关于交叉熵损失函数Cross Entropy Loss
1、说在前面
最近在学习object detection的论文,又遇到交叉熵、高斯混合模型等之类的知识,发现自己没有搞明白这些概念,也从来没有认真总结归纳过,所以觉得自己应该沉下心,对以前的知识做一个回顾与总结,特此先简单倒腾了一下博客,使之美观一些,再进行总结。本篇博客先是对交叉熵损失函数进行一个简单的总结。
2、 交叉熵的来源
2.1、信息量
交叉熵是信息论中的一个概念,要想了解交叉熵的本质,需要先从最基本的概念讲起。我们先来看看什么是信息量:
事件A:巴西队进入了2018世界杯决赛圈。
事件B:中国队进入了2018世界杯决赛圈。
当你看见这两个事件,你会觉得事件B的信息量比事件A的信息量要大。究其原因,是因为事件A发生的概率很大,事件B发生的概率很小。所以当越不可能的事件发生了,我们获取到的信息量就越大。越可能发
生的事件发生了,我们获取到的信息量就越小。那么信息量应该和事件发生的概率有关。
也就是说一条信息的信息量大小和它的不确定性有很大的关系。
一句话如果需要很多外部信息才能确定,我们就称这句话的信息量比较大。
那么我们就将一个事件X_0的信息量定义如下:(其中P(x_0)表示x_0发生的概率):

由于概率P(x_0)是一个)0至1的值,所以当事件发生的概率越大时,信息量越小。
2.2、熵
信息量是对于单个事件来说的,但是实际情况一件事有很多种发生的可能,比如掷骰子有可能出现6种情况,明天的天气可能晴、多云或者下雨等等。
熵是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。公式如下:
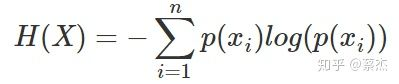 n表示事件可能发生的情况总数
n表示事件可能发生的情况总数
对于二项分布(0-1分布),比如说掷硬币只有正反两面的情况,其熵值的计算可以简化如下:
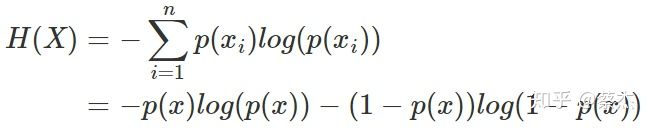
2.3、相对熵
相对熵又称KL散度(Kullback-Leibler (KL) divergence),用于衡量对于同一个随机变量x的两个单独的概率分布P(x)和Q(x)之间的差异。
In the context of machine learning, DKL(P‖Q) is often called the information gain achieved if P is used instead of Q. ——维基百科对熵的定义
即如果用P来描述目标问题,而不是用Q来描述目标问题,得到的信息增量。
在机器学习中,P往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1] 。直观的理解就是如果用P来描述样本,那么就非常完美。而用Q来描述样
本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和P一样完美的描述。如果我们的Q通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q
等价于P。
设和
是取值的两个概率概率分布,则p对q的相对熵(或者KL散度)为:
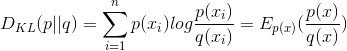 KL散度的值越小表示两个分布越接近
KL散度的值越小表示两个分布越接近
在一定程度上面,相对熵可以度量两个随机分布的距离。也常常用相对熵来度量两个随机分布的距离。当两个随机分布相同的时候,他们的相对熵为0,当两个随机分布的差别增大的时候,他们之间的相对熵也
会增大。
但是事实上,它并不是一个真正的距离。因为相对熵是不具有对称性的,即一般来说:
相对熵还有一个性质,就是不为负: 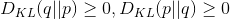
2.4、交叉熵
我们将KL散度公式进行变形得到:
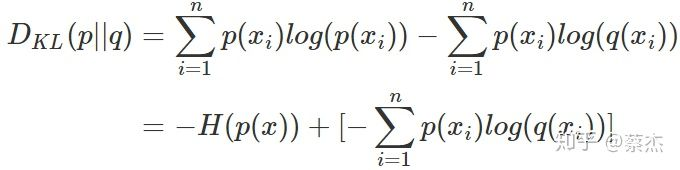
前半部分就是p(x)的熵,后半部分就是我们的交叉熵:
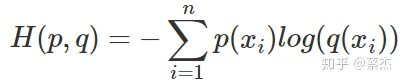
在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即
由于KL散度中的前一部分不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用交叉熵做误差函数,评估模型。
在机器学习中,我们希望在训练数据上模型学到的分布 P(model) 和真实数据的分布 P(real) 越接近越好,所以我们可以使其相对熵最小。但是我们没有真实数据的分布,所以只能希望模型学到的分布 P(model)
和训练数据的分布 P(train)尽量相同。假设训练数据是从总体中独立同分布采样的,那么我们可以通过最小化训练数据的经验误差来降低模型的泛化误差。即:
1、希望学到的模型的分布和真实分布一致,P(model)≃P(real)
2、但是真实分布不可知,假设训练数据是从真实数据中独立同分布采样的,P(train)≃P(real)
3、因此,我们希望学到的模型分布至少和训练数据的分布一致,P(train)≃P(model)
根据之前的描述,最小化训练数据上的分布 P(train)与最小化模型分布 P(model) 的差异等价于最小化相对熵,即 DKL(P(train)||P(model))。此时,P(train) 就是DKL(p||q)中的 p,即真实分布,P(model) 就是 q
又因为训练数据的分布 p 是给定的,所以求 DKL(p||q) 等价于求 H(p,q)。得证,交叉熵可以用来计算学习模型分布与训练分布之间的差异。交叉熵广泛用于逻辑回归的Sigmoid和Softmax函数中作为损失函数使
用。
3、 交叉熵损失函数 Cross Entropy Error Function
3.1、表达式
在二分类的情况
模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为 和
。此时表达式为:

其中:
- y——表示样本的label,正类为1,负类为0
- p——表示样本预测为正的概率
交叉熵损失函数在多分类的问题中的表达式:
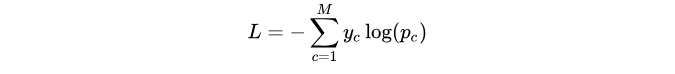
其中:
- ——类别的数量;
- ——指示变量(0或1),如果该类别和样本的类别相同就是1,否则是0;
- ——对于观测样本属于类别
的预测概率。
通常来说,交叉熵损失函数还有另外一种表达形式,对于N个样本:
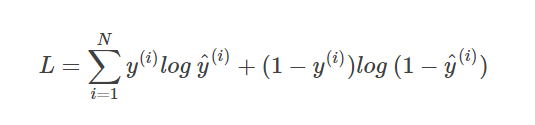
3.2、交叉熵损失函数的直观理解
首先来看单个样本的交叉熵损失函数:

当真实模型y = 1 时,损失函数的图像: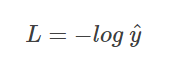
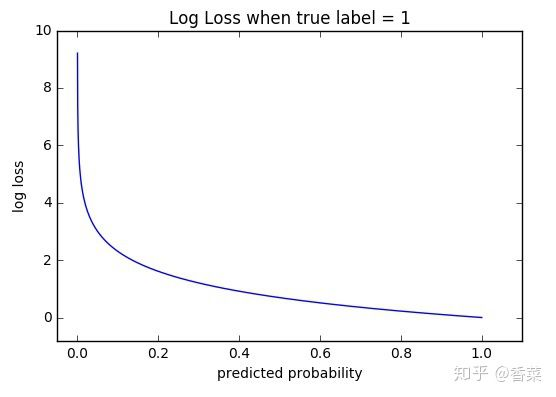
看了 L 的图形,简单明了!横坐标是预测输出,纵坐标是交叉熵损失函数 L。显然,预测输出越接近真实样本标签 1,损失函数 L 越小;预测输出越接近 0,L 越大。因此,函数的变化趋势完全符合实际需要的情况。
当 y = 0 时
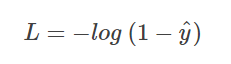
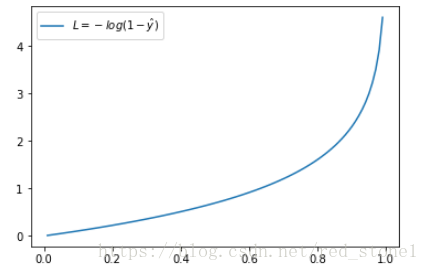
同样,预测输出越接近真实样本标签 0,损失函数 L 越小;预测函数越接近 1,L 越大。函数的变化趋势也完全符合实际需要的情况。
无论真实样本标签 y 是 0 还是 1,L 都表征了预测输出与 y 的差距。
另外,重点提一点的是,从图形中我们可以发现:预测输出与 y 差得越多,L 的值越大,也就是说对当前模型的 “ 惩罚 ” 越大,而且是非线性增大,是一种类似指数增长的级别。这是由 log 函数本身的特性所决定的。
这样的好处是模型会倾向于让预测输出更接近真实样本标签 y。
关于交叉熵损失函数Cross Entropy Loss的更多相关文章
- 关于交叉熵(cross entropy),你了解哪些
二分~多分~Softmax~理预 一.简介 在二分类问题中,你可以根据神经网络节点的输出,通过一个激活函数如Sigmoid,将其转换为属于某一类的概率,为了给出具体的分类结果,你可以取0.5作为阈值, ...
- 【机器学习基础】交叉熵(cross entropy)损失函数是凸函数吗?
之所以会有这个问题,是因为在学习 logistic regression 时,<统计机器学习>一书说它的负对数似然函数是凸函数,而 logistic regression 的负对数似然函数 ...
- 【联系】二项分布的对数似然函数与交叉熵(cross entropy)损失函数
1. 二项分布 二项分布也叫 0-1 分布,如随机变量 x 服从二项分布,关于参数 μ(0≤μ≤1),其值取 1 和取 0 的概率如下: {p(x=1|μ)=μp(x=0|μ)=1−μ 则在 x 上的 ...
- TensorFlow 实战(一)—— 交叉熵(cross entropy)的定义
对多分类问题(multi-class),通常使用 cross-entropy 作为 loss function.cross entropy 最早是信息论(information theory)中的概念 ...
- [ch03-02] 交叉熵损失函数
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 3.2 交叉熵损失函数 交叉熵(Cross Entrop ...
- 从交叉熵损失到Facal Loss
1交叉熵损失函数的由来1.1关于熵,交叉熵,相对熵(KL散度) 熵:香农信息量的期望.变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大.其计算公式如下: 其是一个期望的计算,也是记录随 ...
- 深度学习原理与框架-神经网络结构与原理 1.得分函数 2.SVM损失函数 3.正则化惩罚项 4.softmax交叉熵损失函数 5. 最优化问题(前向传播) 6.batch_size(批量更新权重参数) 7.反向传播
神经网络由各个部分组成 1.得分函数:在进行输出时,对于每一个类别都会输入一个得分值,使用这些得分值可以用来构造出每一个类别的概率值,也可以使用softmax构造类别的概率值,从而构造出loss值, ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- softmax交叉熵损失函数求导
来源:https://www.jianshu.com/p/c02a1fbffad6 简单易懂的softmax交叉熵损失函数求导 来写一个softmax求导的推导过程,不仅可以给自己理清思路,还可以造福 ...
随机推荐
- Codeforces Round 584 题解
-- A,B 先秒切,C 是个毒瘤细节题,浪费了很多时间后终于过了. D 本来是个 sb 题,然而还是想了很久,不过幸好没什么大事. E1,看了一会就会了,然而被细节坑死,好久才过. 感觉 E2 很可 ...
- Vue组件的操作-自定义组件,动态组件,递归组件
作者 | Jeskson 来源 | 达达前端小酒馆 v-model双向绑定 创建双向数据绑定,v-model指令用来在input,select,checkbox,radio等表单控件.v-model指 ...
- [LeetCode] 457. Circular Array Loop 环形数组循环
You are given a circular array nums of positive and negative integers. If a number k at an index is ...
- [LeetCode] 15. 3Sum 三数之和
Given an array S of n integers, are there elements a, b, c in S such that a + b + c = 0? Find all un ...
- android 完全退出实现
实现方法是在application中定义一个集合存储所有的Activity对象,在Activity创建时添加进集合中,在程序退出时,finish掉所有的Activity即可. 步骤如下: 1.自定义A ...
- 不同种类的ICP算法
摘自<三维点云数据拼接中ICP及其改进算法综述>
- Django中render_to_response和render的区别(转载)
转载地址:https://www.douban.com/note/278152737/ 自django1.3开始:render()方法是render_to_response的一个崭新的快捷方式,前者会 ...
- 计时器StopWatch的几种写法
下面提供三种计时器的写法供大家参考,大家可以自行选择自己钟爱的使用. 写法一(Spring 包提供的计时器): import java.text.NumberFormat; import java.u ...
- 微软 Azure DevOps Server 2019 Update 1 (TFS 2019.1)
1.概述 微软在2019年5月发布Azure DevOps Server 2019后不到2个月的时间里,就快速准备好了第一个升级包(2019 Update 1),并计划在几周后发布正式版本.也许你还没 ...
- java,string和list,list和set相互转换
list转string String str= String.join("','", list); list转set Set<String> set = new Has ...