Storm元数据交互详解
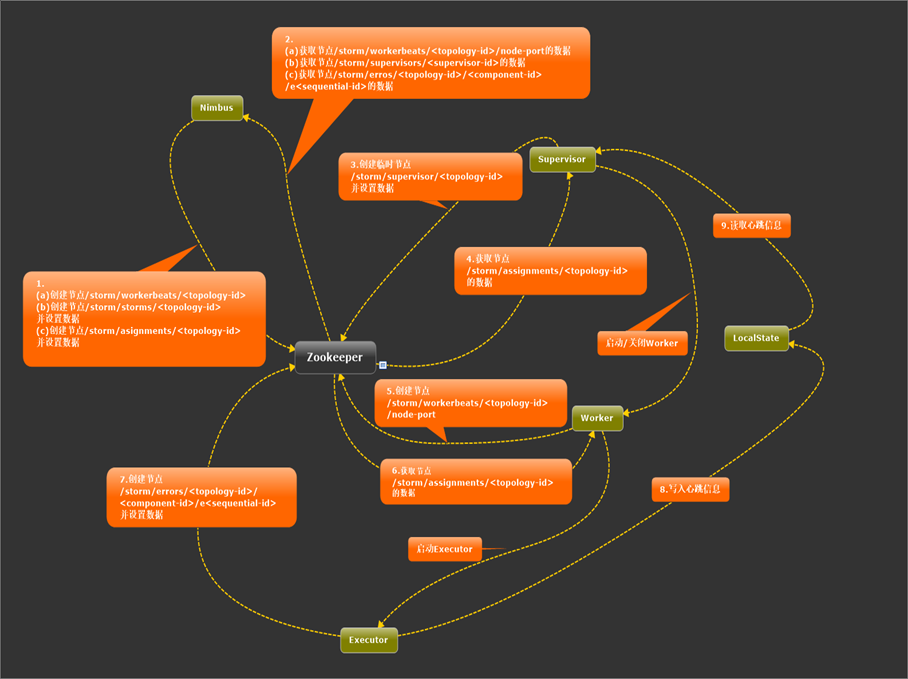
一、Nimbus
Nimbus既需要在Zookeeper中创建元数据,也需要从Zookeeper中获取元数据。
如上图箭头1所示:
1、对于路径a,Nimbus只会创建路径,不会设置数据,数据是稍后由Worker设置的。
2、对于路基b和c,Nimbus在创建她们的时候就会设置数据。
3、路径a和b只有在提交新的Topology时才会创建,且b中的数据设置好以后就不会再变化;c在第一次为该Topology进行任务分配的时候会创建,若任务分配计划有变,Nimbus会更新它内容。
如上图箭头2所示:
1、Nimbus需要从路径a读取当前已经被分配的Worker的运行状态。根据该信息,Nimbus可以得知哪些Worker状态正常,哪些需要被重新调度。同时还会获取到该Worker上所有的Executor信息,这些信息会通过UI呈现给用户。
2、从路径b可以获取当前集群中所有Supervisor状态,通过这些信息可以得知哪些Supervisor上还有空闲资源可用,哪些Supervisor不再活跃,需要将已经分配到它的任务分配到其他节点上。
3、从路径c上可以获取当前所有的错误信息并通过UI展现给用户。
二、Supervisor
Supervisor也需要通过Zookeepr来创建和获取元数据。除此之外,Supervisor还通过监控指定的本地文件来监测由它启动的所有的Worker的运行状态。
1、箭头3表示Supervisor在Zookeeper中创建的路径是/storm/supervisor/<supervisor-id>。新节点加入时会在该路径下创建一个znode节点。值得注意的是,该节点是一个临时节点,一旦Supervisor与Zookeepr的连接超时或断开,该节点会被自动删除。该目录下的znode节点列表代表了目前活跃的Supervisor,这保证了Nimbus能够及时得知当前集群中机器的状态,这是Nimbus可以进行任务分配的基础,也是Storm具有容错性以及扩展性的基础。
2、箭头4表示Supervisor需要获取数据的路径是/storm/assignments/<topology-id>。这个路径是Nimbus写入的对Topology的任务分配信息,Supervisor从该路径可以获取到Nimbus分配给它的所有任务。Supervisor在本地保存了上次的分配信息,对比这两部分的信息可以得知分配信息是否有变化。若发生变化,则需要进行任务的移除和启动。
3、箭头9表示Supervisor会从LocalState中获取由它启动的所有Worker的心跳信息。Supervisor每隔一段时间检查一次这些心跳信息,如果发现某个Worker在这段时间内没有更新心跳信息,表明该Worker当前的运行状态出了问题。这时Supervisor会杀死这个Worker(Worker本质是一个进程),原本分配给这个Worker的任务就会被重新分配。
三、Worker
Worker也需要利用Zookeeper来创建和获取元数据,同时它还需要利用本地的文件来记录自己的心跳信息。
1、箭头5表示Worker在Zookeeper中创建的路径是/storm/workerbeats/<topology-id>/node-port。在Worker启动时,将创建一个与其对应的znode节点,相当于对自身进行注册。需要注意的是,Nimbus在Topology被提交时只会创建路径/storm/workerbeats/<topology-id>,而不会设置数据,数据则等Worker启动之后由Worker创建。这样安排的目的之一是为了避免多个Worker同时创建路径时导致冲突。
2、箭头6表示Worker需要获取/storm/assignments/<topology-id>路径的数据,这里包含分配给它的任务信息。
3、箭头8表示Worker在LocalState中保存心跳信息。LocalState实际上将这些信息保存在本地文件中,Worker用这些信息与Supervisor保持心跳,每隔几秒钟需要更新一次心跳信息。因为Worker与Supervisor属于不同的进程,因此Storm采用本地文件的方式来传递心跳。
四、Executor
Executor只会利用Zookeeper来记录自己的运行错误信息。箭头7表示Executor在Zookeeper中创建的路径,每个Executor会在运行过程中记录发生的错误。
五、心跳维持
由上可知,Nimbus、Supervisor和Worker两两之间都要维持心跳信息,它们的心跳信息如下:
1、Nimbus和Supervisor之间通过/storm/supervisor/<supervisor-id>路径对应的数据进行心跳保持。该节点是临时节点,只要Supervisor死掉,对应路径的数据就会被删掉,Nimbus就会将原本分配给改Supervisor的任务重新分配。
2、Worker和Nimbus之间通过/storm/workerbeats/<topology-id>/node-port路径中的数据进行心跳维持。Nimbus会每隔一段时间获取该路径下的数据,同时Nimbus还会在它的内存中保存上一次的信息。如果发现某个Worker的心跳信息有一段时间没有更新,就认为该worker已经死掉了,Nimbus会对任务进行重新分配,将分配到该Worker的任务分配给其他的Worker。
3、Worker与Supervisor之间通过本地文件(LocalState)进行心跳保持。
Storm元数据交互详解的更多相关文章
- 【HANA系列】SAP HANA XS使用JavaScript数据交互详解
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA XS使用Jav ...
- 【HANA系列】【第一篇】SAP HANA XS使用JavaScript数据交互详解
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列][第一篇]SAP HANA XS ...
- Storm 学习之路(二)—— Storm核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的Storm流处理程序被称为Storm topology(拓扑).它是一个是由Spouts 和Bolts通过Stream连接起来的 ...
- Storm 系列(二)—— Storm 核心概念详解
一.Storm核心概念 1.1 Topologies(拓扑) 一个完整的 Storm 流处理程序被称为 Storm topology(拓扑).它是一个是由 Spouts 和 Bolts 通过 Stre ...
- Hibernate入门核心配置文件和orm元数据配置文件详解
框架是什么? 框架是用来提高开发效率的 封装了一些功能,我们需要使用这些功能时,调用即可,不用手动实现 所以框架可以理解为一个半成品的项目,只要懂得如何使用这些功能即可 Hibernate是完全面向对 ...
- Storm文档详解
1.Storm基础概念 1.1.什么是storm? Apache Storm is a free and open source distributed realtime computation sy ...
- 分布式流处理框架 Apache Storm —— 编程模型详解
一.简介 二.IComponent接口 三.Spout 3.1 ISpout接口 3.2 BaseRichSpout抽象类 四.Bolt 4.1 IBolt 接口 4. ...
- Storm 学习之路(五)—— Storm编程模型详解
一.简介 下图为Strom的运行流程图,在开发Storm流处理程序时,我们需要采用内置或自定义实现spout(数据源)和bolt(处理单元),并通过TopologyBuilder将它们之间进行关联,形 ...
- Storm 系列(五)—— Storm 编程模型详解
一.简介 下图为 Strom 的运行流程图,在开发 Storm 流处理程序时,我们需要采用内置或自定义实现 spout(数据源) 和 bolt(处理单元),并通过 TopologyBuilder 将它 ...
随机推荐
- [教学] Delphi IDE 文件搜寻功能
Delphi IDE 提供了一个方便的文件搜寻功能,操作如下: 点 Search 选单内的 Find in Files... 例如我们想搜寻 JFile 需要引用那一个源码,可输入如下: 输入关键字: ...
- 调试日志——基于stm32的智能声光报警器(三)
智能声光报警器基本功能调试完成. 1.通过拨码开关来设置LED闪烁的频率. 2.关门时喇叭不想,灯熄灭. 3.旁路模式时,灯处于闪烁状态,此时关门灯扔闪烁. 关于此次代码我觉得还是有可以优化的地方,电 ...
- 树莓派GPIO控制LED彩灯
树莓派使用GPIO接口来控制LED灯,自制五彩炫光的节日彩灯. 1.硬件准备 a. 树莓派(Raspberry Pi)一个 b. 彩色RGB二极管 c. 杜邦线 d. 5V电源引脚 以上所有零件均可在 ...
- 什么是PHP7中的孤儿进程与僵尸进程
什么是PHP7中的孤儿进程与僵尸进程 基本概念 我们知道在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程.子进程的结束和父进程的运行是一个异步过程,即父进程永远无法 ...
- Java编码算法和摘要算法
编码算法 编码算法是将一种形式转换成等价的另外一种形式.主要是为了方便某种特定场景的处理. 字母如何在计算机中表示呢? 用ASCII编码 那中文字符如何在计算机中表示呢? 用Unicode编码 如何同 ...
- Angular Elements
Angular Elements Angular Elements 就是打包成自定义元素的 Angular 组件.所谓自定义元素就是一套与具体框架无关的用于定义新 HTML 元素的 Web 标准. 自 ...
- FPGA之CORDIC算法实现_代码实现(下)
关于FPGA之CORDIC算法的纯逻辑实现,博主洋葱洋葱“https://www.cnblogs.com/cofin/p/9188629.html”以及善良的一休军“https://blog.csdn ...
- 记账本APP(2)
今天下载了Hbuiler,生成了一个记账本APP,目前里面只可以 输入今日消费 明天将会做出来记录以及计算总额于月消费.
- fixed layout android
http://benfrain.com/easy-css-fix-fixed-positioning-android-2-2-2-3/ http://caniuse.com/#feat=css-fix ...
- IDEA常见错误解决
tomcat控制台乱码 在tomcat的edit configurations里加入参数:-Dfile.encoding=UTF-8 导入的项目在重写时报 @Override is not all ...