斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性。那就是设定某个实数来评估学习算法并衡量它的表现。有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成非常微妙的影响。这类问题就是偏斜类(skewed classes)的问题。什么意思呢。以癌症分类为例,我们拥有内科病人的特征变量,并希望知道他们是否患有癌症,这就像恶性与良性肿瘤的分类问题。假设y=1表示患者患有癌症,假设y=0表示没有得癌症,然后训练逻辑回归模型。假设用测试集检验了这个分类模型,并且发现它只有1%的错误。因此我们99%会做出正确诊断,看起来是非常不错的结果。99%的情况都是正确的。但是,假如我们发现在测试集中,只有0.5%的患者真正得了癌症,在我们的筛选程序里只有0.5%的患者患了癌症。在这个例子中,1%的错误率就不再显得那么好了。

举个具体的例子,这里有一行代码,它忽略了输入值X,让y总是等于0,因此它总是预测没有人得癌症。那么这个算法实际上只有0.5%的错误率。因此这甚至比我们之前得到的1%的错误率更好,这是一个非机器学习算法,因为它只是预测y总是等于0。

这种情况发生在正例和负例的比率非常接近于一个极端,在这个例子中,正样本的数量与负样本的数量相比,非常非常少。因为y=1非常少,我们把这种情况叫做偏斜类。一个类中的样本与另一个类的数据相比多很多,通过总是预测y=0,或者总是预测y=1,算法可能表现非常好。因此使用分类误差或者分类精确度来作为评估度量可能会产生如下问题。假如说有一个算法,它的精确度是99.2%,因此它只有0.8%的误差。假设你对你的算法做出了一点改动,得到了99.5%的精确度,只有0.5%的误差。这到底是不是算法的一个提升呢,用某个实数来作为评估度量值的一个好处就是,它可以帮助我们迅速决定是否需要对算法做出一些改进。将精确度从99.2%提高到99.5%,但是我们的改进到底是有用的,还是说我们只是把代码替换成了例如总是预测y=0这样的东西,因此如果你有一个偏斜类,用分类精确度并不能很好地衡量算法,因为你可能会获得一个很高的精确度,或者非常低的错误率,但是我们并不知道我们是否真的提升了分类模型的质量,因为总是预测y=0,并不是一个好的分类模型。但是总是预测y=0,会将你的误差降低至,比如降低至0.5%。当我们遇到这样一个偏斜类时,我们希望有一个不同的误差度量值或者不同的评估度量值。其中一种评估度量值叫做查准率(precision)和召回率(recall)。
假设我们正在用测试集来评估一个分类模型,对于测试集中的样本,每个测试集中的样本都会等于0或者1,假设这是一个二分问题。我们的学习算法要做的是做出值的预测,并且学习算法会为每一个测试集中的实例做出预测。预测值也是等于0或1。下面为基于实际的类与预测的类的2x2表格。如果有一个样本它实际所属的类是1,预测的类也是1,那么我们把这个样本叫做真阳性(true positive),意思是说我们的学习算法预测这个值为阳性,实际上这个样本也确实是阳性。如果我们的学习算法预测某个值是阴性,等于0,实际的类也确实属于0。那么我们把这个叫做真阴性(true negative)。我们预测为0的值实际上也等于0。另外的两个单元格,如果我们的学习算法预测某个值等于1,但是实际上它等于0,这个叫做假阳性(false positive)。比如我们的算法预测某些病人患有癌症,但是事实上他们并没有得癌症。最后,这个单元格是1和0,这个叫做假阴性(false negative),因为我们的算法预测值为0,但是实际值是1。这样我们有了一个一种基于实际类与预测类的2x2表格的方式来评估算法的表现。

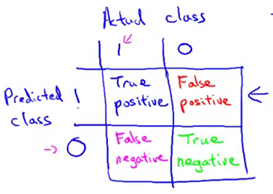
前面提到评估偏斜类度量值的两个方法。第一个叫做查准率,意思是对于所有我们预测患有癌症的病人,有多大比率的病人是真正患有癌症的。即一个分类模型的查准率等于真阳性除以所有我们预测为阳性的数量。对于那些病人,我们告诉他们“你们患有癌症”。对于这些病人而言,有多大比率是真正患有癌症的,这个就叫做查准率,另一个写法是分子是真阳性,分母是所有预测阳性的数量,即等于表格第一行的值的和。这个就叫做查准率。查准率越高就越好。高查准率说明对于这类病人,我们对预测他们得了癌症有很高的准确率。

另一个我们要计算的叫做召回率。召回率是所有测试集中的病人或者交叉验证集中的病人确实得了癌症,有多大比率我们正确预测他们得了癌症。召回率被定义为真阳性的数量除以实际阳性数量。将这个以不同的形式写下来,那就是真阳性除以真阳性加上假阴性。同样地,召回率越高越好。

通过计算查准率和召回率,我们能更好的知道,分类模型到底好不好。具体地说,如果我们有一个算法,总是预测y=0,即预测没有人患癌症,那么这个分类模型召回率等于0,因为它不会有真阳性。因此我们能会快发现这个分类模型总是预测y=0。不是一个好的模型。总的来说,即使我们有一个非常偏斜的类,算法也不能够“欺骗”我们。仅仅通过预测y总是等于0或者y总是等于1。它没有办法得到高的查准率和高的召回率。因此我们能够更肯定拥有高查准率或者高召回率的模型,是一个好的分类模型,这给予了我们一个更好的评估值,给予我们一种更直接的方法来评估模型的好与坏。最后一件需要记住的事,在查准率和召回率的定义中,我们定义查准率和召回率,我们习惯性地用y=1,表示这个类出现得非常少。因此如果我们试图检测某种很稀少的情况,比如癌症。我希望它是个很稀少的情况,查准率和召回率会被定义为y=1而不是y=0,作为某种我们希望检测的出现较少的类。总的来说,即便我们拥有很偏斜的类,只要查准率和召回率非常得高,也可以说明学习算法表现的很好。
斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 评估指标:准确率(Precision)、召回率(Recall)以及F值(F-Measure)
为了能够更好的评价IR系统的性能,IR有一套完整的评价体系,通过评价体系可以了解不同信息系统的优劣,不同检索模型的特点,不同因素对信息检索的影响,从而对信息检索进一步优化. 由于IR的目标是在较短时间 ...
- 斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)
一般来说,召回率和查准率的关系如下:1.如果需要很高的置信度的话,查准率会很高,相应的召回率很低:2.如果需要避免假阴性的话,召回率会很高,查准率会很低.下图右边显示的是召回率和查准率在一个学习算法中 ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习: advice for applying machine learning - evaluatin a phpothesis(怎么评估学习算法得到的假设以及如何防止过拟合或欠拟合)
怎样评价我们的学习算法得到的假设以及如何防止过拟合和欠拟合的问题. 当我们确定学习算法的参数时,我们考虑的是选择参数来使训练误差最小化.有人认为,得到一个很小的训练误差一定是一件好事.但其实,仅仅是因 ...
随机推荐
- 莫烦theano学习自修第十天【保存神经网络及加载神经网络】
1. 为何保存神经网络 保存神经网络指的是保存神经网络的权重W及偏置b,权重W,和偏置b本身是一个列表,将这两个列表的值写到列表或者字典的数据结构中,使用pickle的数据结构将列表或者字典写入到文件 ...
- h.264并行熵解码
在前面讨论并行解码的章节中,我们专注于讨论解码的宏块重建部分,甚至把宏块重建描述成宏块解码,这是因为在解码工作中,宏块重建确实占了相当大的比重,不过解码还包含其它的部分,按照解码流程可粗略分为: 读取 ...
- 如何在Ubuntu 18.04上安装Django
Django是一个免费的开源高级Python Web框架,旨在帮助开发人员构建安全,可扩展和可维护的Web应用程序. 根据您的需要,有不同的方法来安装Django.它可以使用pip在系统范围内安装或在 ...
- ab与nc命令,tcpdump命令
ab与nc命令,tcpdump命令 ab -p post.txt -T application/json "http://127.0.0.1:8083/main/index&quo ...
- Android学习第6天
创建一个新的activity 四大组件需要在清单文件中配置 可在清单文件中配置多个启动图标过单个启动图标 Activity下的lable和icon属性可以和Application节点的属性不一样,默认 ...
- 解决Altera家的ROM仿真数据一直为0
BUG现象 各种配置都正确,但ROM就是不出数据,输出一直为零. 解决方式 对于rom的仿真,要更改生成的rom文件的一个地方,主要是由于相对路径与绝对路径的问题. 所以最简单的解决方法是把mif文件 ...
- BSGS&扩展BSGS
BSGS 给定\(a,b,p\),求\(x\)使得\(a^x\equiv b \pmod p\),或者说明不存在\(x\) 只能求\(\gcd(a,p)=1\)的情况 有一个结论:如果有解则必然存在\ ...
- 解决nginx发布网站跨目录访问
解决nginx发布网站跨目录访问(thinkphp5+lnmp) 到:usr/local/nginx/conf/vim fastcgi.cof 把最后一行加上井号#注释掉保存重启 restart 参考 ...
- Centos install Python3
下载Python3wget http://python.org/ftp/python/3.4.1/Python-3.4.1.tar.xz 安装yum install openssl-devel bzi ...
- 树莓派(Raspberry Pi)使用Shell编写的极简Service
树莓派(Raspberry Pi)运行的系统是基于Debian的,不仅可以运行Shell,还支持systemd和docker,可以编写一个简单的服务,让其在启动时运行,执行一些自动化的操作.这里在Ra ...