Storm文档详解
1、Storm基础概念
1.1、什么是storm?
Apache Storm is a free and open source distributed realtime computation system.
Storm是免费开源的分布式实时计算系统
实时和离线的区别:
1 离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据、***任务调度
2 流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发。
1.2、Storm的核心组件
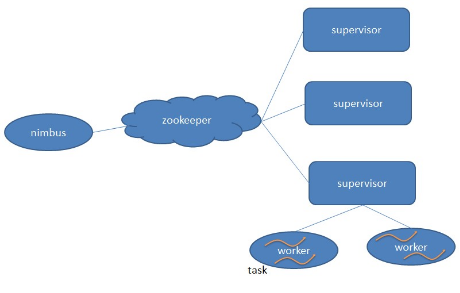
- Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
- Nimbus:负责资源分配和任务调度。
- Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。---通过配置文件设置当前supervisor上启动多少个worker。(Slot的个数)
- Worker:运行具体处理组件逻辑的进程(其实就是一个JVM)。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
- Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。(Task=线程=executor)
- Zookeeper:保存任务分配的信息、心跳信息、元数据信息。
1.3、并发度
用户指定的一个任务,可以被多个线程执行。
并发度的数量等于线程的数量。一个任务的多个线程,会被运行在多个Worker(JVM)上,有一种类似于平均算法的负载均衡策略。尽可能减少网络IO,和Hadoop中的MapReduce中的本地计算的道理一样。
1.4、Worker与topology
一个worker只属于一个topology,每个worker中运行的task只能属于这个topology。反之,一个topology包含多个worker,其实就是这个topology运行在多个worker上。
一个topology要求的worker数量如果不被满足,集群在任务分配时,根据现有的worker先运行topology。
如果当前集群中worker数量为0,那么最新提交的topology将只会被标识active,不会运行,只有当集群有了空闲资源之后,才会被运行。
1.5、Storm的编程模型
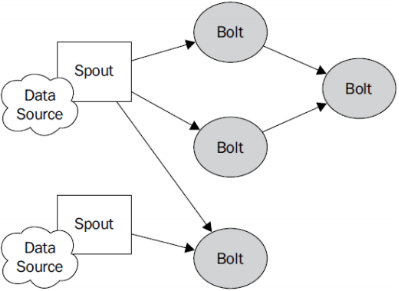
- DataSource:外部数据源
- Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt
- Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是Redis可以是mysql,或者其他。
- Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
- StreamGrouping:数据分组策略
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。(Random函数)
- Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。(Hash取模)
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。(Random函数),
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
2、Storm程序的并发机制
2.1、概念
- Workers (JVMs): 在一个物理节点上可以运行一个或多个独立的JVM 进程。一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
- Executors (threads): 在一个worker JVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。一个worker可以包含一个或多个executor, 每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集, 同时一个executor只能对应于一个component。
- Tasks(bolt/spout instances):Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。每一个task对应到一个线程,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder.setSpout和TopBuilder.setBolt来设置并行度 — 也就是有多少个task。
2.2、配置并行度
l 对于并发度的配置, 在storm里面可以在多个地方进行配置, 优先级为:
defaults.yaml < storm.yaml < topology-specific configuration <
<internal component-specific configuration < external component-specific configuration
- worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大于machines的数目
- executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数), 例如, setBolt("green-bolt", new GreenBolt(), 2)
- tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过 storm rebalance 命令任意调整。
|
Config conf = newConfig(); conf.setNumWorkers(2); //用2个worker topologyBuilder.setSpout("blue-spout", newBlueSpout(), 2); //设置2个并发度 topologyBuilder.setBolt("green-bolt", newGreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout"); //设置2个并发度,4个任务 topologyBuilder.setBolt("yellow-bolt", newYellowBolt(), 6).shuffleGrouping("green-bolt"); //设置6个并发度 StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology()); |

3个组件的并发度加起来是10,就是说拓扑一共有10个executor,一共有2个worker,每个worker产生10 / 2 = 5条线程。
绿色的bolt配置成2个executor和4个task。为此每个executor为这个bolt运行2个task。
l 动态的改变并行度
Storm支持在不 restart topology 的情况下, 动态的改变(增减) worker processes 的数目和 executors 的数目, 称为rebalancing. 通过Storm web UI,或者通过storm rebalance命令实现:
|
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10 |
3、Storm组件本地树

4、Storm zookeeper目录树

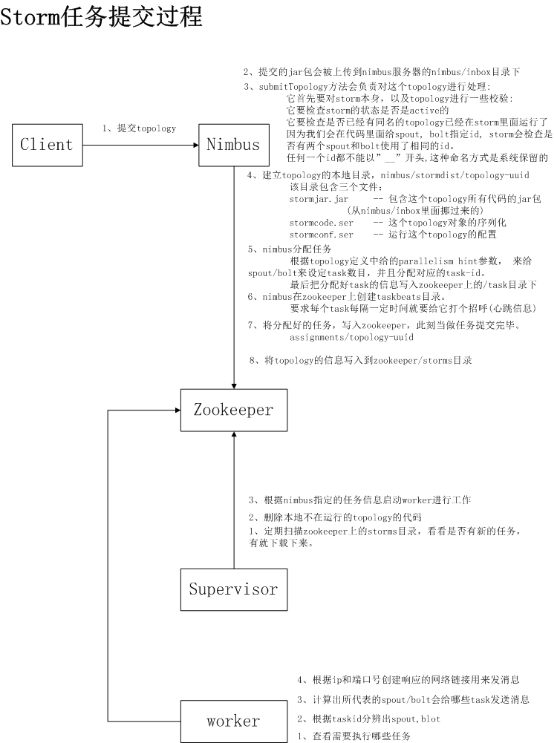
5、Storm 任务提交的过程

|
TopologyMetricsRunnable.TaskStartEvent[oldAssignment=<null>,newAssignment=Assignment[masterCodeDir=C:\Users\MAOXIA~1\AppData\Local\Temp\\e73862a8-f7e7-41f3-883d-af494618bc9f\nimbus\stormdist\double11-1-1458909887,nodeHost={61ce10a7-1e78-4c47-9fb3-c21f43a331ba=192.168.1.106},taskStartTimeSecs={1=1458909910, 2=1458909910, 3=1458909910, 4=1458909910, 5=1458909910, 6=1458909910, 7=1458909910, 8=1458909910},workers=[ResourceWorkerSlot[hostname=192.168.1.106,memSize=0,cpu=0,tasks=[1, 2, 3, 4, 5, 6, 7, 8],jvm=<null>,nodeId=61ce10a7-1e78-4c47-9fb3-c21f43a331ba,port=6900]],timeStamp=1458909910633,type=Assign],task2Component=<null>,clusterName=<null>,topologyId=double11-1-1458909887,timestamp=0] |
6.2、基本实现
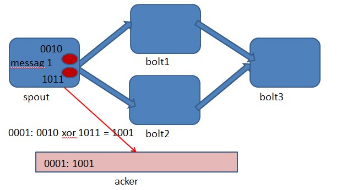
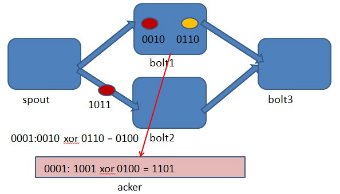
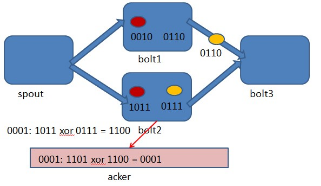
Storm 系统中有一组叫做"acker"的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。
acker任务保存了spout id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为"ack val", 它是树中所有消息的随机id的异或计算结果。
ack val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。 每当acker发现一棵树的ack val值为0的时候,它就知道这棵树已经被完全处理了

6.3、可靠性配置
有三种方法可以去掉消息的可靠性:
将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用;
Spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法;
最后,如果你不在意某个消息派生出来的子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。
7、Storm的安装
7.1、Storm安装
1、上传解压安装包
tar -zxvf apache-storm-1.1.1.tar.gz
mv apache-storm-1.1.1 storm
mv storm.yaml storm.yaml.bak
2、修改配置文件
#指定storm使用的zk集群
storm.zookeeper.servers:
- "zk-datanode-01"
- "zk-datanode-02"
- "zk-datanode-03"
#指定storm本地状态保存地址
storm.local.dir: "/usr/local/data/storm/workdir"
#指定storm集群中的nimbus节点所在的服务器
nimbus.host: "zk-datanode-01"
#指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
#指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx4096m"
#指定supervisor节点上,每个worker启动JVM最大可用内存大小
worker.childopts: "-Xmx512m"
#指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。
ui.childopts: "-Xmx768m"
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
3、分发安装包
scp -r storm/ zk-datanode-02:/usr/local/
scp -r storm/ zk-datanode-03:/usr/local/
4、启动集群
cd /usr/local/storm
1、在nimbus.host所属的机器上启动 nimbus服务
nohup bin/storm nimbus &
2、在nimbus.host所属的机器上启动ui服务
nohup bin/storm ui &
3、在其它个点击上启动supervisor服务
nohup bin/storm supervisor &
7.2、Storm任务提交
提交任务到storm集群上运行
bin/storm jar /usr/local/data/package/rcp-streamingengine-cardhz-V0.0.1.jar
com.dinpay.bdp.rcp.CardHzTopology CardHzTopology
Storm文档详解的更多相关文章
- MYSQL服务器my.cnf配置文档详解
MYSQL服务器my.cnf配置文档详解 硬件:内存16G [client] port = 3306 socket = /data/3306/mysql.sock [mysql] no-auto-re ...
- 【红外DDE算法】数字细节增强算法的缘由与效果(我对FLIR文档详解)
[红外DDE算法]数字细节增强算法的缘由与效果(我对FLIR文档详解) 1. 为什么红外系统中图像大多是14bit(甚至更高)?一个红外系统的性能经常以其探测的范围来区别,以及其对最小等效温差指标.首 ...
- Hibernate配置文档详解
Hibernate配置文档有框架总部署文档hibernate.cfg.xml 和映射类的配置文档 ***.hbm.xml hibernate.cfg.xml(文件位置直接放在src源文件夹即可) (在 ...
- 【PDF】java使用Itext生成pdf文档--详解
[API接口] 一.Itext简介 API地址:javadoc/index.html:如 D:/MyJAR/原JAR包/PDF/itext-5.5.3/itextpdf-5.5.3-javadoc/ ...
- Log4Net(二)之记录日志到文档详解
原创文章,转载必需注明出处:http://www.ncloud.hk/%E6%8A%80%E6%9C%AF%E5%88%86%E4%BA%AB/log4net-%E4%BA%8C-%E4%B9%8B% ...
- elastic search文档详解
在elastic search中文档(document)类似于关系型数据库里的记录(record),类型(type)类似于表(table),索引(index)类似于库(database). 文档一定有 ...
- 前端 HTML文档 详解
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 在MyEclipse中使用javadoc导出API文档详解
本篇文档介绍如何在MyEclipse中导出javadoc(API)帮助文档,并且使用htmlhelp.exe和jd2chm.exe生成chm文档. 具体步骤如下: 打开MyEclipse,选中想要制作 ...
- ABBYY FineReader 15扫描和保存文档详解
通过使用ABBYY FineReader 15 OCR文字识别软件的扫描和保存文档功能,用户可使用扫描仪或数码照相机获得图像文档,然后再转换为各种数字格式文档. 在"新任务窗口"中 ...
随机推荐
- POJ 3180 The cow Prom Tarjan基础题
题目用google翻译实在看不懂 其实题目意思如下 给一个有向图,求点个数大于1的强联通分量个数 #include<cstdio> #include<algorithm> #i ...
- 幸运数字(luckly)
幸运数字(luckly) 题目描述 A国共有 nn 座城市,这些城市由 TeX parse error: Misplaced & 条道路相连,使得任意两座城市可以互达,且路径唯一.每座城市都有 ...
- mongo基本命令
> show dbs -- 查看数据库列表 > use admin --创建admin数据库,如果存在admin数据库则使用admin数据库 > db ---显示当前使 ...
- 02 Java 基础语法
在开始 Java 基本语法之前,先说明 Java 程序的基本规范: 大小写敏感,例如 Person 和 person 是不同的 类名首字母大写,如果类名由多个单词组成,每个单词首字母都大写,例如 He ...
- bzoj 3507 DP+哈希
[Cqoi2014]通配符匹配 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 541 Solved: 235[Submit][Status][Dis ...
- Vitamio介绍及使用
一.Vitamio介绍 1.1 Vitamio是什么? Vitamio是Android平台视音频播放组件,支持播放几乎格式的视频以及主流网络视频流(http/rtsp/mms等),详细的中文介绍: 这 ...
- OPENCV mat类
OpenCV参考手册之Mat类详解 目标 我们有多种方法可以获得从现实世界的数字图像:数码相机.扫描仪.计算机体层摄影或磁共振成像就是其中的几种.在每种情况下我们(人类)看到了什么是图像.但是,转换图 ...
- 【Tomcat】一台电脑上运行多个tomcat
效果: 1.首先需要安装Tomcat7,Tomcat8. Tomcat7: Tomcat8: 2.添加两个环境变量,添加CATALINA_HOME1和CATALINA_BASE1指向E:\tomcat ...
- Centos 6.3软件安装
一.软件安装包的类型: 1. tar包,如software-1.2.3-1.tar.gz.它是使用UNIX系统的打包工具tar打包的. 2. rpm包,如software-1.2.3-1.i386.r ...
- 异步 JavaScript 之理解 macrotask 和 microtask(转)
这个知识点... https://blog.keifergu.me/2017/03/23/difference-between-javascript-macrotask-and-microtask/? ...