利用csv文件信息,将图片名信息保存到csv文件当中
我们可以利用train.csv文件信息, 再结合给定的文件路径(path)信息,可以将给定字目录下的图片名信息整合到scv文件当中。
train.csv文件格式:
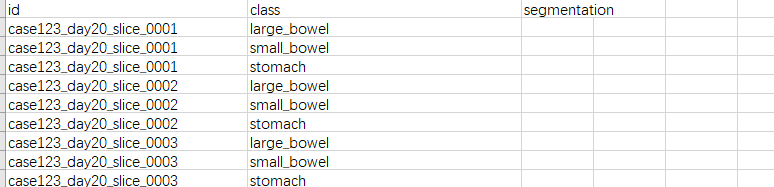
图片名信息:
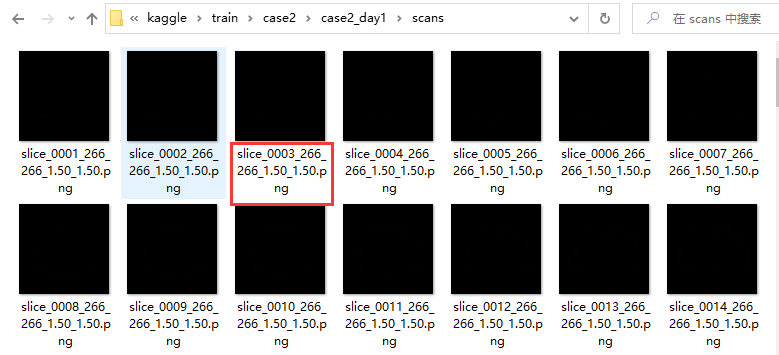
代码如下:
from glob import glob
import pandas as pd
import os def enrich_data(df, sdir="train"):
imgs = glob(os.path.join(DATASET_FOLDER, sdir, "case*", "case*_day*", "scans", "*.png"))
img_folders = [os.path.dirname(p).split(os.path.sep) for p in imgs]
img_names = [os.path.splitext(os.path.basename(p))[0].split("_") for p in imgs]
img_keys = [f"{f[-2]}_slice_{n[1]}" for f, n in zip(img_folders, img_names)] # print(img_keys[:5])
df["img_path"] = df["id"].map({k: p for k, p in zip(img_keys, imgs)})
df["Case_Day"] = df["id"].map({k: f[-2] for k, f in zip(img_keys, img_folders)})
df["Case"] = df["id"].apply(lambda x: int(x.split("_")[0].replace("case", "")))
df["Day"] = df["id"].apply(lambda x: int(x.split("_")[1].replace("day", "")))
df["Slice"] = df["id"].map({k: int(n[1]) for k, n in zip(img_keys, img_names)})
df["width"] = df["id"].map({k: int(n[2]) for k, n in zip(img_keys, img_names)})
df["height"] = df["id"].map({k: int(n[3]) for k, n in zip(img_keys, img_names)})
df["spacing1"] = df["id"].map({k: float(n[4]) for k, n in zip(img_keys, img_names)})
df["spacing2"] = df["id"].map({k: float(n[5]) for k, n in zip(img_keys, img_names)}) if __name__ == "__main__":
# df_ssub = pd.read_csv(os.path.join(DATASET_FOLDER, "sample_submission.csv"))
DATASET_FOLDER = "D:\compation\kaggle"
df_ssub = pd.read_csv(os.path.join(DATASET_FOLDER, "train.csv","traines.csv"))
enrich_data(df_ssub,"traines")
df_ssub.to_csv("df.csv")
print(df_ssub["Case_Day"][4])
结果:
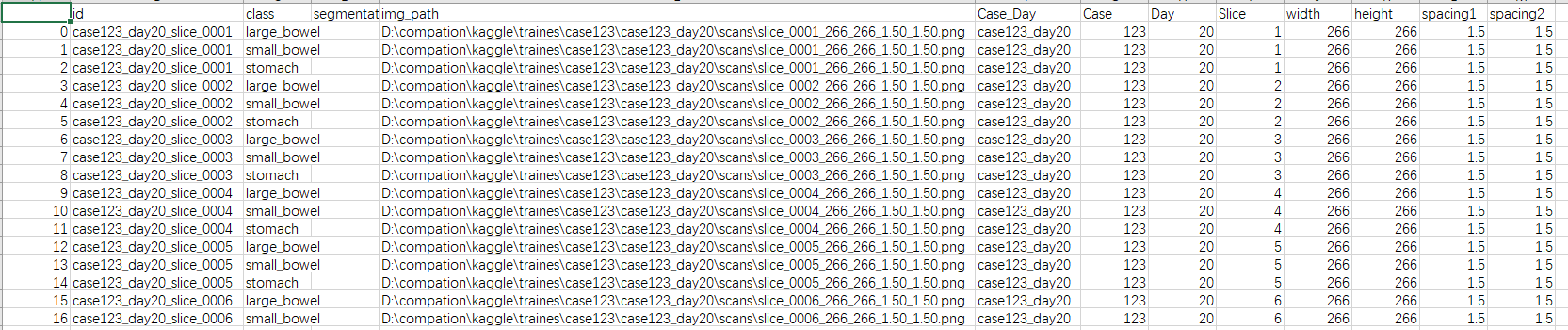
利用csv文件信息,将图片名信息保存到csv文件当中的更多相关文章
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- 记录python爬取猫眼票房排行榜(带stonefont字体网页),保存到text文件,csv文件和MongoDB数据库中
猫眼票房排行榜页面显示如下: 注意右边的票房数据显示,爬下来的数据是这样显示的: 网页源代码中是这样显示的: 这是因为网页中使用了某种字体的缘故,分析源代码可知: 亲测可行: 代码中获取的是国内票房榜 ...
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- ffmpeg学习(二) 通过rtsp获取H264裸流并保存到mp4文件
本篇将使用上节http://www.cnblogs.com/wenjingu/p/3977015.html中编译好的库文件通过rtsp获取网络上的h264裸流并保存到mp4文件中. 1.VS2010建 ...
- python scrapy实战糗事百科保存到json文件里
编写qsbk_spider.py爬虫文件 # -*- coding: utf-8 -*- import scrapy from qsbk.items import QsbkItem from scra ...
- php将图片以二进制保存到mysql数据库并显示
一.存储图片的数据表结构: -- -- 表的结构 `image` -- CREATE TABLE IF NOT EXISTS `image` ( `id` int(3) NOT NULL AUTO_I ...
- Android相机、相册获取图片显示并保存到SD卡
Android相机.相册获取图片显示并保存到SD卡 [复制链接] 电梯直达 楼主 发表于 2013-3-13 19:51:43 | 只看该作者 |只看大图 本帖最后由 happy小妖同学 ...
- iOS开发——数据持久化&本地数据的存储(使用NSCoder将对象保存到.plist文件)
本地数据的存储(使用NSCoder将对象保存到.plist文件) 下面通过一个例子将联系人数据保存到沙盒的“documents”目录中.(联系人是一个数组集合,内部为自定义对象). 功能如下: ...
- np.savetxt()——将array保存到txt文件,并保持原格式
问题:1.如何将array保存到txt文件中?2.如何将存到txt文件中的数据读出为ndarray类型? 需求:科学计算中,往往需要将运算结果(array类型)保存到本地,以便进行后续的数据分析. 解 ...
随机推荐
- CSP-S提高组数据结构算法模板大合集
CSP-S 算法总结 2.2.1 基础知识与编程环境 无 2.2.2 C++ 程序设计 2 set/nultiset map/multimap deque/priority_queue STL 2.2 ...
- 亚马逊 vpc 子网 路由表 互联网网关 弹性ip
创建vpc,子网,路由表,互联网网关,弹性ip等网络资源 vpc和子网 创建互联网网关 附加到vpc 创建路由表 路由表编辑路由 此路由通过这个网关出去 编辑子网关联 保存关联 有关云主机 创建属于那 ...
- 【Java】删除项目中多余的SVG图片资源
在DB库的菜单表,每个菜单会存放对应的svg图片名称,用于菜单渲染 在页面中的渲染: 在项目的目录的存放位置: 需求是这个目录还存放了很多不需要的svg图片,需要把他们删除掉 数量有七八十张,人肉手删 ...
- 人形机器人的AI技术 —— 将一个大问题拆解为若干个小问题
前文: 人形机器人 -- Figure 01机器人亮相 | OpenAI多模态能力加持 | 与人类流畅对话交互 | 具身智能的GPT-4时刻 所需的AI技术: 人形机器人的软件层面其实有: 视觉模块/ ...
- springboot实现事务管理
Springboot实现事务步骤1.在启动类加上@EnableTransactionManagement 2.在业务层方法上加 @Transactional(rollbackFor = Excepti ...
- 手把手教你利用鸿蒙OS实现智慧家居·LOT上云项目
手把手教你利用鸿蒙OS实现智慧家居·LOT上云项目 一.前言 今天使用鸿蒙OS,做一个LOT上云的智慧家居项目.我们想实现的场景是这样的:云端WEB有一个控制界面,能够操控家房间里的灯和风扇,同时将房 ...
- C语言编程-GCC编译过程
gcc编译 预处理 ->编译->汇编->链接 预处理 gcc -E helloworld.c -o helloworld.i 头文件展开:不检查语法错误,即可以展开任意文件: 宏定义 ...
- MFC状态栏的创建与添加进度条
1.首先要创建状态栏 MFC中创建状态栏是用数组来分隔格子的.所以要先弄个数组 下面在自己继承的CWnd类.cpp文件中定义一个静态数组indicators static UINT indicator ...
- 华为交换机S5700-52C-SI配置vlan
环境准备:通过超级终端Hyper Terminal和console串口线链接华为交换机,用9600波特率链接 添加vlan <Quidway>system-view #由用户视图进入系统视 ...
- C++技能树