DBSCAN聚类
一、概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,簇集的划定完全由样本的聚集程度决定。聚集程度不足以构成簇落的那些样本视为噪声点,因此DBSCAN聚类的方式也可以用于异常点的检测。
二、算法原理
1.基本原理
算法的关键在于样本的‘聚集程度’,这个程度的刻画可以由聚集半径和最小聚集数两个参数来描述。如果一个样本聚集半径领域内的样本数达到了最小聚集数,那么它所在区域就是密集的,就可以围绕该样本生成簇落,这样的样本被称为核心点。如果一个样本在某个核心点的聚集半径领域内,但其本身又不是核心点,则被称为边界点;既不是核心点也不是边界点的样本即为噪声点。其中,最小聚集数通常由经验指定,一般是数据维数+1或者数据维数的2倍。
通俗地讲,核心点就是构成一个簇落的核心成员;边界点就是构成一个簇落的非核心成员,它们分布于簇落的边界区域;噪声点是无法归属在任何一个簇集的游离的异常样本。如图所示。
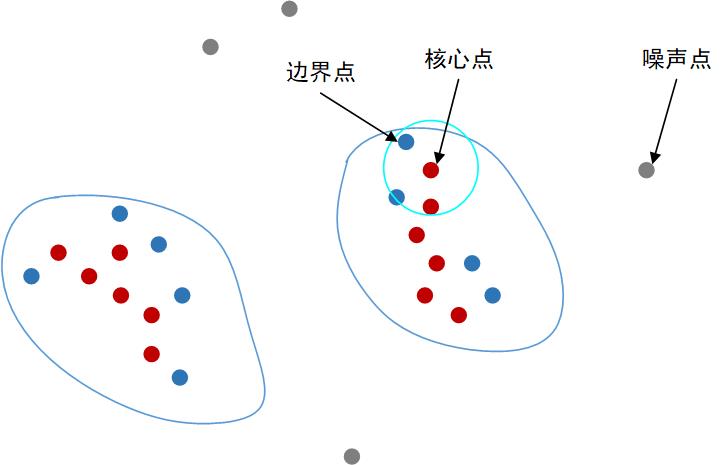
对于聚成的簇集,这里有三个相关的概念:密度直达,密度可达,密度相连。
密度直达: 对一个核心点p,它的聚集半径领域内的有点q,那么称p到q密度直达。密度直达不具有对称性。
密度可达: 有核心点p1,p2,…,pn,非核心点q,如果pi到pi+1(i=1,2,…,n-1)是密度直达的,pn到q是密度直达的,那么称核心点pi(i=1,2,…,n)到其他的点是密度可达的。密度可达不具有对称性。
密度相连: 如果有核心点P,到两个点A和B都密度可达,那么称A和B密度相连。密度相连具有对称性。
简单地讲,核心点到其半径邻域内的点是密度直达的;核心点到其同簇集内的点是密度可达的;同一个簇集里的成员间是密度相连的。

由定义易知,密度直达一定密度可达,密度可达一定密度相连。密度相连就是对聚成的一个簇集最直接的描述。
2.算法描述
输入: 样本集D,聚集半径r,最小聚集数MinPts;
输出: 簇集C1,C2,…,Cn,噪声集O.
根据样本聚集程度,传播式地划定聚类簇,并将不属于任何一个簇的样本划入噪声集合。
(1)随机搜寻一个核心点p,
S1.从样本集D中随机选择一个未归入任何集合的且未被标记的样本对象p
S2.计算p的r邻域大小\(\left| N_r(p) \right|\)
若\(\left| N_r(p) \right|\geq MinPts\) ,则标记为核心点;否则,标记为非核心点,并选择其他的点进行判别.
S3.重复上面的步骤,直至找到一个核心点;若未找到,将未归集的样本划入噪声集O.
(2)在核心点p处建立簇C,将r邻域内所有的点加入簇C.
(3)对邻域内所有未被标记的点迭代式进行考察,扩展簇集.
若一个邻域点q为核心点,则将它领域内未归入集合的点加入簇C中.
(4)重复以上步骤,直至所有样本划入了指定集合;
(5)输出簇集C1,C2,…,Cn和噪声集合O。
3.优缺点
优势:
1.可以发现任意形状的簇,适用于非凸数据集;
2.可以进行异常检测;
3.不需要指定簇数,根据样本的密集程度适应性地聚集。
不足:
1.当样本集密度不均匀,不同簇中的平均密度相差较大时,效果较差;
2.聚集半径和最小聚集数两个参数需人工指定。
三、示例
假设二维空间中有下列样本,坐标为
(1,2),(1,3),(3,1),(2,2),(9,8),(8,9),(9,9),(18,18)
由DBSCAN算法完成聚类操作。
过程演算:
由经验指定参数聚集半径r=2,最小聚集数MinPts=3。
(1)随机搜寻一个核心点,若不存在,返回噪声集合。
考察点(1,2),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(1,2)为核心点。
(2)在核心点(1,2)处建立簇C1,原始簇成员为r邻域内样本:(1,2)、(1,3)、(2,2)。
(3)对簇落C1成员迭代式进行考察,扩展簇集。
先考察(1,3),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(1,3)为核心点,它邻域内的样本均已在簇C1中,无需进行操作。
再考察(2,2),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共四个样本点,达到了MinPts数,因此(2,2)为核心点,将它领域内尚未归入任何一个簇落的点(3,1)加入簇C1。
再考察(3,1),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共两个样本点,因此(3,1)是非核心点。
考察结束,簇集C1扩展完毕。
(4)在其余未归簇的样本点中搜寻一个核心点,若不存在,返回噪声集合。
考察点(9,8),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(9,8)为核心点。
(5)在核心点(9,8)处建立簇C2,原始簇成员为r邻域内样本:(9,8)、(8,9)、(9,9)。
(6)对簇落C2成员迭代式进行考察,扩展簇集。
先考察(8,9),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(8,9)为核心点,它邻域内的样本均已在簇C2中,无需进行操作。
再考察(9,9),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(9,9)为核心点。它邻域内的样本均已在簇C2中,无需进行操作。
考察结束,簇集C2扩展完毕。
(7)在其余未归簇的样本点中搜寻一个核心点,若不存在,返回噪声集合。
其余未归簇的样本点集合为{(18,18)},考察(18,18),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共一个样本点,未达到MinPts数,因此(18,18)为非核心点。其余未归簇的样本中不存在核心点,因此归入噪声集O={(18,18)}。
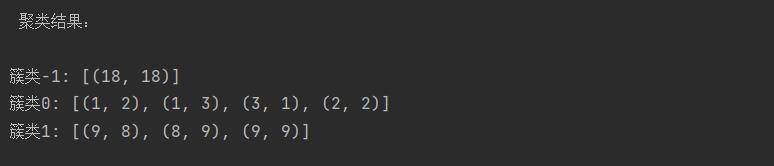
(8)输出聚类结果
簇类C1:{(1,2),(1,3),(3,1),(2,2)}
簇类C2:{(9,8),(8,9),(9,9)}
噪声集O:{(18,18)}
四、Python实现
示例的Python实现。
'''
功能:用python实现DBSCAN聚类算法。
'''
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt
# 初始化数据
data = np.array([(1,2),(1,3),(3,1),(2,2),
(9,8),(8,9),(9,9),
(18,18)])
# 定义DBSCAN模型
dbscan = DBSCAN(eps=2,min_samples=3)
# 计算数据,获取标签
labels = dbscan.fit_predict(data)
# 定义颜色列表
colors = ['b','r','c']
T = [colors[i] for i in labels]
# 输出簇类
print('\n 聚类结果: \n')
ue = np.unique(labels)
for i in range(ue.size):
CLS = []
for k in range(labels.size):
if labels[k] == ue[i]:
CLS.append(tuple(data[k]))
print('簇类{}:'.format(ue[i]),CLS)
# 结果可视化
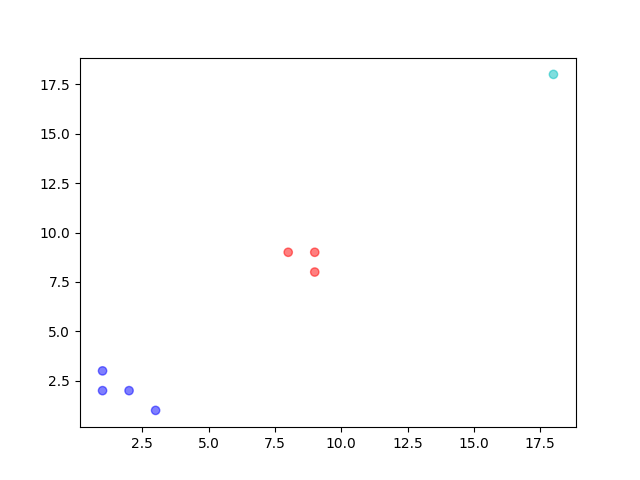
plt.figure()
plt.scatter(data[:,0],data[:,1],c=T,alpha=0.5) # 绘制数据点
plt.show()
运行结果:
End.
DBSCAN聚类的更多相关文章
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- [MCM] K-mean聚类与DBSCAN聚类 Python
import matplotlib.pyplot as plt X=[56.70466067,56.70466067,56.70466067,56.70466067,56.70466067,58.03 ...
- 5.无监督学习-DBSCAN聚类算法及应用
DBSCAN方法及应用 1.DBSCAN密度聚类简介 DBSCAN 算法是一种基于密度的聚类算法: 1.聚类的时候不需要预先指定簇的个数 2.最终的簇的个数不确定DBSCAN算法将数据点分为三类: 1 ...
- 机器学习入门-DBSCAN聚类算法
DBSCAN 聚类算法又称为密度聚类,是一种不断发张下线而不断扩张的算法,主要的参数是半径r和k值 DBSCAN的几个概念: 核心对象:某个点的密度达到算法设定的阈值则其为核心点,核心点的意思就是一个 ...
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- 5.机器学习——DBSCAN聚类算法
1.优缺点 优点: (1)聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类: (2)与K-MEANS比较起来,不需要输入要划分的聚类个数: (3)聚类簇的形状没有偏倚: (4)可以在需要时输入过 ...
- Python机器学习——DBSCAN聚类
密度聚类(Density-based Clustering)假设聚类结构能够通过样本分布的紧密程度来确定.DBSCAN是常用的密度聚类算法,它通过一组邻域参数(ϵϵ,MinPtsMinPts)来描述样 ...
- 机器学习之DBSCAN聚类算法
可以看该博客:https://www.cnblogs.com/aijianiula/p/4339960.html 1.知识点 """ 基本概念: 1.核心对象:某个点的密 ...
- Python实现DBSCAN聚类算法(简单样例测试)
发现高密度的核心样品并从中膨胀团簇. Python代码如下: # -*- coding: utf-8 -*- """ Demo of DBSCAN clustering ...
- 初探DBSCAN聚类算法
DBSCAN介绍 一种基于密度的聚类算法 他最大的优势是可以发现任意形状的聚类簇,而传统的聚类算法只能使用凸的样本聚集类 两个参数: 邻域半径R和最少点数目minpoints. 当邻域半径R内的点的个 ...
随机推荐
- 【Ubuntu】1. 创建虚拟机
这一篇主要写了虚拟机的创建,不包含操作系统的安装,中间有些步骤没有提到的根据默认操作即可,也可以根据个人情况设置. 点击创建新的虚拟机 这一步可以选择典型安装,过程更简单些,这里我选择自定义. 在安装 ...
- cat,more,cp,mv,rm,命令
cat命令 查看文件内容 语法:cat[linux路径] more命令查看文件内容 more命令同样可以查看文件内容, 同cat不同的是: •cat是直接将内容全部显示出来 •more支持翻页,如果文 ...
- 2022-04-15:给定一个非负数组arr,学生依次坐在0~N-1位置,每个值表示学生的安静值, 如果在i位置安置插班生,那么i位置的安静值变成0,同时任何同学都会被影响到而减少安静值, 同学安静值
2022-04-15:给定一个非负数组arr,学生依次坐在0~N-1位置,每个值表示学生的安静值, 如果在i位置安置插班生,那么i位置的安静值变成0,同时任何同学都会被影响到而减少安静值, 同学安静值 ...
- 2021-07-14:接雨水。给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
2021-07-14:接雨水.给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水. 福大大 答案2021-07-14: 左右指针向中间移动.左指针是左边柱 ...
- 2021-11-19:[0,4,7] : 0表示这里石头没有颜色,如果变红代价是4,如果变蓝代价是7,[1,X,X] : 1表示这里石头已经是红,而且不能改颜色,所以后两个数X无意义,[2,X,X]
2021-11-19:[0,4,7] : 0表示这里石头没有颜色,如果变红代价是4,如果变蓝代价是7,[1,X,X] : 1表示这里石头已经是红,而且不能改颜色,所以后两个数X无意义,[2,X,X] ...
- Anaconda网址
Anaconda: python全家桶,之前还有32位,现在需要64位. 官方网址:https://www.anaconda.com/ 国内源:https://mirrors.tuna.tsinghu ...
- 02.详解盒子模型&选择器初识
1.Div盒子 用div做圆 能否优化,去掉div之间的距离?margin属性 用表格做圆 2.CSS样式 总结:需要注意的是行级标签设置宽高不会生效 小练习:使用span标签 3.CSS选择器演示及 ...
- 翻译:REST 和 gRPC 详细比较
译者注:在微服务架构设计,构建API和服务间通信技术选型时,对 REST 和 gRPC 的理解和应用还存在知识盲区,近期看到国外的这篇文章:A detailed comparison of REST ...
- 花了半天时间,使用spring-boot实现动态数据源,切换自如
在一个项目中使用多个数据源的情况很多,所以动态切换数据源是项目中标配的功能,当然网上有相关的依赖可以使用,比如动态数据源,其依赖为, <dependency> <groupId& ...
- String和new String的那点事
String a= "test"; 此语句含义是:在常量池中创建test字符串对象,变量aa是对常量池中此对象的引用 String aa = new String("te ...