Event Recommendation Engine Challenge分步解析第六步
一、请知晓
本文是基于:
Event Recommendation Engine Challenge分步解析第一步
Event Recommendation Engine Challenge分步解析第二步
Event Recommendation Engine Challenge分步解析第三步
Event Recommendation Engine Challenge分步解析第四步
Event Recommendation Engine Challenge分步解析第五步
需要读者先阅读前五篇文章解析
二、特征构建
前五步我们已经将需要的数据进行了结构的存储,这一部分我们将利用前五步的数据
1)生成训练数据
dr = DataRewriter()
print('生成训练数据...\n')
dr.rewriteData(train=True, start=2, header=True)
我们先来解析这个DataRewriter类的rewriteData方法:该方法把前面user-based协同过滤和item-based协同过滤及各种热度和影响度作为特征组合在一起生成新的训练数据,用于分类器使用
def rewriteData(self, start=1, train=True, header=True):
"""
把前面user-based协同过滤和item-based协同过滤以及各种热度和影响度作为特征组合在一起
生成新的train,用于分类器分类使用
"""
fn = 'train.csv' if train else 'test.csv'
fin = open(fn)
fout = open('data_' + fn, 'w')
#write output header
if header:
ocolnames = ['invited', 'user_reco', 'evt_p_reco', 'evt_c_eco', 'user_pop', 'frnd_infl', 'evt_pop']
if train:
ocolnames.append('interested')
ocolnames.append('not_interested')
fout.write( ','.join(ocolnames) + '\n' )
fn:即为train.csv或者test.csv
fout:即为我们要写入保存的文件,data_train.csv或者data_test.csv
ocolnames:即为我们的特征,如果是train.csv的话应该还有标签-interested或not_interested
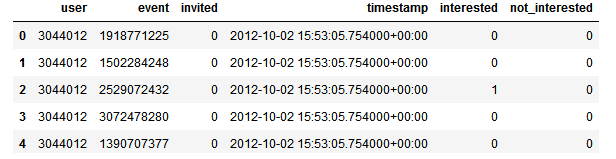
这里以train.csv为例讲解代码,其中train.csv文件如下所示:
def rewriteData(self, start=1, train=True, header=True):
"""
把前面user-based协同过滤和item-based协同过滤以及各种热度和影响度作为特征组合在一起
生成新的train,用于分类器分类使用
"""
fn = 'train.csv' if train else 'test.csv'
fin = open(fn)
fout = open('data_' + fn, 'w')
#write output header
if header:
ocolnames = ['invited', 'user_reco', 'evt_p_reco', 'evt_c_eco', 'user_pop', 'frnd_infl', 'evt_pop']
if train:
ocolnames.append('interested')
ocolnames.append('not_interested')
fout.write( ','.join(ocolnames) + '\n' ) ln = 0
for line in fin:
ln += 1
if ln < start:
continue
cols = line.strip().split(',')
#user,event,invited,timestamp,interested,not_interested
userId = cols[0]
eventId = cols[1]
invited = cols[2]
if ln % 500 == 0:
print("%s : %d (userId, eventId) = (%s, %s)" % (fn, ln, userId, eventId))
a)逐行读取train.csv或者test.csv,逗号分隔后获取userId,eventId,和invited,即前三列信息,然后调用self.userReco( userId, eventId)方法计算user_reco:
#这是特征构建部分 #import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle
import scipy.io as sip class DataRewriter:
def __init__(self):
#读入数据做初始化
self.userIndex = cPickle.load( open('PE_userIndex.pkl','rb') )
self.eventIndex = cPickle.load( open('PE_eventIndex.pkl', 'rb') )
self.userEventScores = sio.mmread('PE_userEventScores').todense()
self.userSimMatrix = sio.mmread('US_userSimMatrix').todense()
self.eventPropSim = sio.mmread('EV_eventPropSim').todense()
self.eventContSim = sio.mmread('EV_eventContSim').todense()
self.numFriends = sio.mmread('UF_numFriends')
self.userFriends = sio.mmread('UF_userFriends').todense()
self.eventPopularity = sio.mmread('EA_eventPopularity').todense() def userReco(self, userId, eventId):
"""
根据User-based协同过滤,得到event的推荐度
基本的伪代码思路如下:
for item in i
for every other user v that has a preference for i
compute similarity s between u and v
incorporate v's preference for i weighted by s into running average
return top items ranked by weighted average """
i = self.userIndex[userId]
j = self.eventIndex[eventId]
vs = self.userEventScores[:, j]
sims = self.userSimMatrix[i, :]
prod = sims * vs
try:
return prod[0, 0] - self.userEventScores[i, j]
except IndexError:
return 0
如在处理train.csv的第一行时,userId = 3044012, eventId = 1918771225
#import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle
userIndex = cPickle.load( open('PE_userIndex.pkl','rb') )
eventIndex = cPickle.load( open('PE_eventIndex.pkl', 'rb') )
userEventScores = sio.mmread('PE_userEventScores').todense()
userSimMatrix = sio.mmread('US_userSimMatrix').todense() userId = '3044012'
eventId = '1918771225'
i = userIndex[userId]
j = eventIndex[eventId] print('The first line in train.csv: userIndex of (userId = %s) is (i = %d) ' %(userId, i) )
print('The first line in train.csv: eventIndex of (eventId = %s) is (j = %d) ' %(eventId, j) ) vs = userEventScores[:, j]#获得所有user对event j兴趣分,即userEventScores的第j+1列
sims = userSimMatrix[i, :]#获得userSimMatrix的第i+1行,即每个user对该user的相似度
prod = sims * vs
try:
print(prod[0, 0] - userEventScores[i, j])
except IndexError:
print(0)
代码示例结果:
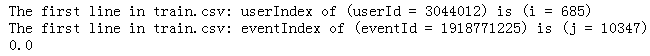
这样我们得到该user的user_reco值
b)evt_p_reco和evt_c_reco的计算
过程和上面的userReco()类似,读者可以参考eventPropSim和eventContSim的结构信息
def eventReco(self, userId, eventId):
"""
根据基于物品的协同过滤,得到Event的推荐度
基本的伪代码思路:
for item i:
for every item j that u has a preference for
compute similarity s between i and j
add u's preference for j weighted by s to a running average
return top items, ranked by weighted average
"""
i = self.userIndex[userId]
j = self.eventIndex[eventId]
js = self.userEventScores[i, :]#user i对每个event的兴趣分
psim = self.eventPropSim[:, j]
csim = self.eventContSim[:, j]
pprod = js * psim
cprod = js * csim
pscore = 0
cscore = 0
try:
pscore = pprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass try:
cscore = cprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass return pscore, cscore
c)user_pop计算:调用self.userPop()方法
这里需要用户的朋友数(已经用占比表示):
def userPop(self, userId):
"""
基于用户的朋友个数来推断用户的社交程度
主要的考量是如果用户的朋友非常多,可能会更倾向于参加各种社交活动
""" if userId in self.userIndex:
i = self.userIndex[userId]
try:
return self.numFriends[0, i]
except IndexError:
return 0
else:
return 0
d)frnd_infl计算:调用self.friendInfluence()方法,朋友对该用户的影响,即用户的所有朋友中,有多少是非常喜欢参加各种社交活动(event)的
这里需要变量self.userFriends
def friendInfluence(self, userId):
"""
朋友对用户的影响
主要考虑用户的所有朋友中,有多少是非常喜欢参加各种社交活动(event)的
用户的朋友圈如果都是积极参加各种event,可能会对当前用户有一定的影响
"""
nusers = np.shape(self.userFriends)[1]
i = self.userIndex[userId]
#下面的一行代码是不是有问题呢?
#是不是应该为某个用户的所有朋友的兴趣分之和,然后除以nusers,也就是axis应该=1
return (self.userFriends[i, :].sum(axis=0) / nusers)[0, 0]
e)evt_pop的计算:调用self.eventPop()方法,某个event的热度,主要通过参与的人数来界定的
需要用到变量self.eventPopularity
def eventPop(self, eventId):
"""
活动本身的热度
主要通过参与的参数来界定的
"""
i = self.eventIndex[eventId]
return self.eventPopularity[i, 0]
f)然后就是将该行的信息写入文件保存
文件信息包含:[invited, user_reco, evt_p_reco, evt_c_reco, user_pop, frnd_infl, evt_pop],如果读取的是train.csv,则还需要append 标签interested和not_interested
#读取一行,处理后,将该行写入,保存
fout.write(','.join( map(lambda x: str(x), ocols)) + '\n')
g)构建特征完整代码
#这是特征构建部分 #import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle
import scipy.io as sio
import numpy as np class DataRewriter:
def __init__(self):
#读入数据做初始化
self.userIndex = cPickle.load( open('PE_userIndex.pkl','rb') )
self.eventIndex = cPickle.load( open('PE_eventIndex.pkl', 'rb') )
self.userEventScores = sio.mmread('PE_userEventScores').todense()
self.userSimMatrix = sio.mmread('US_userSimMatrix').todense()
self.eventPropSim = sio.mmread('EV_eventPropSim').todense()
self.eventContSim = sio.mmread('EV_eventContSim').todense()
self.numFriends = sio.mmread('UF_numFriends')
self.userFriends = sio.mmread('UF_userFriends').todense()
self.eventPopularity = sio.mmread('EA_eventPopularity').todense() def userReco(self, userId, eventId):
"""
根据User-based协同过滤,得到event的推荐度
基本的伪代码思路如下:
for item in i
for every other user v that has a preference for i
compute similarity s between u and v
incorporate v's preference for i weighted by s into running average
return top items ranked by weighted average """
i = self.userIndex[userId]
j = self.eventIndex[eventId]
vs = self.userEventScores[:, j]
sims = self.userSimMatrix[i, :]
prod = sims * vs
try:
return prod[0, 0] - self.userEventScores[i, j]
except IndexError:
return 0 def eventReco(self, userId, eventId):
"""
根据基于物品的协同过滤,得到Event的推荐度
基本的伪代码思路:
for item i:
for every item j that u has a preference for
compute similarity s between i and j
add u's preference for j weighted by s to a running average
return top items, ranked by weighted average
"""
i = self.userIndex[userId]
j = self.eventIndex[eventId]
js = self.userEventScores[i, :]
psim = self.eventPropSim[:, j]
csim = self.eventContSim[:, j]
pprod = js * psim
cprod = js * csim
pscore = 0
cscore = 0
try:
pscore = pprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass try:
cscore = cprod[0, 0] - self.userEventScores[i, j]
except IndexError:
pass return pscore, cscore def userPop(self, userId):
"""
基于用户的朋友个数来推断用户的社交程度
主要的考量是如果用户的朋友非常多,可能会更倾向于参加各种社交活动
""" if userId in self.userIndex:
i = self.userIndex[userId]
try:
return self.numFriends[0, i]
except IndexError:
return 0
else:
return 0 def friendInfluence(self, userId):
"""
朋友对用户的影响
主要考虑用户的所有朋友中,有多少是非常喜欢参加各种社交活动(event)的
用户的朋友圈如果都是积极参加各种event,可能会对当前用户有一定的影响
"""
nusers = np.shape(self.userFriends)[1]
i = self.userIndex[userId]
#下面的一行代码是不是有问题呢?
#是不是应该为某个用户的所有朋友的兴趣分之和,然后除以nusers,也就是axis应该=1
return (self.userFriends[i, :].sum(axis=0) / nusers)[0, 0] def eventPop(self, eventId):
"""
活动本身的热度
主要通过参与的参数来界定的
"""
i = self.eventIndex[eventId]
return self.eventPopularity[i, 0] def rewriteData(self, start=1, train=True, header=True):
"""
把前面user-based协同过滤和item-based协同过滤以及各种热度和影响度作为特征组合在一起
生成新的train,用于分类器分类使用
"""
fn = 'train.csv' if train else 'test.csv'
fin = open(fn)
fout = open('data_' + fn, 'w')
#write output header
if header:
ocolnames = ['invited', 'user_reco', 'evt_p_reco', 'evt_c_reco', 'user_pop', 'frnd_infl', 'evt_pop']
if train:
ocolnames.append('interested')
ocolnames.append('not_interested')
fout.write( ','.join(ocolnames) + '\n' ) ln = 0
for line in fin:
ln += 1
if ln < start:
continue
cols = line.strip().split(',')
#user,event,invited,timestamp,interested,not_interested
userId = cols[0]
eventId = cols[1]
invited = cols[2]
if ln % 500 == 0:
print("%s : %d (userId, eventId) = (%s, %s)" % (fn, ln, userId, eventId)) user_reco = self.userReco( userId, eventId )
evt_p_reco, evt_c_reco = self.eventReco( userId, eventId )
user_pop = self.userPop( userId )
frnd_infl = self.friendInfluence( userId )
evt_pop = self.eventPop( eventId )
ocols = [invited, user_reco, evt_p_reco, evt_c_reco, user_pop, frnd_infl, evt_pop] if train:
ocols.append( cols[4] )#interested
ocols.append( cols[5] )#not_interested fout.write(','.join( map(lambda x: str(x), ocols)) + '\n') fin.close()
fout.close() def rewriteTrainingSet(self):
self.rewriteData(True) def rewriteTestSet(self):
self.rewriteData(False) dr = DataRewriter()
print('生成训练数据...\n')
dr.rewriteData(train=True, start=2, header=True) print('生成预测数据...\n')
dr.rewriteData(train=False, start=2, header=True)
print('done')
2)生成测试数据:过程和生成训练数据类似
至此,第六步完成,哪里有不明白的请留言
在特征构建好了之后,我们有很多办法去训练得到模型和完成预测
我们来看看Event Recommendation Engine Challenge分步解析第七步
Event Recommendation Engine Challenge分步解析第六步的更多相关文章
- Event Recommendation Engine Challenge分步解析第七步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第五步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第四步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第三步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第二步
一.请知晓 本文是基于Event Recommendation Engine Challenge分步解析第一步,需要读者先阅读上篇文章解析 二.用户相似度计算 第二步:计算用户相似度信息 由于用到:u ...
- Event Recommendation Engine Challenge分步解析第一步
一.简介 此项目来自kaggle:https://www.kaggle.com/c/event-recommendation-engine-challenge/ 数据集的下载需要账号,并且需要手机验证 ...
- SpringBoot 源码解析 (六)----- Spring Boot的核心能力 - 内置Servlet容器源码分析(Tomcat)
Spring Boot默认使用Tomcat作为嵌入式的Servlet容器,只要引入了spring-boot-start-web依赖,则默认是用Tomcat作为Servlet容器: <depend ...
- (转) Quick Guide to Build a Recommendation Engine in Python
本文转自:http://www.analyticsvidhya.com/blog/2016/06/quick-guide-build-recommendation-engine-python/ Int ...
- 卷积神经网络 cnnff.m程序 中的前向传播算法 数据 分步解析
最近在学习卷积神经网络,哎,真的是一头雾水!最后决定从阅读CNN程序下手! 程序来源于GitHub的DeepLearnToolbox 由于确实缺乏理论基础,所以,先从程序的数据流入手,虽然对高手来讲, ...
随机推荐
- 洛谷 P2151 [SDOI2009]HH去散步
题目链接 思路 如果没有不能走上一条边的限制,很显然就是dp. 设f[i][j]表示到达i点走了j步的方案数,移到k点可以表示为f[k][j+1]+=f[i][j]. 如果有限制的话,可以考虑用边表示 ...
- Qt5 入门
main()函数中第一句是创建一个QApplication类的实例. 对于 Qt 程序来说,main()函数一般以创建 application 对象(GUI 程序是QApplication,非 GUI ...
- Yahoo Programming Contest 2019 自闭记
A:签到. #include<iostream> #include<cstdio> #include<cmath> #include<cstdlib> ...
- HDU3480-Division-斜率dp
首先想到的就是sort一下,然后每个集合都在排过序的数组里面取,不重复. 这样就推出公式dp[i][j] = min(dp[k][j-1] + (s[i]-s[k+1])^2) 其中dp[i][j]为 ...
- LOJ2269 [SDOI2017] 切树游戏 【FWT】【动态DP】【树链剖分】【线段树】
题目分析: 好题.本来是一道好的非套路题,但是不凑巧的是当年有一位国家集训队员正好介绍了这个算法. 首先考虑静态的情况.这个的DP方程非常容易写出来. 接着可以注意到对于异或结果的计数可以看成一个FW ...
- python的小练习
# -*- coding: utf-8 -*- """练习:有1,2,3,4. 4个数能组成多少个互不相同且无重复数字的三位数,分别是多少?""&qu ...
- 慢腾腾的Quartus prime16.0加快编译速度
前言 当一个工程反复修改的时候,可能有时候源代码没有更改,为了加快编译速度可以配置quartus一些选项.当然,初次编译的速度是否会提升,未验证.更高级的设计分区以及逻辑锁区提升速度,以后阐述. 流程 ...
- bzoj 2131 : 免费的馅饼 (树状数组优化dp)
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=2131 思路: 题目给出了每个馅饼的下落时间t,和位置p,以及价值v,我们可以得到如下状态 ...
- anaconda4.2.0
上改完cv2那个文件夹后,发现在使用导入的cv2中的方法时没有代码提示,于是搞啊搞,终于让我搞坏了mmp,这也太脆弱了. 无奈组装了一个全新的方法 过程比较坎坷也就没怎么记录 我的版本是选择最后一个o ...
- Nginx 添加 PHP 支持
背景介绍默认安装的Nginx是无法打开php文件的,需要修改相关配置才能支持php 安装yum -y install epel-release yum -y install nginx yum ins ...