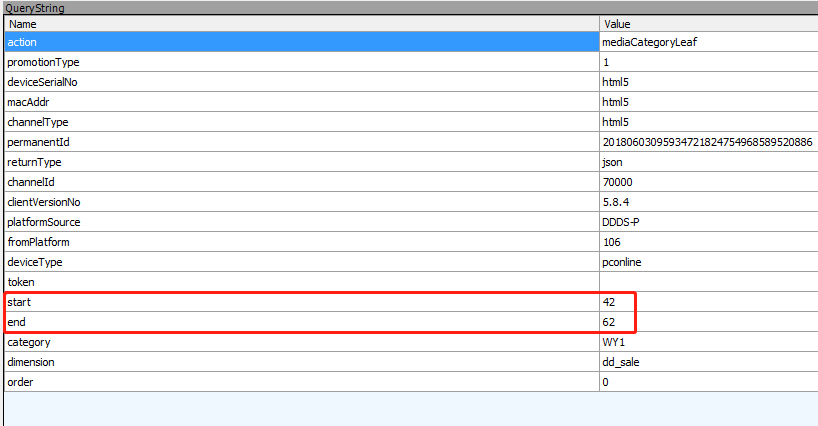
聚焦点1:规律,通过如下两幅图,可以看出,在数据加载过程中,只有start和end在变化,并且end-start=20,两次相连的的数据加载的start满足,后一个是在前一个的基础上加21
第一次加载数据:
第二次加载数据:
聚焦点2:(第一次加载)下图中红框中的url第一个问好后的参数就是聚焦点1中的Querystring中的数据,
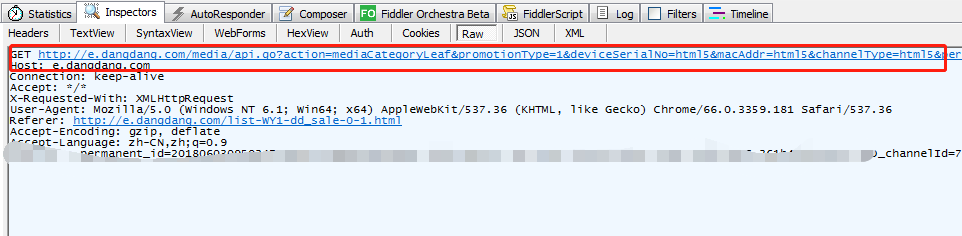
将上图中红色url复制在下方
将上述url复制到谷歌浏览器(带有xpath插件),我们就会得到如下的json数据(即为焦点三种相同的数据),这样的话我们想上述抓包获取的url发请求就能够拿到对应的json数据,我们要爬取的目标在图中用红框标出
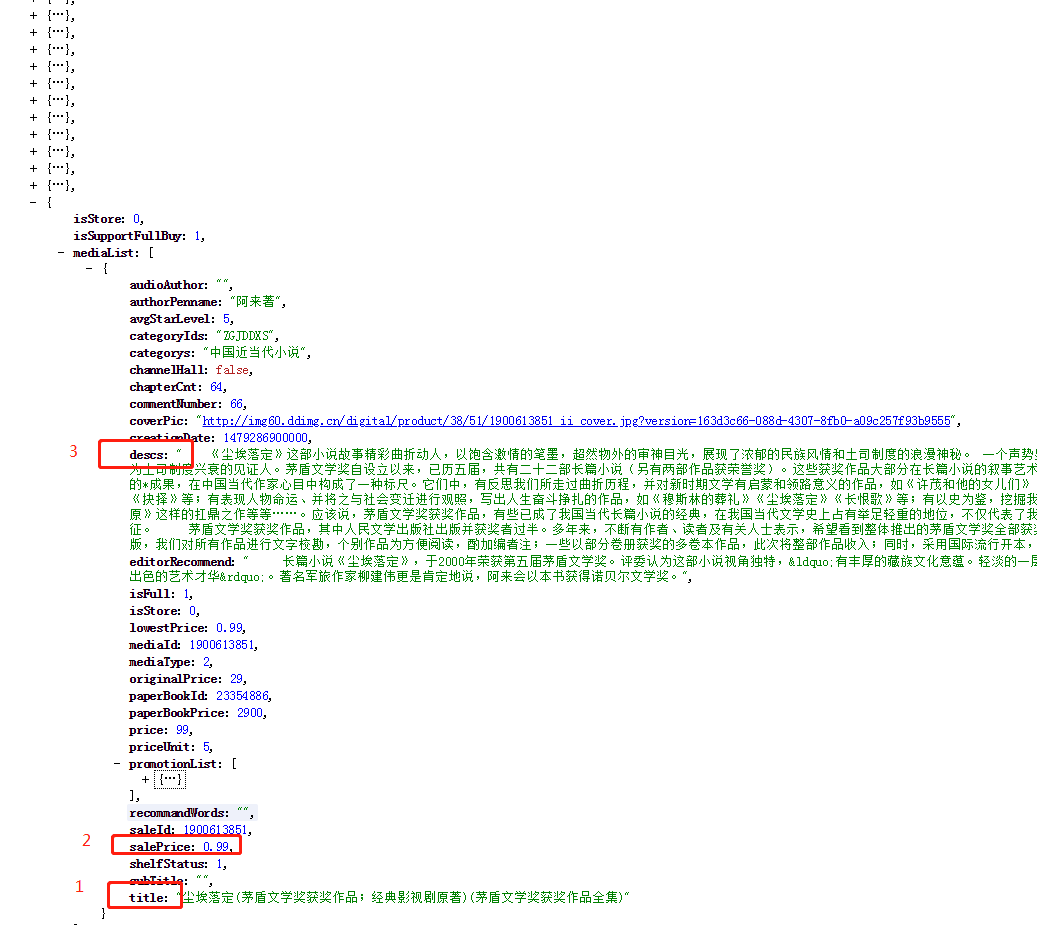
3 scrapy代码如下:
1).框架结构:

2).book.py文件
# -*- coding: utf-8 -*-
import scrapy
from Ebook.items import EbookItem
import json
class BookSpider(scrapy.Spider):
name = "book"
allowed_domains = ["dangdang.com"]
# start_urls = ['http://e.dangdang.com/media/api.go?']
# 重写start_requests方法
def start_requests(self):
# 通过Fiddler抓包获取的不含参数信息的url
url = 'http://e.dangdang.com/media/api.go?'
# 请求头信息User-Agent
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0',
}
# QueryString中start参数的初始值为21,在此处用start_num表示
start_num = 21 while True:
# QueryString中end参数为start+20,在此处用end_num表示
end_num = start_num + 20
# 构造QueryString查询字符串
formdata = {
'action':'mediaCategoryLeaf',
'promotionType':'',
'deviceSerialNo':'html5',
'macAddr':'html5',
'channelType':'html5',
'permanentId':'',
'returnType':'json',
'channelId':'',
'clientVersionNo':'5.8.4',
'platformSource':'DDDS-P',
'fromPlatform':'',
'deviceType':'pconline',
'token':'',
'start':str(start_num),
'end':str(end_num),
'category':'SK',
'dimension':'dd_sale',
'order':'',
}
# 发送请求
yield scrapy.FormRequest(url=url,formdata=formdata,headers=headers,callback = self.parse)
# 给start加21获取下一页的数据,如此规律循环直到所有数据抓取完毕
start_num += 21
# parse用来解析相应数据,即我们爬取到的json数据
def parse(self, response):
data = json.loads(response.text)['data']['saleList']
for each in data:
item = EbookItem()
info_dict = each['mediaList'][0]
# 书的标题
item['book_title'] = info_dict['title']
# 书的价格
item['book_price'] = info_dict['salePrice']
# 书的简介
item['book_desc'] = info_dict['descs']
# 书的封面图片链接
item['book_coverPic'] = info_dict['coverPic']
yield item
book.by
3).items.py文件
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy
class EbookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 标题
book_title = scrapy.Field()
# 价格
book_price = scrapy.Field()
# 简介
book_desc = scrapy.Field()
# 封面图片链接
book_coverPic = scrapy.Field()
items.py
4).pipelines.py文件 ImagesPipeline类的学习文档http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/media-pipeline.html#scrapy.pipeline.images.ImagesPipeline.item_completed
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json
from scrapy.pipelines.images import ImagesPipeline
import scrapy
from scrapy.utils.project import get_project_settings
import os
# EbookImagesPipeline是用来下载书的封面图片并的自定义类,继承于ImagesPipeline类
class EbookImagesPipeline(ImagesPipeline):
# settings.py文件中设置的下载下来的图片存贮的路径
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
# 发送url请求的方法
def get_media_requests(self,item,info):
# 从item中获取图片链接
image_url = item['book_coverPic']
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36'
}
# 发送请求下载图片
yield scrapy.Request(image_url,headers=headers)
# 当所有图片被下载完成后,item_completed方法被调用
def item_completed(self,result,item,info):
# result的结构为:(success, file_info_or_error)
# success:布尔型,表示图片是否下载成功
# file_info_or_error:是一个包含下列关键字的字典
# -->url:图片下载的url
# -->path:图片的存贮路径
# -->checksum:图片内容的MD5 hash
image_path = [x['path'] for ok,x in result if ok]
# 对下载下来的图片重命名
os.rename(self.IMAGES_STORE + '/' + image_path[0], self.IMAGES_STORE + '/'+ item['book_title'].encode('utf-8') + '.jpg')
return item
# 将数据保存到本地
class EbookPipeline(object):
def __init__(self):
# 定义文件
self.filename = open('bookinfo.json','w')
def process_item(self, item, spider):
# 将item中数据转化为json
text = json.dumps(dict(item),ensure_ascii=False) + '\n'
# 将内容写入到文件中
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self,spider):
# 关闭文件
self.filename.close()
pipelines.py
5).settings.py文件:根据项目需求进行配置即可
# -*- coding: utf-8 -*- # Scrapy settings for Ebook project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'Ebook'
SPIDER_MODULES = ['Ebook.spiders']
NEWSPIDER_MODULE = 'Ebook.spiders'
# 图片存储路径--新增
IMAGES_STORE = '/home/python/Desktop/01-爬虫/01-爬虫0530/ajax形式加载/Ebook/Ebook/spiders/bookimage'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'
# log日志存放文件
LOG_FILE = '123.log'
LOG_LEVEL = 'INFO'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 下载延迟
DOWNLOAD_DELAY = 2.5
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
# 关闭cookies
COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Ebook.middlewares.MyCustomSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'Ebook.middlewares.MyCustomDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# 配置管道文件
ITEM_PIPELINES = {
'Ebook.pipelines.EbookPipeline': 300,
'Ebook.pipelines.EbookImagesPipeline':350,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
settings.py
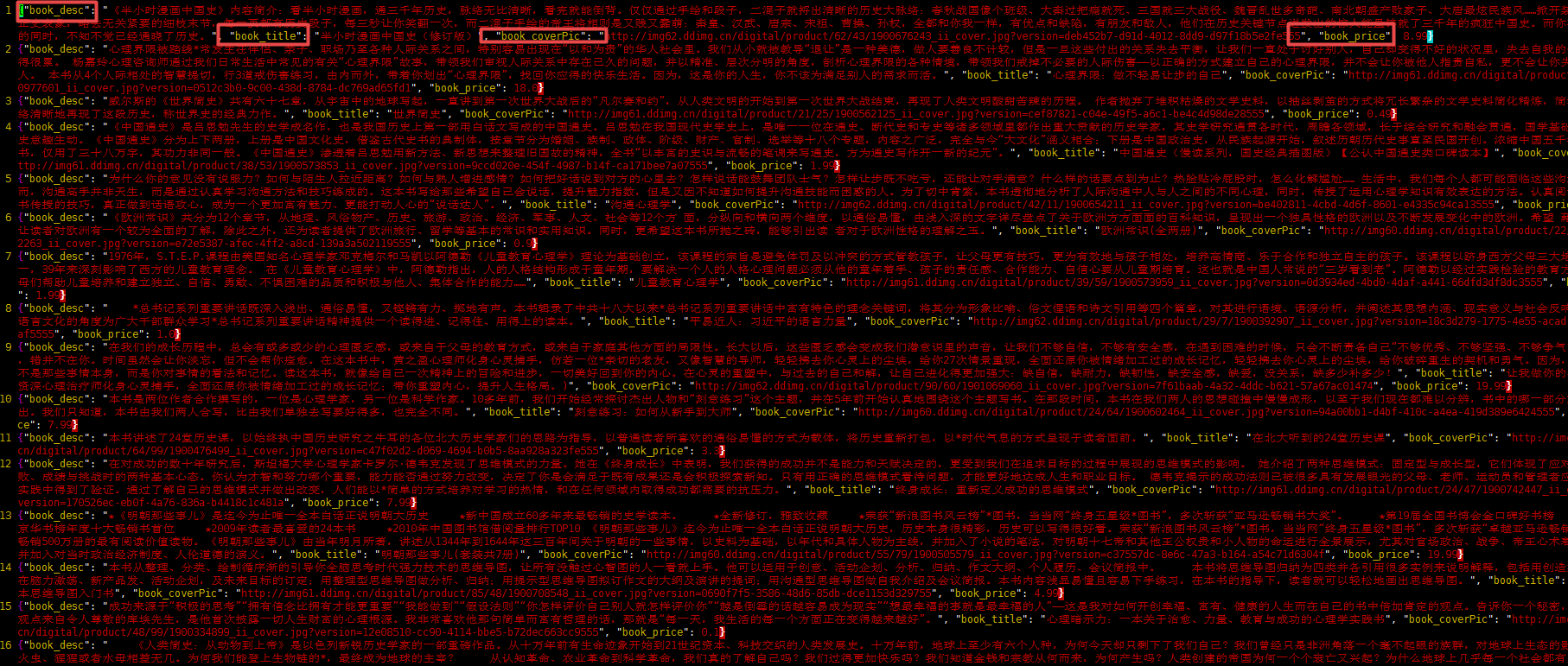
4.结果:
1).bookinfo.json文件
2).书的封面图片

scrapy项目5:爬取ajax形式加载的数据,并用ImagePipeline保存图片的更多相关文章
- 爬虫——爬取Ajax动态加载网页
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- ajax验证表单元素规范正确与否 ajax展示加载数据库数据 ajax三级联动
一.ajax验证表单元素规范正确与否 以用ajax来验证用户名是否被占用为例 1创建表单元素<input type="text" id="t"> 2 ...
- 使用ajax()方法加载服务器数据
使用ajax()方法加载服务器数据 使用ajax()方法是最底层.功能最强大的请求服务器数据的方法,它不仅可以获取服务器返回的数据,还能向服务器发送请求并传递数值,它的调用格式如下: jQuery.a ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- Scrapy实战:爬取http://quotes.toscrape.com网站数据
需要学习的地方: 1.Scrapy框架流程梳理,各文件的用途等 2.在Scrapy框架中使用MongoDB数据库存储数据 3.提取下一页链接,回调自身函数再次获取数据 重点:从当前页获取下一页的链接, ...
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
随机推荐
- http的导图
- 如何在Python中快速画图——使用Jupyter notebook的魔法函数(magic function)matplotlib inline
如何在Python中快速画图--使用Jupyter notebook的魔法函数(magic function)matplotlib inline 先展示一段相关的代码: #we test the ac ...
- O007、KVM 存储虚拟化
参考https://www.cnblogs.com/CloudMan6/p/5273283.html KVM 的存储虚拟化是通过存储池(Storage Pool) 和 卷(Volume)来管理的. ...
- Cesium-entiy闪烁范例
// name:"圆闪烁", function f1() { var x=1; var flog=true; viewer.entities.add({ name:"圆形 ...
- 日志:slf4j+logback 的配置与使用
1. 常用日志组件和选择 java开发日志处理是发现和调试bug所 必不可少的,那么现在企业中常用的日志组件有哪些呢,JCL . JUL. SLF4j.Log4j. Log4j2 . Logbac ...
- nodejs在Mac下的卸载
卸载: 在 node 官网上下载的安装包,用安装包安装的node.应该可以用一下命令行卸载: 在终端输入以下命令: sudo rm -rf /usr/local/{bin/{node,npm},lib ...
- win7下CodeIgniter安装
一.CodeIgniter是什么 CodeIgniter 是一套给 PHP 网站开发者使用的应用程序开发框架和工具包. 它的目标是让你能够更快速的开发,它提供了日常任务中所需的大量类库, 以及简单的接 ...
- 6.redis
1.Redis的安装以及客户端连接 安装:apt-get install redis-server 卸载:apt-get purge --auto-remove redis-server 启动:red ...
- kernel module insmod错误
kernel模块配置 Enable loadable module support 打开可加载模块支持,如果打开它则必须通过"make modules_install"把内核模块安 ...
- 1.SpringBoot整合Mybatis(CRUD的实现)
准备工具:IDEA jdk1.8 Navicat for MySQL Postman 一.新建Project 选择依赖:mybatis Web Mysql JDBC 项目结构 pom依赖: & ...