深度学习面试题03:改进版梯度下降法Adagrad、RMSprop、Momentum、Adam
目录
Adagrad法
RMSprop法
Momentum法
Adam法
参考资料
发展历史

标准梯度下降法的缺陷
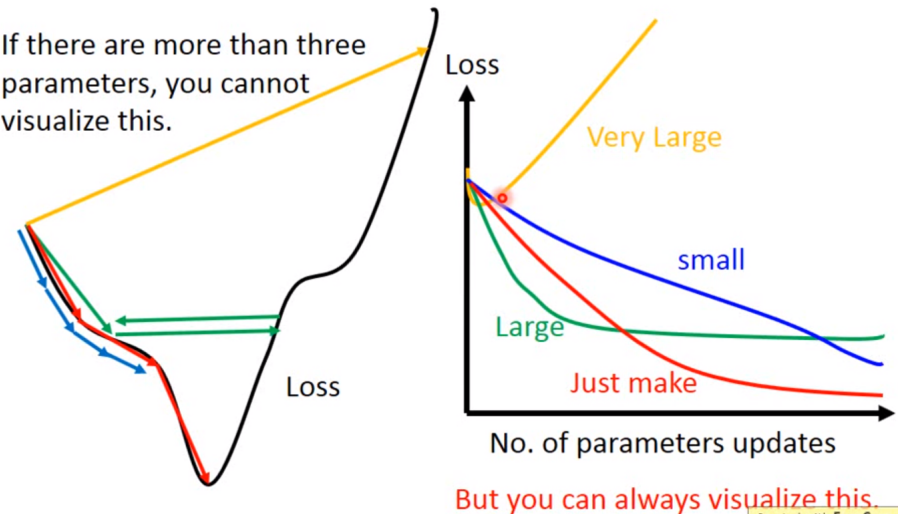
如果学习率选的不恰当会出现以上情况
因此有一些自动调学习率的方法。一般来说,随着迭代次数的增加,学习率应该越来越小,因为迭代次数增加后,得到的解应该比较靠近最优解,所以要缩小步长η,那么有什么公式吗?比如: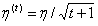 ,但是这样做后,所有参数更新时仍都采用同一个学习率,即学习率不能适应所有的参数更新。
,但是这样做后,所有参数更新时仍都采用同一个学习率,即学习率不能适应所有的参数更新。
解决方案是:给不同的参数不同的学习率
|
Adagrad法 |
假设N元函数f(x),针对一个自变量研究Adagrad梯度下降的迭代过程,
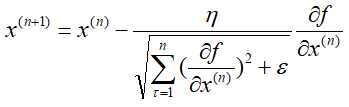
可以看出,Adagrad算法中有自适应调整梯度的意味(adaptive gradient),学习率需要除以一个东西,这个东西就是前n次迭代过程中偏导数的平方和再加一个常量最后开根号。
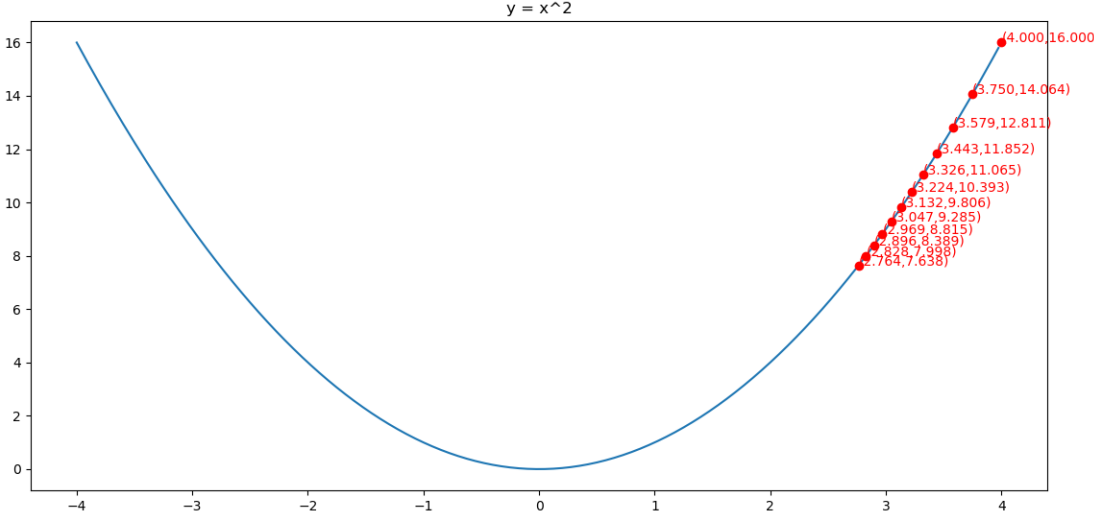
举例:使用Adagrad算法求y = x2的最小值点
导函数为g(x) = 2x
初始化x(0) = 4,学习率η=0.25,ε=0.1
第①次迭代:
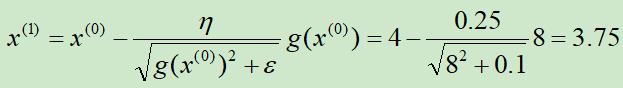
第②次迭代:
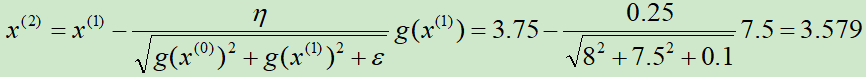
第③次迭代:
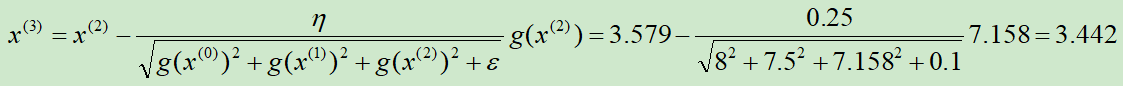
求解的过程如下图所示
对应代码为:
缺点:由于分母是累加梯度的平方,到后面累加的比较大时,会导致梯度更新缓慢
|
RMSprop法 |
AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。为了解决这一问题,RMSprop算法对Adagrad算法做了一点小小的修改,RMSprop使用指数衰减只保留过去给定窗口大小的梯度,使其能够在找到凸碗状结构后快速收敛。
假设N元函数f(x),针对一个自变量研究RMSprop梯度下降的迭代过程,

可以看出分母不再是一味的增加,它会重点考虑距离他较近的梯度(指数衰减的效果),也就不会出现Adagrad到后期收敛缓慢的问题
举例:使用RMSprop算法求y = x2的最小值点
导函数为h(x) = 2x
初始化g(0) = 1,x(0) = 4,ρ=0.9,η=0.01,ε=10-10
第①次迭代:
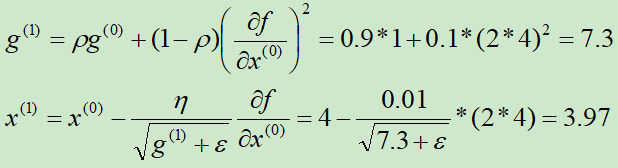
第②次迭代:
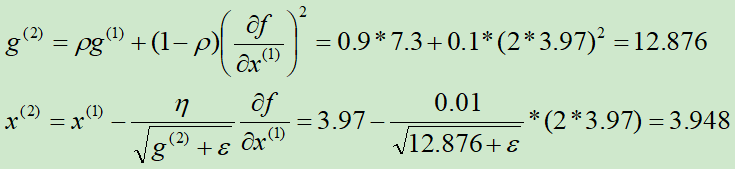
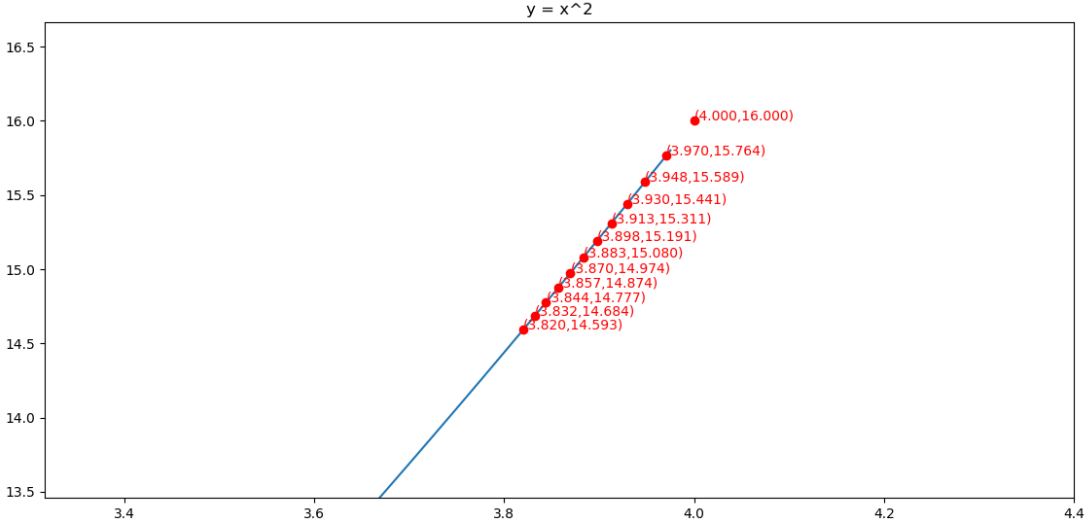
求解的过程如下图所示
对应代码为:
|
Momentum法 |
Momentum是动量的意思,想象一下,一个小车从高坡上冲下来,他不会停在最低点,因为他还有一个动量,还会向前冲,甚至可以冲过一些小的山丘,如果面对的是较大的坡,他可能爬不上去,最终又会倒车回来,折叠几次,停在谷底。

如果使用的是没有动量的梯度下降法,则可能会停到第一个次优解
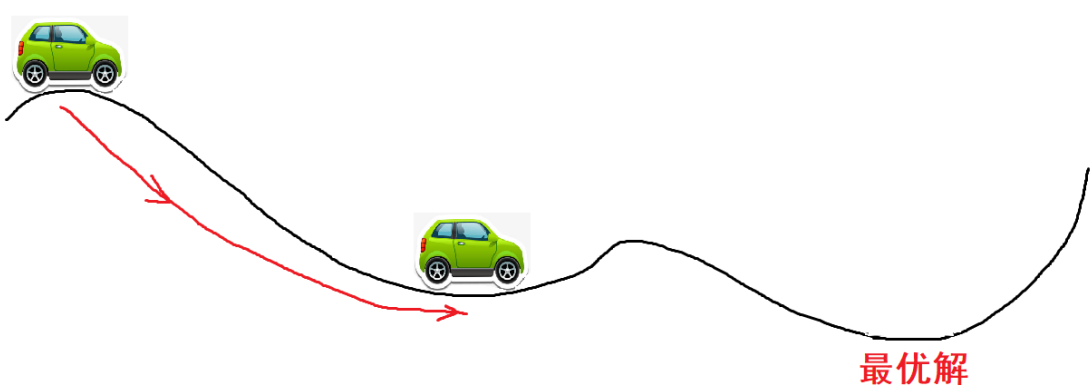
最直观的理解就是,若当前的梯度方向与累积的历史梯度方向一致,则当前的梯度会被加强,从而这一步下降的幅度更大。若当前的梯度方向与累积的梯度方向不一致,则会减弱当前下降的梯度幅度。
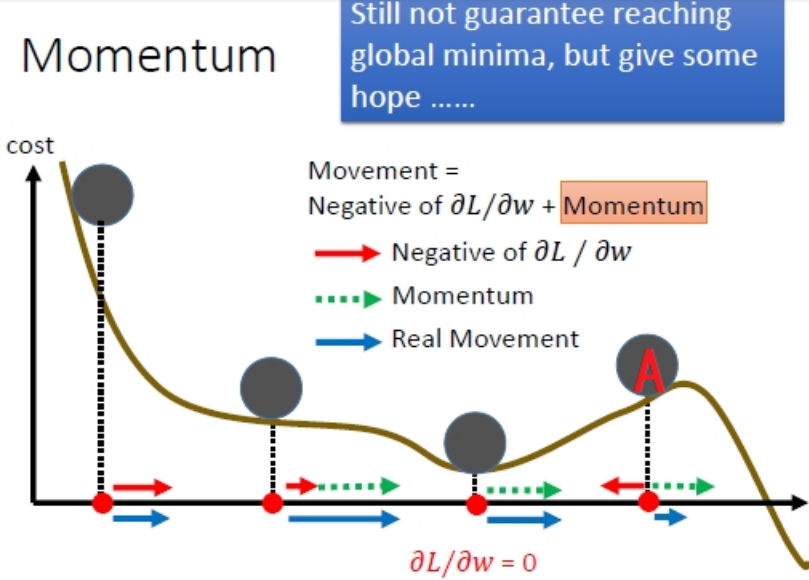
从这幅图可以看出来,当小球到达A点处,负梯度方向的红箭头朝着x轴负向,但是动量方向(绿箭头)朝着x轴的正向并且长度大于红箭头,因此小球在A处还会朝着x轴正向移动。
下面正式介绍Momentum法
假设N元函数f(x),针对一个自变量研究Momentum梯度下降的迭代过程,
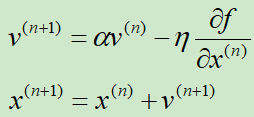
v表示动量,初始v=0
α是一个接近于1的数,一般设置为0.9,也就是把之前的动量缩减到0.9倍
η是学习率
下面通过一个例子演示一下,求y = 2*x^4-x^3-x^2的极小值点
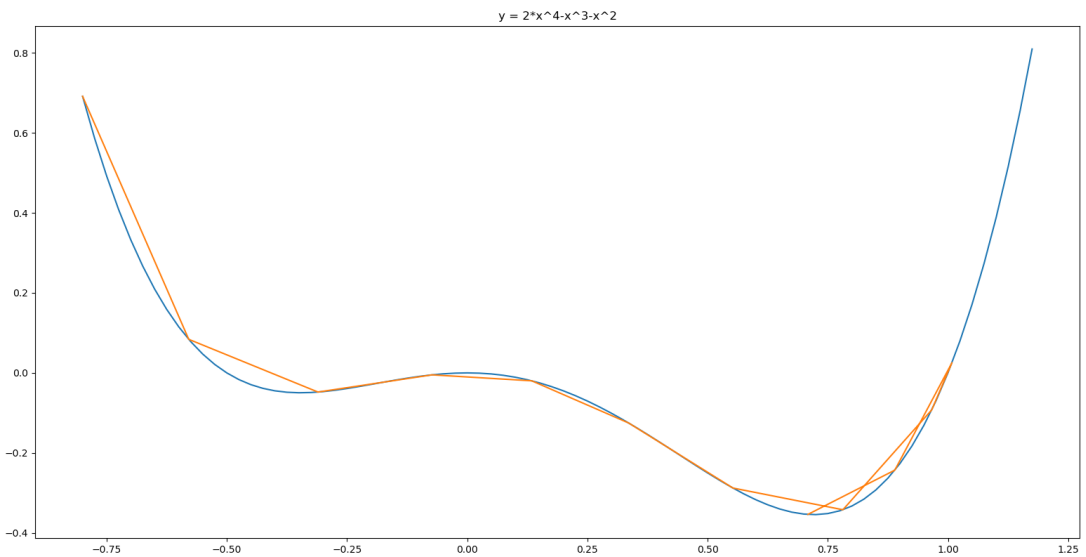
可以看出从-0.8开始迭代,依靠动量成功越过第一个次优解,发现无法越过最优解,折叠回来,最终收敛到最优解。对应代码如下
|
Adam法 |
Adam实际上是把momentum和RMSprop结合起来的一种算法
假设N元函数f(x),针对一个自变量研究Adam梯度下降的迭代过程,
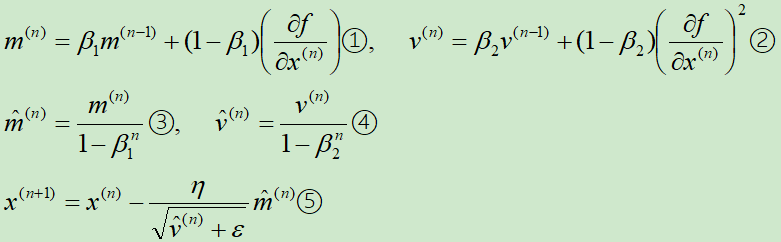
下面依次解释这五个式子:
在①式中,注意m(n)是反向的动量与梯度的和(而在Momentum中是正向动量与负梯度的和,因此⑤式对应的是减号)
在②式中,借鉴的是RMSprop的指数衰减
③和④式目的是纠正偏差
⑤式进行梯度更新
举例:使用Adagrad算法求y = x2的最小值点
导函数为h(x) = 2x
初始化x(0) = 4,m(0) = 0,v(0) = 0,β1=0.9,β2=0.999,ε=10-8,η = 0.001
第①次迭代:
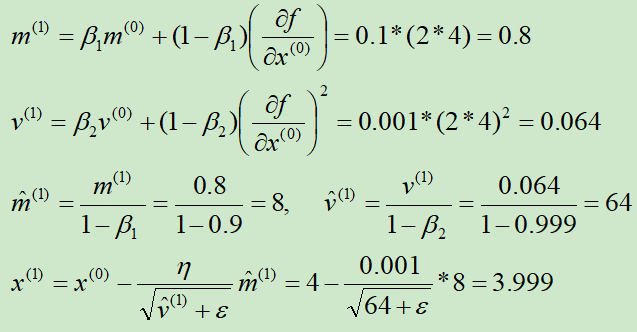
第②次迭代:
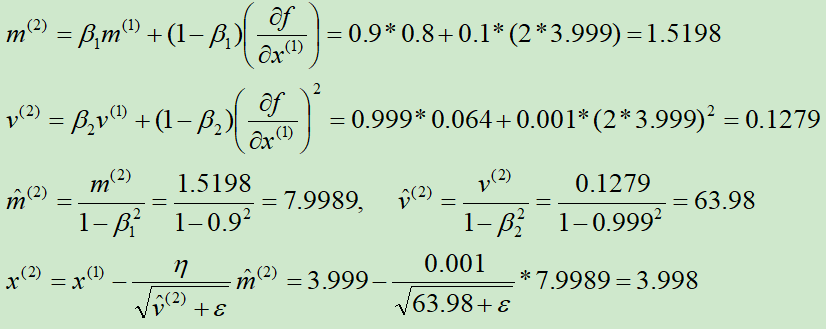
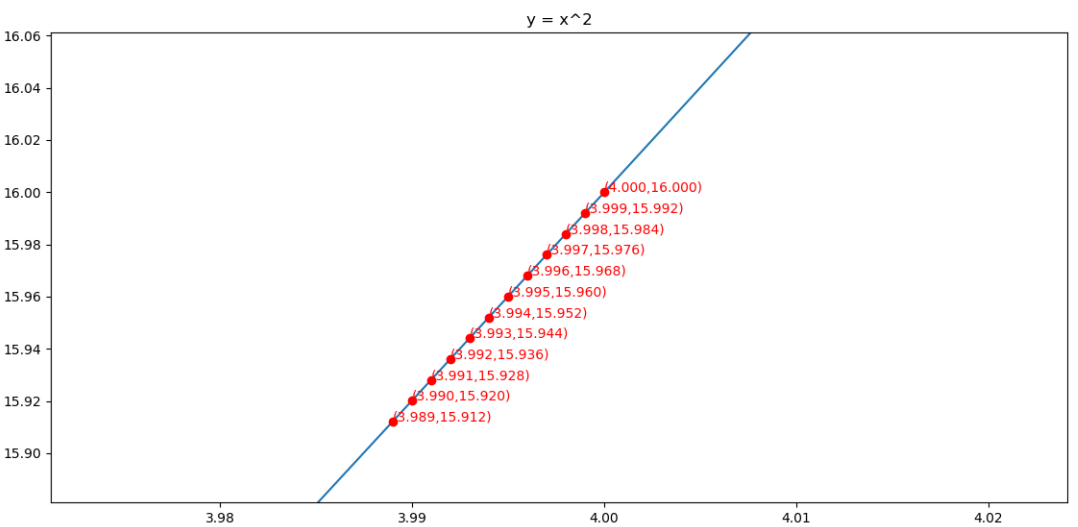
求解的过程如下图所示
对应代码为:
|
参考资料 |
李宏毅——一天搞懂深度学习
深度学习中优化方法——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam
https://blog.csdn.net/u012328159/article/details/80311892
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
深度学习面试题03:改进版梯度下降法Adagrad、RMSprop、Momentum、Adam的更多相关文章
- ubuntu之路——day8.1 深度学习优化算法之mini-batch梯度下降法
所谓Mini-batch梯度下降法就是划分训练集和测试集为等分的数个子集,比如原来有500W个样本,将其划分为5000个baby batch,每个子集中有1000个样本,然后每次对一个mini-bat ...
- 深度学习面试题29:GoogLeNet(Inception V3)
目录 使用非对称卷积分解大filters 重新设计pooling层 辅助构造器 使用标签平滑 参考资料 在<深度学习面试题20:GoogLeNet(Inception V1)>和<深 ...
- 深度学习面试题27:非对称卷积(Asymmetric Convolutions)
目录 产生背景 举例 参考资料 产生背景 之前在深度学习面试题16:小卷积核级联卷积VS大卷积核卷积中介绍过小卷积核的三个优势: ①整合了三个非线性激活层,代替单一非线性激活层,增加了判别能力. ②减 ...
- 深度学习面试题13:AlexNet(1000类图像分类)
目录 网络结构 两大创新点 参考资料 第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet,Alex Krizhevsky其实是Hinton的学生,这个团队领导者是 ...
- [源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积
[源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积 目录 [源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积 0x00 摘要 0x01 概述 1.1 前文回 ...
- 深度学习笔记之【随机梯度下降(SGD)】
随机梯度下降 几乎所有的深度学习算法都用到了一个非常重要的算法:随机梯度下降(stochastic gradient descent,SGD) 随机梯度下降是梯度下降算法的一个扩展 机器学习中一个反复 ...
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- 深度学习面试题20:GoogLeNet(Inception V1)
目录 简介 网络结构 对应代码 网络说明 参考资料 简介 2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名.VGG获得了第二 ...
- 深度学习面试题05:激活函数sigmod、tanh、ReLU、LeakyRelu、Relu6
目录 为什么要用激活函数 sigmod tanh ReLU LeakyReLU ReLU6 参考资料 为什么要用激活函数 在神经网络中,如果不对上一层结点的输出做非线性转换的话,再深的网络也是线性模型 ...
随机推荐
- sql 树形递归查询
sql 树形递归查询: with ProductClass(ClassId,ClassName) as ( union all select c.ClassId,c.ClassName from Cl ...
- 【JUC】4.Synchronized与ReentrantLock对比
与synchronized相同,ReentrantLock也是一种互斥锁: synchronized与ReentrantLock的对比: 都是可重入锁 可以再次获取自己的内部锁,即:一个线程获取某对象 ...
- python接口自动化13-data和json参数傻傻分不清
前言 在发post请求的时候,有时候body部分要传data参数,有时候body部分又要传json参数,那么问题来了:到底什么时候该传json,什么时候该传data? 一.识别json参数 1.在前面 ...
- springboot 使用常用注解
找到方法封装成json格式 @RestController = @Controller+@ResponseBody //一个组合注解,用于快捷配置启动类,springboot启动主入口 @Spring ...
- docker版本lnmp
也不是全部的docker,比如php-fpm,这个可以用docker版. 但第三方插件就不灵活,所以原生的就好. 另外,在建设ftp服务时,以后要弃vsftpd而选用pure-ftp了. pure-f ...
- linux系统编程之信号(六)
今天继续学习信号相关的知识,主要还是学习sigqueue另外信号发送函数,并配合上节学习的sigaction的用法,进入正题: sigqueue函数: sigval联合体: 实际上sigval参数是用 ...
- Mybatis控制台打印SQL语句的两种方式
问题描述在使用mybatis进行开发的时候,由于可以动态拼接sql,这样大大方便了我们.但是也有一定的问题,当我们动态sql拼接的块很多的时候,我们要想从*mapper.xml中直接找出完整的sql就 ...
- Spring Boot 2.x实战之定时任务调度
在后端开发中,有些场景是需要使用定时任务的,例如:定时同步一批数据.定时清理一些数据,在Spring Boot中提供了@Scheduled注解就提供了定时调度的功能,对于简单的.单机的调度方案是足够了 ...
- 初学 Size Balanced Tree(bzoj3224 tyvj1728 普通平衡树)
SBT(Size Balance Tree), 即一种通过子树大小(size)保持平衡的BST SBT的基本性质是:每个节点的size大小必须大于等于其兄弟的儿子的size大小: 当我们插入或者删除一 ...
- LightOJ - 1282 - Leading and Trailing(数学技巧,快速幂取余)
链接: https://vjudge.net/problem/LightOJ-1282 题意: You are given two integers: n and k, your task is to ...