机器学习入门-集成算法(bagging, boosting, stacking)
目的:为了让训练效果更好
bagging:是一种并行的算法,训练多个分类器,取最终结果的平均值 f(x) = 1/M∑fm(x)
boosting: 是一种串行的算法,根据前一次的结果,进行加权来提高训练效果
stacking; 是一种堆叠算法,第一步使用多个算法求出结果,再将结果作为特征输入到下一个算法中训练出最终的预测结果
1.Bagging:全程boostap aggregation(说白了是并行训练一堆分类器)
最典型的算法就是随机森林
随机森林的意思就是特征随机抽取,即每一棵数使用60%的随机特征,数据随机抽取,即每一棵树使用的数据是60%-80%,这样做的目的是为了保证每一棵树的结果在输出是都存在差异。最后对输出的结果求平均
随机森林的优势
它能处理很高维度的数据,不需要进行特征选择
在训练后他能给出哪些特征的重要性,根据重要性我们也可以进行特征选择
特征重要性的计算方法:如果有特征是A,B,C,D 根据这4个特征求得当前的error,然后对B特征采用随机给定记为B*,对A,B*,C,D求error1,
如果error == error1 ,说明B特征不重要
如果error < error1 说明B特征的重要性很大
当随机森林树的个数超过一定数量后,就会上下浮动
2.Boosting: 是一种串行的算法,通过弱学习器开始加强,通过加权来训练
Fm(x) = Fm-1(x) + argmin(∑L(yi, Fm-1(x) + h(xi) )) 通过前一次的输出结果与目标的残差值,来训练下一颗树的结果(XGboost)
这里介绍一种Adaboost(双加权)
Adaboost 每一次使用一棵树,根据前一颗树的输出结果,来对数据进行加权,比如有5个数据,刚开始的权重都为0.2, 其中第3个数据被判错了,那么第3个数据的权重就为0.6,将经过加权后的数据输入到下一颗树中,再进行训练
根据每一棵树的准确率,再进行权重加权,获得最终的输出结果
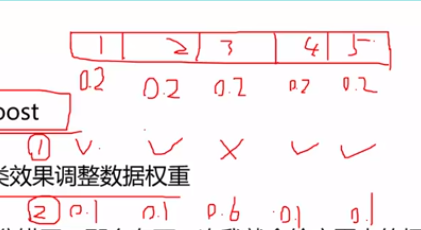
对于数据的权重加和
3.Stacking : 聚合多个分类或回归模型
堆叠,拿来一堆直接上
可以堆叠各种各样的分类器(KNN, SVM, RF)
分阶段进行,第一个阶段可以使用多个分类器获得分类结果,第二阶段将分类结果作为特征输入到一个分类器中,得到最终的结果,缺点就是耗时
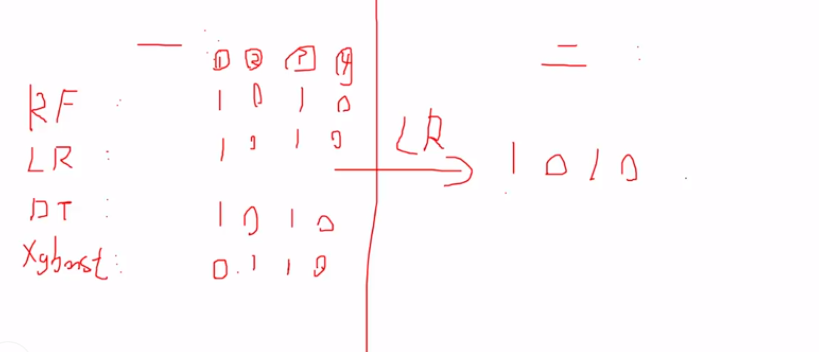
第一阶段 第二阶段
RF ----- 0 1 0 1 --作为特征--输出结果
LR ------ 1 0 1 0 -----LR-------1 0 1 0
DT -------1 1 0 1 训练模型
xgboost---- 1 1 0 1
机器学习入门-集成算法(bagging, boosting, stacking)的更多相关文章
- 机器学习 - 算法 - 集成算法 - 分类 ( Bagging , Boosting , Stacking) 原理概述
Ensemble learning - 集成算法 ▒ 目的 让机器学习的效果更好, 量变引起质变 继承算法是竞赛与论文的神器, 注重结果的时候较为适用 集成算法 - 分类 ▒ Bagging - bo ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 决策树--------------------------------------------- ...
- 机器学习基础—集成学习Bagging 和 Boosting
集成学习 就是不断的通过数据子集形成新的规则,然后将这些规则合并.bagging和boosting都属于集成学习.集成学习的核心思想是通过训练形成多个分类器,然后将这些分类器进行组合. 所以归结为(1 ...
- 机器学习入门-K-means算法
无监督问题,我们手里没有标签 聚类:相似的东西聚在一起 难点:如何进行调参 K-means算法 需要制定k值,用来获得到底有几个簇,即几种类型 质心:均值,即向量各维取平均值 距离的度量: 欧式距离和 ...
- 机器学习入门-Knn算法
knn算法不需要进行训练, 耗时,适用于多标签分类情况 1. 将输入的单个测试数据与每一个训练数据依据特征做一个欧式距离. 2. 将求得的欧式距离进行降序排序,取前n_个 3. 计算这前n_个的y值的 ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- 一小部分机器学习算法小结: 优化算法、逻辑回归、支持向量机、决策树、集成算法、Word2Vec等
优化算法 先导知识:泰勒公式 \[ f(x)=\sum_{n=0}^{\infty}\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \] 一阶泰勒展开: \[ f(x)\approx ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
随机推荐
- google play apk 下载
https://apps.evozi.com/apk-downloader/?id=com.sgiggle.production
- Apache+modjk布置tomcat集群
一.版本: Apache: 2.2.14: 下载地址:http://archive.apache.org/dist/httpd/binaries/win32/ Mod_jk:tomcat-connec ...
- NPOI控制Excel格式
1.//sheet.SetColumnWidth(3, 50 * 256); 控制第三列宽,单位为1/256个字符 dataRow.Height = 18 * 20; 控制行高,单位为1/20点 s ...
- 使用php在服务器端生成图文验证码(二)
图文验证码的实现原理: 1):准备些许图片将其存储在数据库,每一张图片对应一个标识字段. 2):在服务器端使用数组的形式将图片与标识字段组合起来. 3):随机给客户端返回图片,并接受用户输入的字段. ...
- debian下配置keepalived ha
抄袭自http://blog.51yip.com/server/1417.html,做了一些修改 可以参考http://blog.linuxphp.org/archives/1615/ 备注:NAT模 ...
- redis和memcached选择,对比分析
memcache和redis是互联网分层架构中,最常用的KV缓存.不少同学在选型的时候会纠结,到底是选择memcache还是redis? memcache提供的功能是redis提供的功能的子集,不用想 ...
- 【Spring学习笔记-MVC-13.2】Spring MVC之多文件上传
作者:ssslinppp 1. 摘要 前篇文章讲解了单文件上传<[Spring学习笔记-MVC-13]Spring MVC之文件上传>http://www.cnblogs.co ...
- bzoj1864 三色二叉树
Description Input 仅有一行,不超过500000个字符,表示一个二叉树序列. Output 输出文件也只有一行,包含两个数,依次表示最多和最少有多少个点能够被染成绿色. 记录每个节点染 ...
- LNMP中常见的502错误及处理方法
LNMP配置完成以后,经常遇到502 Bad Gateway的错误提示,究其原因多为2种.下面对这两方面的问题进行分析: 1. 配置方面的错误 配置错误中,或者因为php-fpm找不到路径,或者是权限 ...
- MySQL 报错记录
#--------------------------------------------------------------------------------------------------- ...