MySQL系列之——索引作用、索引的种类、B树、聚簇索引构建B树、辅助索引(S)构建B+树、辅助索引细分、索引树的高度、索引的基本管理、执行计划获取及分析、索引应用规范、优化器针对索引、问题汇总
文章目录
一 索引作用
提供了类似于书中目录的作用,目的是为了优化查询
二 索引的种类(算法)
B树索引:b tree, B+tree,B*tree
Hash索引
R树
Full text
GIS
三 B树 基于不同的查找算法分类介绍
B 树
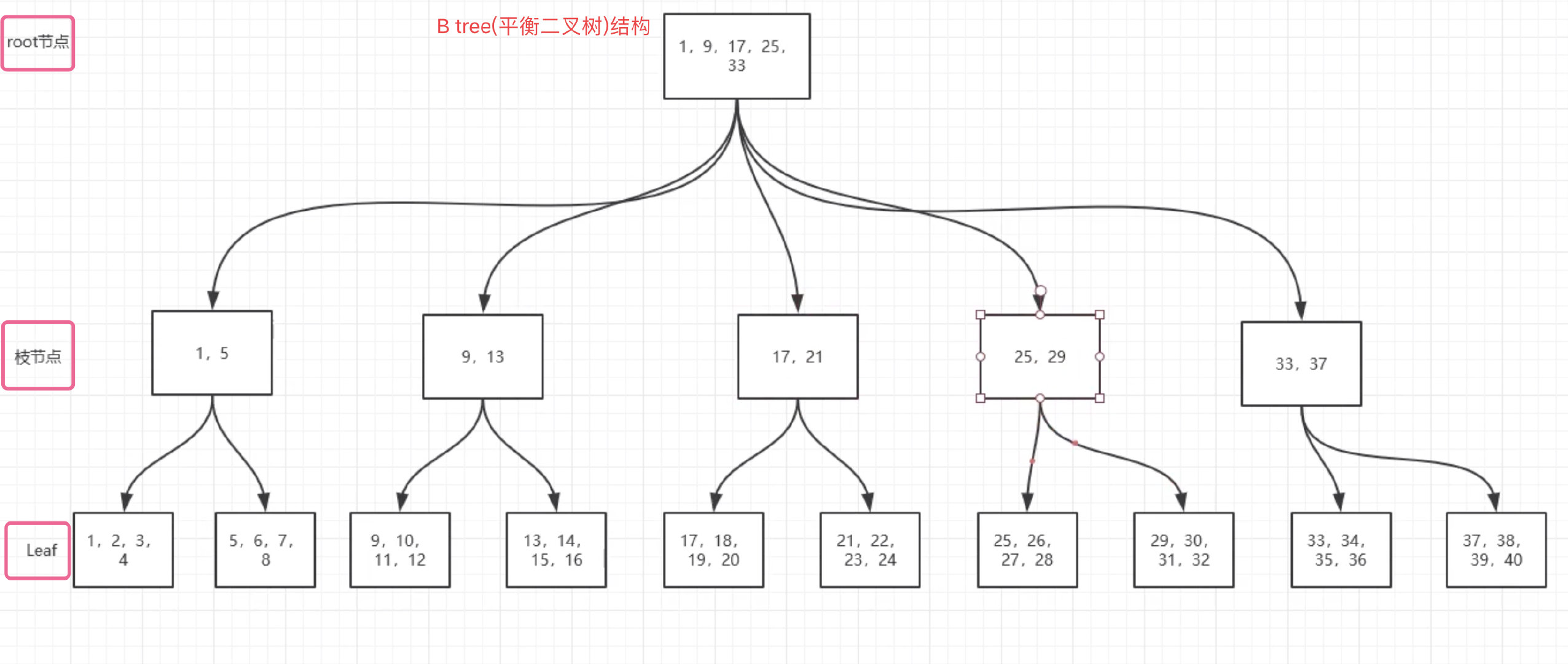
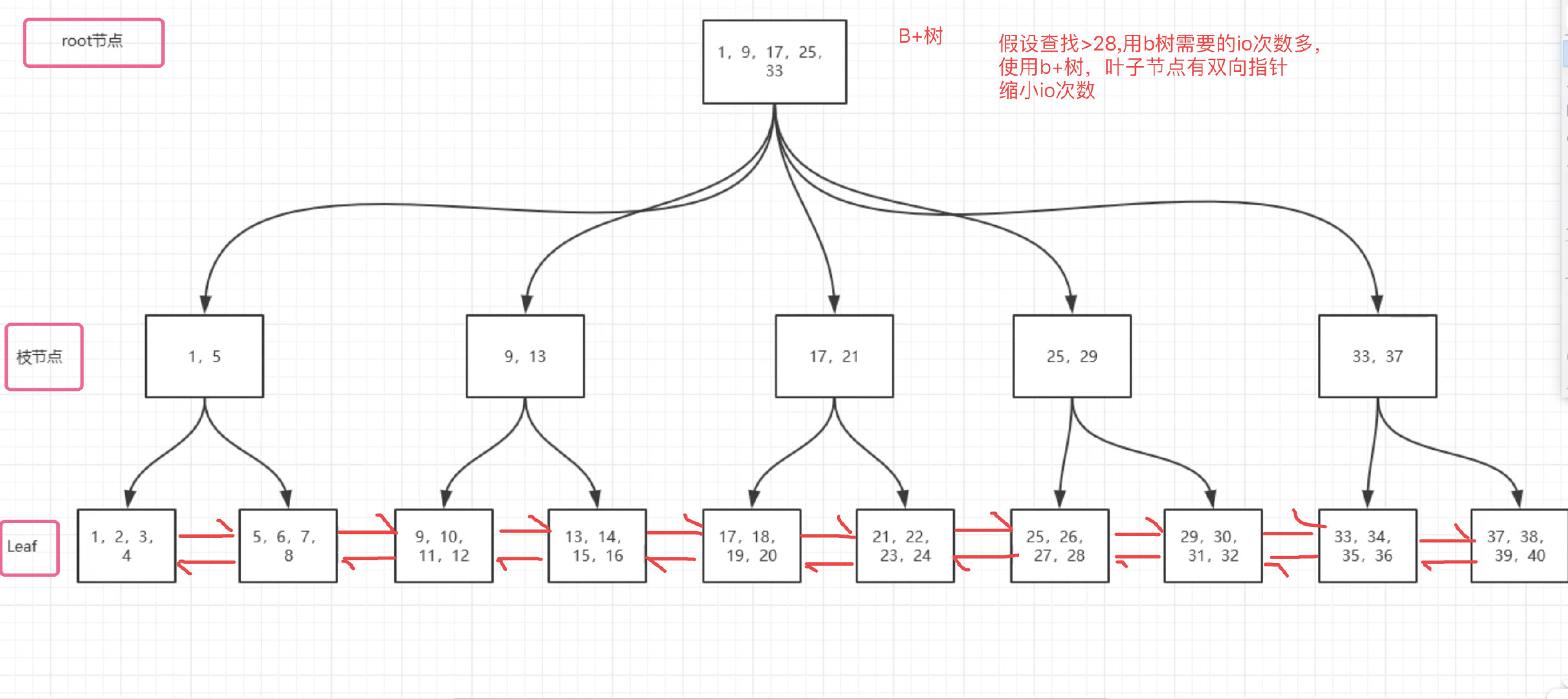
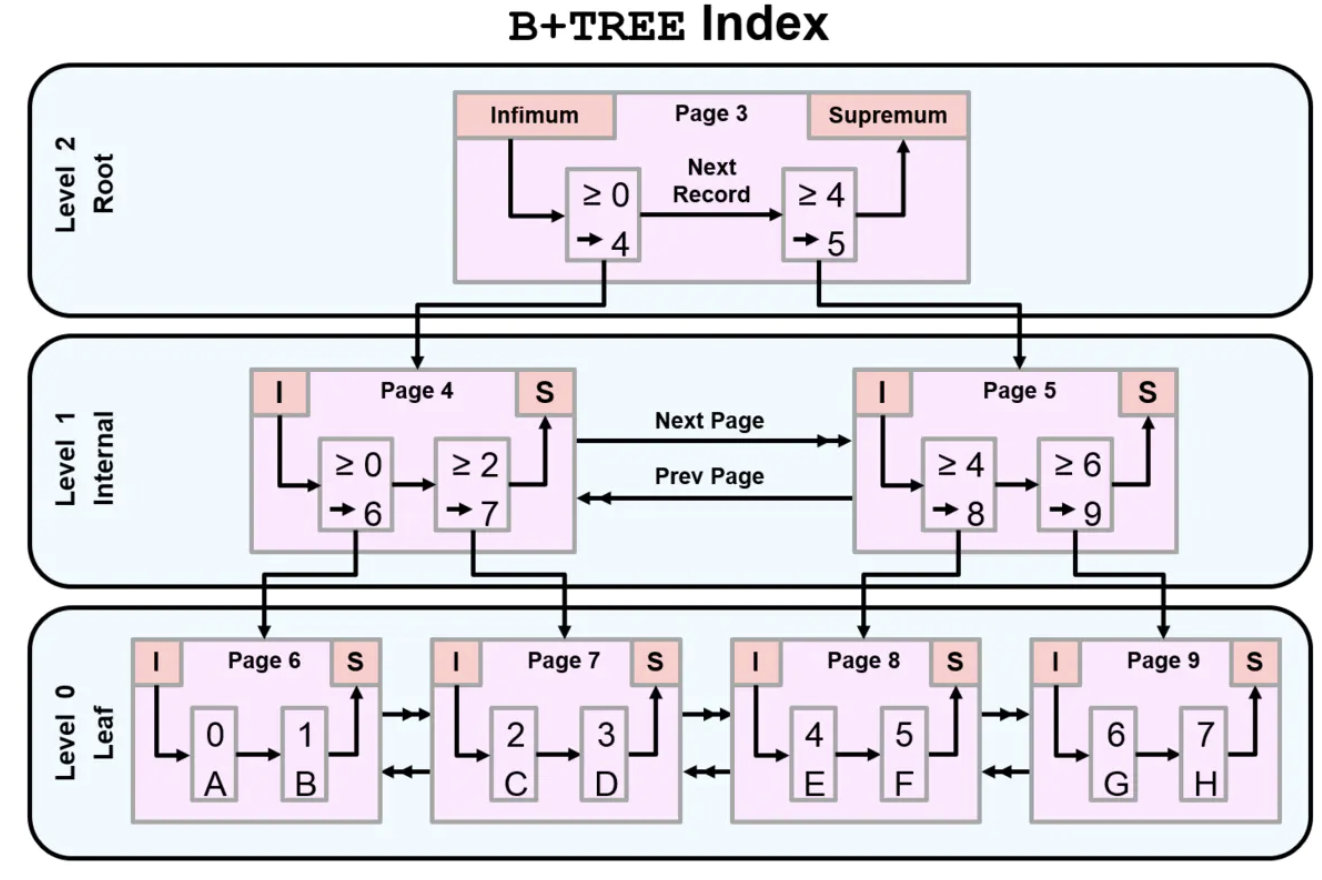
B+树
B*树
在b+tree基础上,枝节点也加入了双向指针(Innodb,使用B*树)
B-tree
B+Tree 在范围查询方面提供了更好的性能(> < >= <= like)
B*Tree
四 在功能上的分类
4.1 聚簇索引构建B树(簇就是区)
4.1.1 前提
(1)建表时,指定了主键列,MYSQL InnoDB会将主键作为聚簇索引列,比如 id not null primary key
(2)如果没有主键,会选择唯一键(unique)作为聚集索引.
(3)聚簇必须在建表时才有意义,一般是表的无关列(ID)
(4)如果以上都没有,自动生成隐藏的聚簇索引
4.1.2 作用
有了聚簇索引,将来插入的数据行,在同一个区内,都会按照id值的顺序,有序存储数据
4.2.3 聚簇索引构建B树过程
段:一个表就是一个段,可以由一个或者多个区构成
区/簇:一个区(簇),默认1M,连续的64个页(pages),一张表由多个簇构成
页:一个页,默认16k,连续的4个os的block,最小的存储单元
# 注意
上图只是举例说明,并不是一个叶子节点只存4行数据
枝节点也是由一个页存储,当然存储的数据可能更多
一颗b树索引至少要有root节点和叶子节点,枝节点可以没有(数据量少的情况)
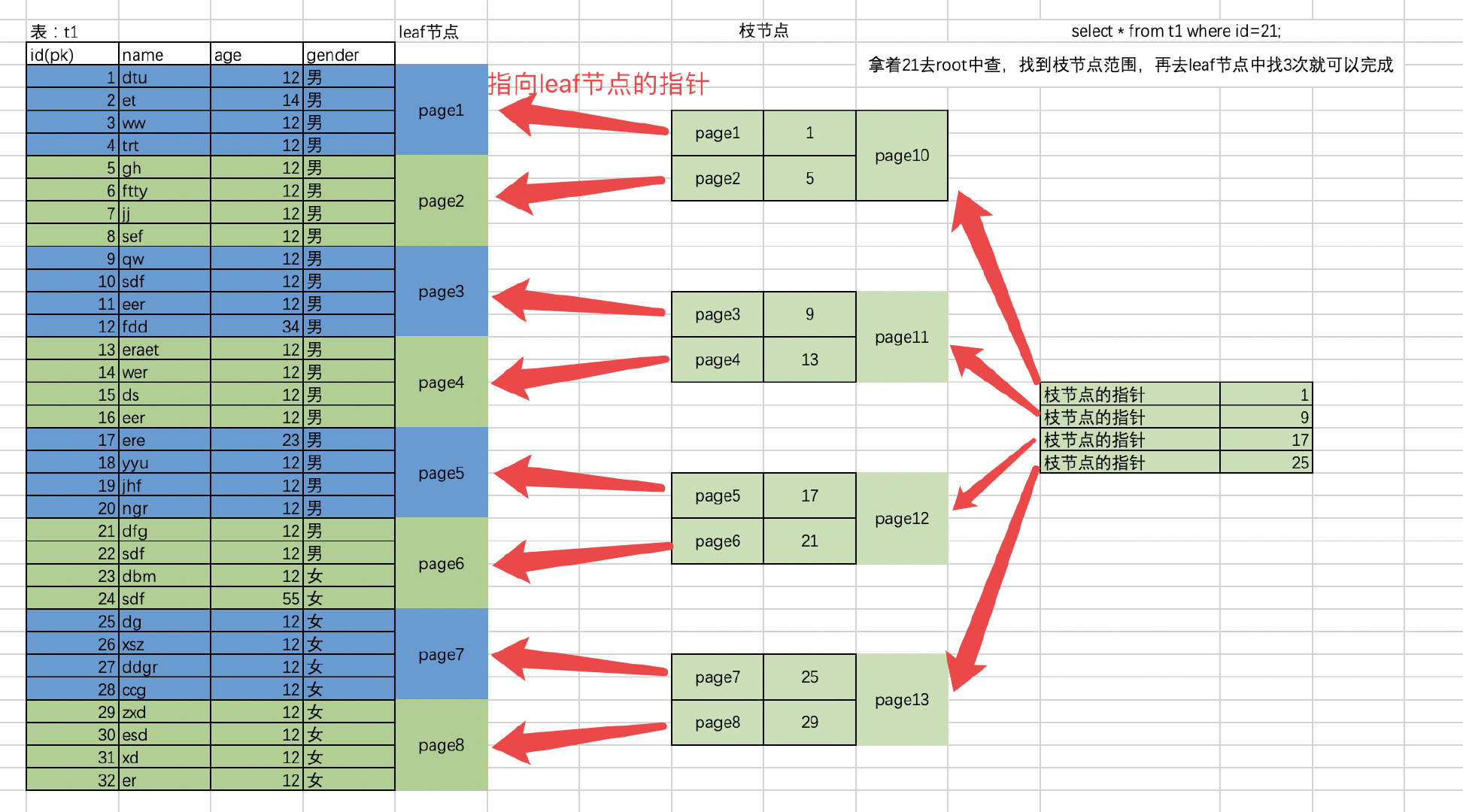
聚簇索引的作用:拿主键列去查询的时候,可以快速锁定要查询的数据行所在的页,3次io
如果没有这个,需要全表扫描,代价很高,只能加速有主键列的查询速度,所以按主键查,是效率最高的
mysql 的 innoDB的表,是聚簇索引组织存储数据表,每个页是稀疏存储,不一定全存满整个页
# 其他列怎么办?引出辅助索引
4.2 辅助索引(S)构建B+树
4.2.1 前提
在除主键以外的普通列上构建索引,例如name字段
4.2.2 作用
优化非聚簇索引列之外的查询
4.2.3 辅助索引构建B树过程
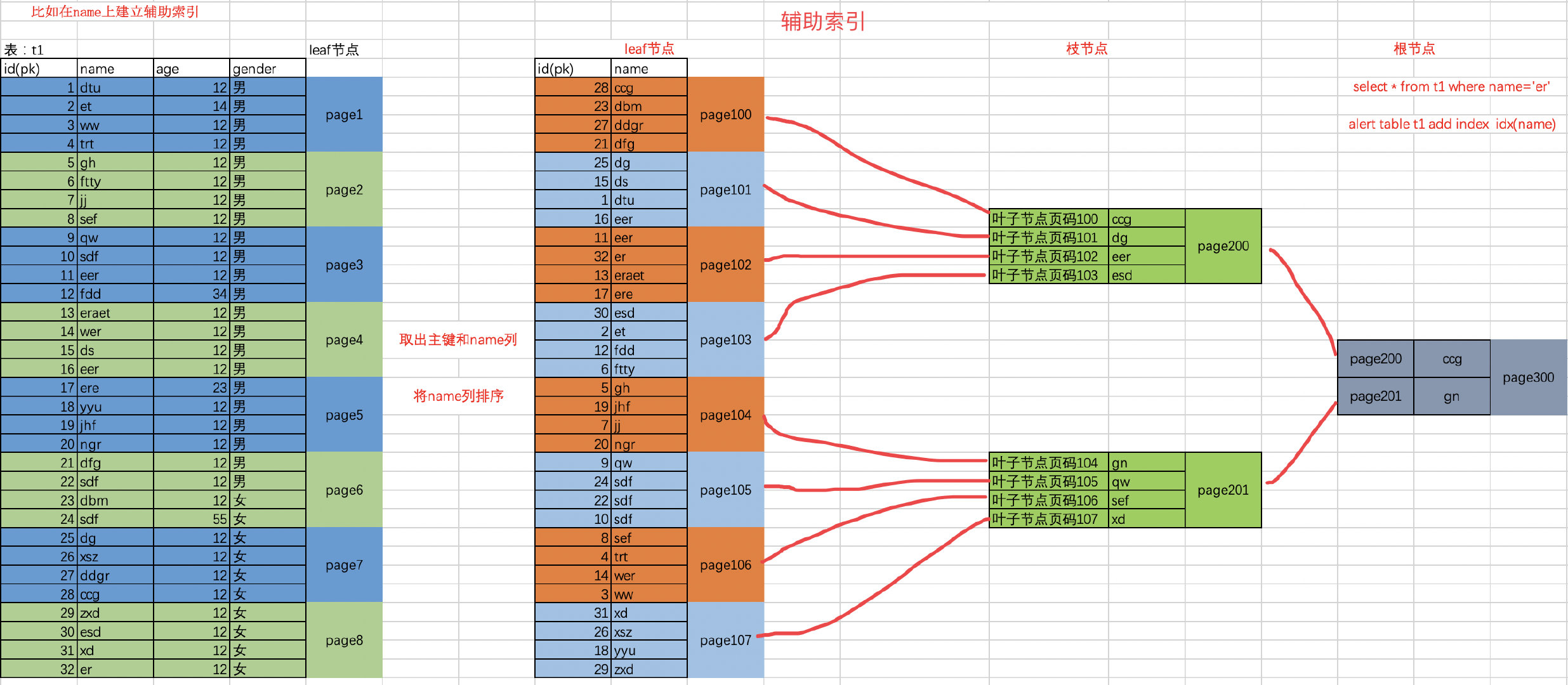
# 查询时,拿着name=er去一层一层找到er这个值,对的id,因为查的是*,所有,通过id再去原来的聚簇索引中找具体数据(回表过程)
(1). 索引是基于表中,列(索引键)的值生成的B树结构
(2). 首先提取此列所有的值,进行自动排序
(3). 将排好序的值,均匀的分布到索引树的叶子节点中(16K)
(4). 然后生成此索引键值所对应得后端数据页的指针
(5). 生成枝节点和根节点,根据数据量级和索引键长度,生成合适的索引树高度
id name age gender
select * from t1 where id=10;
问题: 基于索引键做where查询,对于id列是顺序IO,但是对于其他列的查询,可能是随机IO.
4.4 聚簇索引和辅助索引构成区别
# 聚集索引只能有一个,非空唯一,一般时主键
# 辅助索引,可以有多个,时配合聚集索引使用的
# 聚簇索引叶子节点,就是磁盘的数据行存储的数据页,辅助索引不存整体数据
# MySQL是根据聚簇索引,组织存储数据,数据存储时就是按照聚集索引的顺序进行存储数据
# 辅助索引,只会提取索引键值,进行自动排序生成B树结构
五 辅助索引细分
# 1.普通的单列辅助索引
# 2.联合索引(多列构建一个索引)
多个列作为索引条件,生成索引树,理论上设计的好的,可以减少大量的回表
如果 select * from t1 where name='er' and gender='男'; 这种比较多,建议name和gender建联合索引
构建索引过程相同,只不过现在按name和gender两列排序,生成枝节点时,只存储最左列(name)的值,不会存所有索引列(name和gender),所以,重复值少的列,放在最左侧
联合索引的:注意最左原则(a,b,c 建立索引,相当于a索引,ab索引,abc索引)
1 查询条件中,必须包含最左列,上面的例子就是a列,只有b,c走不了索引,
2 建立索引时,一定要选择重复值少的列,作为最左列
# 全覆盖
select * from t1 where a = and b= or c= # 走索引(极小情况不走索引:索引失效,统计信息不真实)
select * from t1 where a = and b in and c in # in条件等同于=,也会走索引
select * from t1 where c = and b= and a = # 也会走索引,因为sql优化器会把a位置调整
select * from t1 where a = and b= order by c #全覆盖
# 部分覆盖
select * from t1 where a =
select * from t1 where a = and b=
select * from t1 where a = and c=
select * from t1 where a = and b < > >= <= like and c= # 不等值,只能覆盖到a,b 不能覆盖到c
select * from t1 where a < > >= <= like and b = like and c= # 不等值,只能覆盖到a
select * from t1 where a = order by b # 走ab的索引
select * from t1 where c = order by a # 就不走索引,多子句要按照执行顺序建立联合索引,c和a没有按顺序,不会走索引
# 不覆盖
bc
b
c
# 3.唯一索引
索引列的值都是唯一的.
# 4.前缀索引
假设建立索引的列非常长,我们选择的索引列值长度过长(一个页存储的数据固定),会导致索引树变高,导致io次数变多
mysql中建议索引树高度3--4层,800w--1000w行,20--30个列,会在3--4层之间
数据量特别少,也会有两层,根和叶子
只取大字段的前几个字符,作为索引生成条件
六 关于索引树的高度受什么影响
# 那些因素导致
1. 数据行过多,数据量级大, 解决方法:分区表(分库分表),归档表(一个月生成一个表:手工,pt-archive),分布式架构
2. 索引列值过长 , 解决方法:前缀索引
3. 数据类型:(选择合适的数据类型)
变长长度字符串,使用了char,解决方案:变长字符串使用varchar
enum类型的使用enum ('山东','河北','黑龙江','吉林','辽宁','陕西'......),enum更加省空间
1 2 3
七 索引的基本管理
7.1 索引建立前
# 什么情况下建索引
按业务语句的需求创建合适的索引,并不是将所有列都建立索引(不是越多越好)
将索引建立在经常where,group by order by join on 的条件
# 为什么不能乱建索引
1 插入,删除数据,都会涉及到索引树的更新,如果冗余索引过多,表的数据变化,可能会导致索引频繁更新,会阻塞正常业务的更新请求
2 索引过多,会导致优化器选择出现偏差,性能可能达不到预想的效果
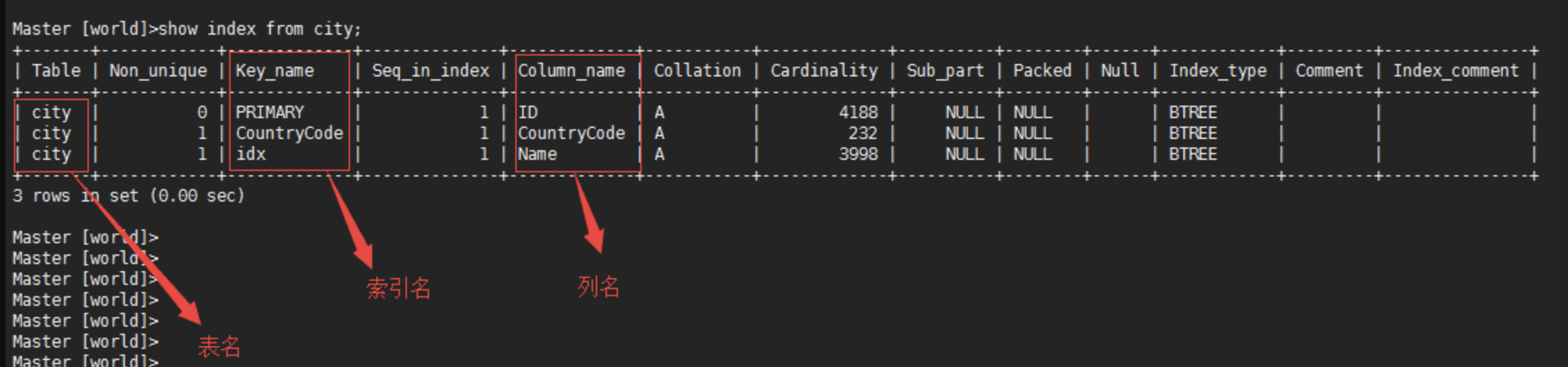
db01 [world]>desc city; # 查看表的索引情况
+-------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+----------------+
| ID | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | | | |
| CountryCode | char(3) | NO | MUL | | |
| District | char(20) | NO | | | |
| Population | int(11) | NO | | 0 | |
+-------------+----------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
Field :列名字
key :有没有索引,索引类型
PRI: 主键索引(聚簇索引)
UNI: 唯一索引,唯一建unique
MUL: 辅助索引(单列,联和,前缀)
show index from city; # 查看更具体的索引信息
7.1 单列普通辅助索引
7.1.1 创建索引,删除索引
### 新建索引
# 方式1
db01 [world]>alter table city add index idx_name(name);
表 索引名(列名)
# 方式2
db01 [world]>create index idx_name1 on city(name);
# 查看索引
db01 [world]>show index from city;
# 注意:
以上操作不代表生产操作,我们不建议在一个列上建多个索引
同一个表中,索引名不能同名。
##### 删除索引:
db01 [world]>alter table city drop index idx_name1;
表名 索引名
7.2 覆盖索引(联合索引)
Master [world]>alter table city add index idx_co_po(countrycode,population);
7.3 前缀索引
db01 [world]>alter table city add index idx_di(district(5));
注意:数字列不能用作前缀索引。
7.4 唯一索引
db01 [world]>alter table city add unique index idx_uni1(name);
ERROR 1062 (23000): Duplicate entry 'San Jose' for key 'idx_uni1'
统计city表中,以省的名字为分组,统计组的个数
select district,count(id) from city group by district;
需求: 找到world下,city表中 name列有重复值的行,最后删掉重复的行
db01 [world]>select name,count(id) as cid from city group by name having cid>1 order by cid desc;
db01 [world]>select * from city where name='suzhou';
7.5 查看是否走索引
# explain select * from city where name ='shanghai';
# 图一 type 是all 表示全表扫描
# 图二 type 是ref 表示走了索引


7.6 是否走索引压测
# 1 创建数据库test :create database test charset='utf8';
# 2 导入100w条数据 source t100w.sql
# 3 执行:模仿100个用户,同时查询select * from test.t_100w where k2='780P',一共执行200次,平均一人两次
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from test.t100w where k2='780P'" engine=innodb --number-of-queries=200 -uroot -verbose
# 4 创建索引再测试:
alter table test.t100w add index idx_name(k2);
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 0.084 seconds
Minimum number of seconds to run all queries: 0.084 seconds
Maximum number of seconds to run all queries: 0.084 seconds
Number of clients running queries: 100
Average number of queries per client: 2
# 5 删除索引再测试
alter table test.t100w drop index idx_name;
Benchmark
Running for engine rbose
Average number of seconds to run all queries: 51.012 seconds
Minimum number of seconds to run all queries: 51.012 seconds
Maximum number of seconds to run all queries: 51.012 seconds
Number of clients running queries: 100
Average number of queries per client: 2
八 执行计划获取及分析
8.0 介绍
(1)
获取到的是优化器选择完成的,他认为代价最小的执行计划.
作用: 语句执行前,先看执行计划信息,可以有效的防止性能较差的语句带来的性能问题.
如果业务中出现了慢语句,我们也需要借助此命令进行语句的评估,分析优化方案。
(2) select 获取数据的方法
1. 全表扫描(应当尽量避免,因为性能低)
2. 索引扫描
3. 获取不到数据
8.1 执行计划获取
获取优化器选择后的执行计划
方式一:desc +sql 语句
desc select * from test.t100w;
方式二:explain +sel语句
explain select * from test.t100w;
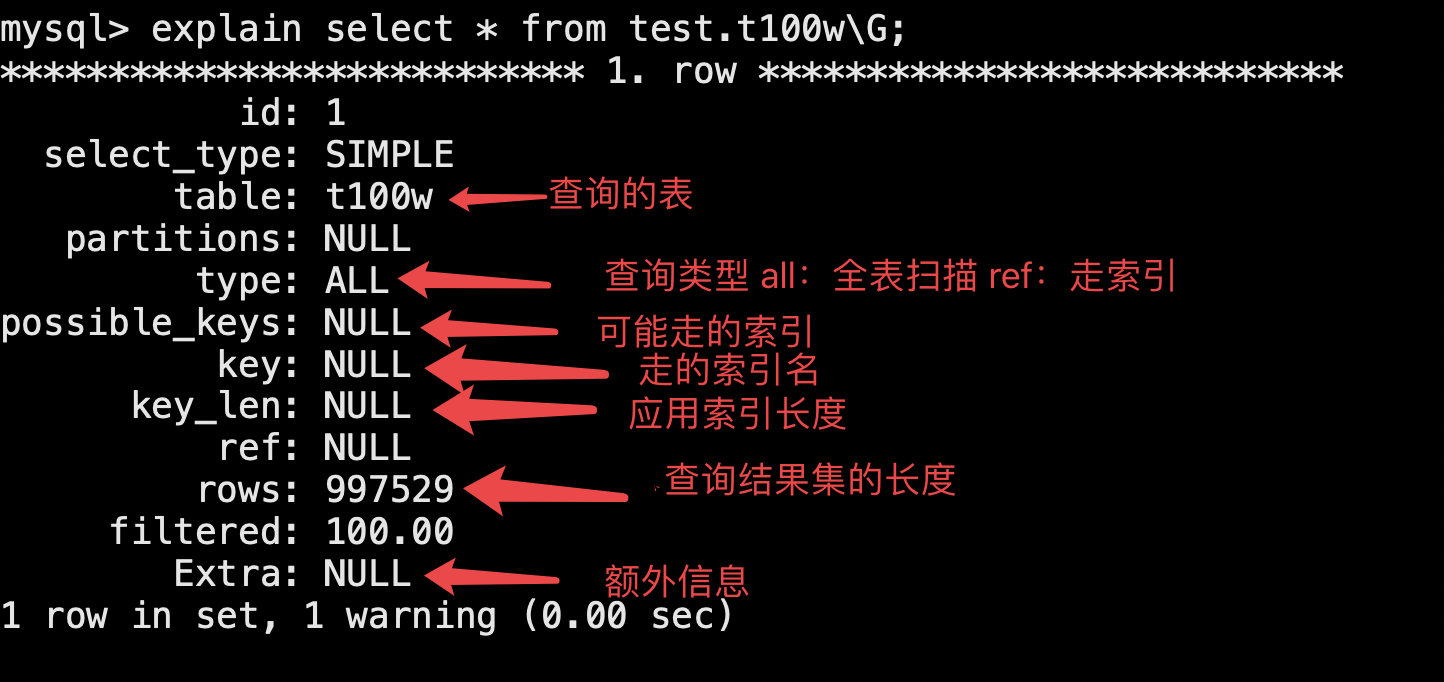
explain select * from test.t100w\G;
8.2 执行计划分析
8.2.0 重点关注的信息
table: city # 查询操作的表 (后期可能多表关联查询)
type:ref # 查询类型 (全表,索引扫描)
possible_keys: CountryCode,idx_co_po # 可能会走的索引,执行计划会有多种方案
key: CountryCode # 真正走的索引名字,最后优化器选择的
key_len:null # 索引覆盖长度
rows:997529 #查询结果集的长度,此次查询需要扫描的行数
Extra: Using index condition # 额外信息
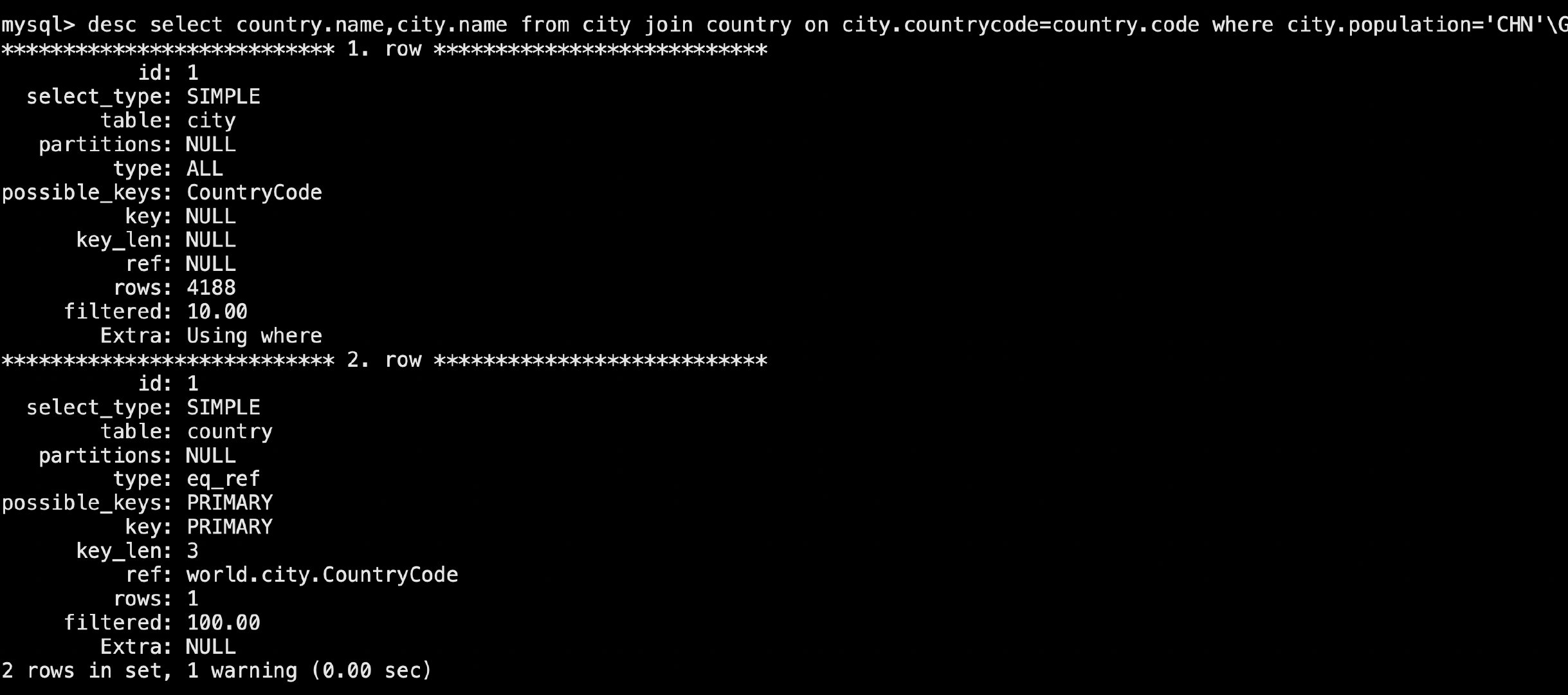
desc select country.name,city.name from city join country on city.countrycode=country.code where city.population='CHN'\G;
# city 表没有走索引,type 是all
# 优化一下,给populations字段加索引
alter table city add index idx(population);
# 再看,就走索引了
8.2.1 type详解
8.2.1.1 简介
type类型:all,index , range ,ref, eq_ref,const(system)
all:是全表扫描
index ,range ,ref,eq_ref,const(system)是索引扫描,但是顺序从左向右,效率依次提高
8.2.1.2 ALL
######## 全表扫描的例子########
#1 ALL : 全表扫描,不走索引
desc select * from city;
desc select * from city where 1=1;
desc select * from city where countrycode not in ('chn','usa'); # not in不走索引,in走索引
desc select * from city where countrycode like '%ch%'; # like前后都加%,不走索引,构建索引要排序,前面是百分号,没法排序,遵循最左前缀,左侧要确定
desc select * from city where countrycode !='usa'; # 不等于也会全文扫描
8.2.1.3 index
######## 索引扫描的例子########
# index < range <ref <eq_ref<const(system)
# 2 index:全索引扫描
desc select countrycode from world.city; # countrycode有索引,但是需要扫描整棵索引树
8.2.1.4 range
# 3 range:索引范围查询
辅助索引> < >= <= LIKE IN OR
主键 <> NOT IN
desc select * from city where id <10;
desc select * from city where countrycode like 'CH%';
desc select * from city where countrycode in ('CHN','USA');
# 改写后,变成ref
desc select * from city where countrycode ='CHN'
union all
select * from city where countrycode ='USA';
# 特殊情况,主键的不等于,not in 是range类型
desc select * from city where id !=10;# 做成了<10 and >10
desc select * from city where id not in (10,20);
8.2.1.5 ref
# 辅助索引等值查询 name='er'的情况
desc select * from city where countrycode ='CHN'
8.2.1.6 eq_ref
# 多表连接中,非驱动表连接条件是主键或唯一键
# A join B on A.xx=B.yy
desc select country.name,city.name from city join country on city.countrycode=country.code where city.population='CHN'\G;
# 非驱动表使用了主键索引
8.2.1.7 const
唯一索引的等值查询
DESC SELECT * FROM city WHERE id=10;
8.2.2 其他字段解释
8.2.2.1 possible_keys和key
possible_keys:可能会走的索引,所有和此次查询有关的索引
key:此次查询选择的索引
8.2.2.2 key_len
# 联合索引覆盖长度
# 对于联合索引:index(a,b,c),我们希望将来的查询对联合索引用的越充分越好
# key_len 可以帮我们判断,此次查询走了联合索引的几部分
# key_len计算:
select * from t1 where a = and b= or c=
上面语句完全使用联合索引
key_len=a长度+b长度+c长度
##### 数字类型
not null约束 没有not null 约束
tinyint 1 1+1
int 4 4+1
bigint 8 8+1
# key_len:
a列 int类型 not null ----》长度为4
a列 int类型 没有非空约束 ----》长度为5
#### 字符类型:utf8 ----》一个字符最大占3个字节
not null约束 没有not null 约束
char(10) 3*10 3*10+1
varchar(10) 3*10+2 3*10+2+1
# 选择此列最大字符长度
b列 char(10) not null ---》30
b列 char(10) 没有非空约束 ---》31
c列 varchar(10) not null ---》32
c列 varchar(10) 没有非空约 ---》33
# 假设是utf8mb4格式,该如何算?
create table t1(
a int not null, 4
b int, 5
c char(10) not null, 40
d varchar(10) 43
)charset =utf8mb4
# index(a,b,c,d)
# 问:查询中完全覆盖到4列索引,key_len是多少? 92
# 测试:新建表,建立4列索引,
desc select * from t1 where a =1 and b=2 or c='a' and d='c'; 92
desc select * from t1 where a =1 ; 4
# 通过数字可以判断是否完全走了索引
8.2.2.3 rows
# 评估查询需要扫描的数据行数
8.2.2.4 extra
# 如果出现useing filesort:表示此次查询使用到了文件排序,说明在查询中的排序操作(查询语句中有如下语句,索引应用的不是特别合理):order by,group by ,distinct...
DESC SELECT * FROM city WHERE countrycode='CHN' ORDER BY population
# 可以看到使用了额外的排序
# 需要将countrycode和population建立联合索引,再次查询就没有useing filesort了,在索引里排好序了
结论:
1.当我们看到执行计划extra位置出现filesort,说明由文件排序出现
2.观察需要排序(ORDER BY,GROUP BY ,DISTINCT )的条件,有没有索引
3. 根据子句的执行顺序,去创建联合索引
8.2.3 explain(desc)使用场景(面试题)
题目意思: 我们公司业务慢,请你从数据库的角度分析原因
1.mysql出现性能问题,我总结有两种情况:
(1)应急性的慢:突然夯住
应急情况:数据库hang(卡了,资源耗尽)
处理过程:
1.show processlist; 获取到导致数据库hang的语句
2. explain 分析SQL的执行计划,有没有走索引,索引的类型情况
3. 建索引,改语句
(2)一段时间慢(持续性的):
(1)记录慢日志slowlog,分析slowlog
(2)explain 分析SQL的执行计划,有没有走索引,索引的类型情况
(3)建索引,改语句
九 索引应用规范
业务
1.产品的功能
2.用户的行为
"热"查询语句 --->较慢--->slowlog
"热"数据
9.1 建立索引的原则(DBA运维规范)
9.1.0 说明
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。那么索引设计原则又是怎样的?
9.1.1 (必须的) 建表时一定要有主键,一般是个无关列
一定要有主键,数字列最好,无关业务
9.1.2 选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。
如果使用姓名的话,可能存在同名现象,从而降低查询速度。
优化方案:
(1) 如果非得使用重复值较多的列作为查询条件(例如:男女),可以将表逻辑拆分
(2) 可以将此列和其他的查询类,做联和索引
(3) 联合索引,要把重复值少的放在最左侧
select count(*) from world.city;
select count(distinct countrycode) from world.city;
select count(distinct countrycode,population ) from world.city;
9.1.3(必须的) 为经常需要where 、ORDER BY、GROUP BY,join on等操作的字段建立索引
排序操作会浪费很多时间。
where A B C ----》 A B C
in
where A group by B order by C
A,B,C
如果为其建立索引,优化查询
注:如果经常作为条件的列,重复值特别多,可以建立联合索引。
9.1.4 尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引,减少索引树高度
9.1.5 限制索引的数目
索引的数目不是越多越好。
可能会产生的问题:
(1) 每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
(2) 修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
(3) 优化器的负担会很重,有可能会影响到优化器的选择.
percona-toolkit中有个工具,专门分析索引是否有用
9.1.6 删除不再使用或者很少使用的索引(percona toolkit)
pt-duplicate-key-checker
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
9.1.7 大表加索引,要在业务不繁忙期间操作
9.1.8 尽量少在经常更新值的列上建索引
9.1.9 建索引原则
(1) 必须要有主键,如果没有可以做为主键条件的列,创建无关列
(2) 经常做为where条件列 order by group by join on, distinct 的条件(业务:产品功能+用户行为)
(3) 最好使用唯一值多的列作为索引,如果索引列重复值较多,可以考虑使用联合索引
(4) 列值长度较长的索引列,我们建议使用前缀索引.
(5) 降低索引条目,一方面不要创建没用索引,不常使用的索引清理,percona toolkit(xxxxx)
(6) 索引维护要避开业务繁忙期
9.2 不走索引的情况(开发规范)
9.2.1 没有查询条件,或者查询条件没有建立索引
select * from tab; 全表扫描。
select * from tab where 1=1;
在业务数据库中,特别是数据量比较大的表。
是没有全表扫描这种需求。
1、对用户查看是非常痛苦的。
2、对服务器来讲毁灭性的。
(1)
select * from tab;
SQL改写成以下语句:
select * from tab order by price limit 10 ; 需要在price列上建立索引
(2)
select * from tab where name='zhangsan' name列没有索引
改:
1、换成有索引的列作为查询条件
2、将name列建立索引
9.2.2 查询结果集是原表中的大部分数据,应该是25%以上。
查询的结果集,超过了总数行数25%,优化器觉得就没有必要走索引了。
假如:tab表 id,name id:1-100w ,id列有(辅助)索引
select * from tab where id>500000;
如果业务允许,可以使用limit控制。
怎么改写 ?
结合业务判断,有没有更好的方式。如果没有更好的改写方案
尽量不要在mysql存放这个数据了。放到redis里面。
9.2.3 索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,统计信息不准确,过旧,有可能会出现索引失效。
一般是删除重建
# 统计信息
现象:
有一条select语句平常查询时很快,突然有一天很慢,会是什么原因
select? --->索引失效,,统计数据不真实,大量修改,删除性的操作
DML ? --->锁冲突
解决:
重建索引,优化表
# 统计信息放在了mysql数据库的,数据改了,记录的统计信息不真实,会导致索引失效
innodb_index_stats
innodb_table_stats
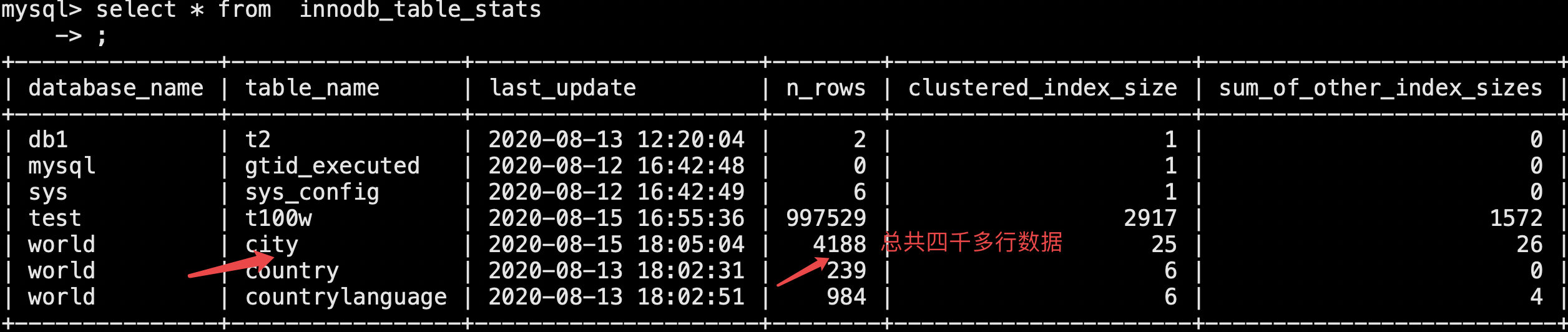
select * from innodb_table_stats;
# 有哪个库,哪个表,上次更新时间,数据行数,聚簇索引大小,辅助索引大小等
假设我们删除一部分数据,这个记录不是实时更新的
delete from city where id=100;
# 再查看,行数不变,可以使用如下两条命令:优化表
optimize table world.city;
alter table world.city engine=innodb;
# 再查看就更新了
9.2.4 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
例子:
错误的例子:select * from test where id-1=9;
正确的例子:select * from test where id=10;
算术运算
函数运算
子查询
9.2.5 隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
这样会导致索引失效. 错误的例子:
# 创建表
create table tab(id int,telnum char(11));
# 给telnum增加索引
mysql> alter table tab add index inx_tel(telnum);
# 查看
mysql> desc tab;
# 查询数据
mysql> select * from tab where telnum='1333333';
mysql> select * from tab where telnum=1333333;
# 分析
# 走索引
mysql> explain select * from tab where telnum='1333333';
# 不走索引(出现了隐士转换,做了函数运算)
mysql> explain select * from tab where telnum=1555555;
9.2.6 <> ,not in 不走索引(辅助索引)
# <> ,not in 不走索引,但是对于主键走range索引
EXPLAIN SELECT * FROM teltab WHERE telnum <> '110';
EXPLAIN SELECT * FROM teltab WHERE telnum NOT IN ('110','119');
mysql> select * from tab where telnum <> '1555555';
mysql> explain select * from tab where telnum <> '1555555';
单独的>,<,in 有可能走,也有可能不走,和结果集有关(当查询结果集超过25%,也会不走索引),尽量结合业务添加limit
or或in 尽量改成union
EXPLAIN SELECT * FROM teltab WHERE telnum IN ('110','119');
改写成:
EXPLAIN SELECT * FROM teltab WHERE telnum='110'
UNION ALL
SELECT * FROM teltab WHERE telnum='119'
9.2.7 like “%_” 百分号在最前面不走
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%' 走range索引扫描
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110' 不走索引
%linux%类的搜索需求,可以使用elasticsearch+mongodb 专门做搜索服务的数据库产品
十扩展:优化器针对索引的算法
10.1 mysql索引的自优化-AHI
# 自适应哈希索引:AHI,自动统计索引页使用情况,内存中放在buffer pool中,可能会在内存回收的情况下,把经常使用的索引页回收(置换)掉(这是我们不希望看到的),我们需要把热的索引页,生成一个hash表的类型,存到AHI中
# 自带的,自优化能力
# 作用:自动评估 ’热‘的内存索引page,生成hash索引表,帮助innodb快速读取索引页,加速索引读取速度
10.2 mysql索引的自优化-Change buffer
比如insert,update,delete 数据
对于聚簇索引会立即更新
对于辅助索引,不是实时更新
在innodb内存结构中,加入了insert buffer(会话),现在的版本叫change buffer
change buffer的功能是临时缓冲辅助索引需要的数据更新
当我们要查询新insert的数据,会在内存中进行merge(合并)操作,此时辅助索引就是最新的
每个会话都分一个,可以调整,但是不能调太大
以上是(AHI,Change buffer)自优化能力,不需要单独配置,下面的是优化算法
show variables like '%switch%';
select @@optimizer_switch\G;
# 如下算法
index_merge=on,
index_merge_union=on,
index_merge_sort_union=on,
index_merge_intersection=on,
engine_condition_pushdown=on,
index_condition_pushdown=on, # 索引下推
mrr=on,
mrr_cost_based=on, #
block_nested_loop=on, #
batched_key_access=off, #
materialization=on,
semijoin=on,
loosescan=on,
firstmatch=on,
duplicateweedout=on,
subquery_materialization_cost_based=on,
use_index_extensions=on,
condition_fanout_filter=on,
derived_merge=on
# 如何修改?
方式一:
配置文件my.cnf
方式二:
set global optimizer_switch='index_condition_pushdown=on,mrr_cost_based=on';
set global optimizer_switch='batched_key_access=on';
# 重启会话,退出重连
方式三:单独给某个语句开
BKA hins方式
https://dev.mysql.com/doc/relnotes/mysql/5.7/en/news-5-7-7.html
SELECT /*+ NO_RANGE_OPTIMIZATION(t3 PRIMARY, f2_idx) */ f1
FROM t3 WHERE f1 > 30 AND f1 < 33;
SELECT /*+ BKA(t1) NO_BKA(t2) */ * FROM t1 INNER JOIN t2 WHERE ...;
SELECT /*+ NO_ICP(t1, t2) */ * FROM t1 INNER JOIN t2 WHERE ...;
EXPLAIN SELECT /*+ NO_ICP(t1) */ * FROM t1 WHERE ...;
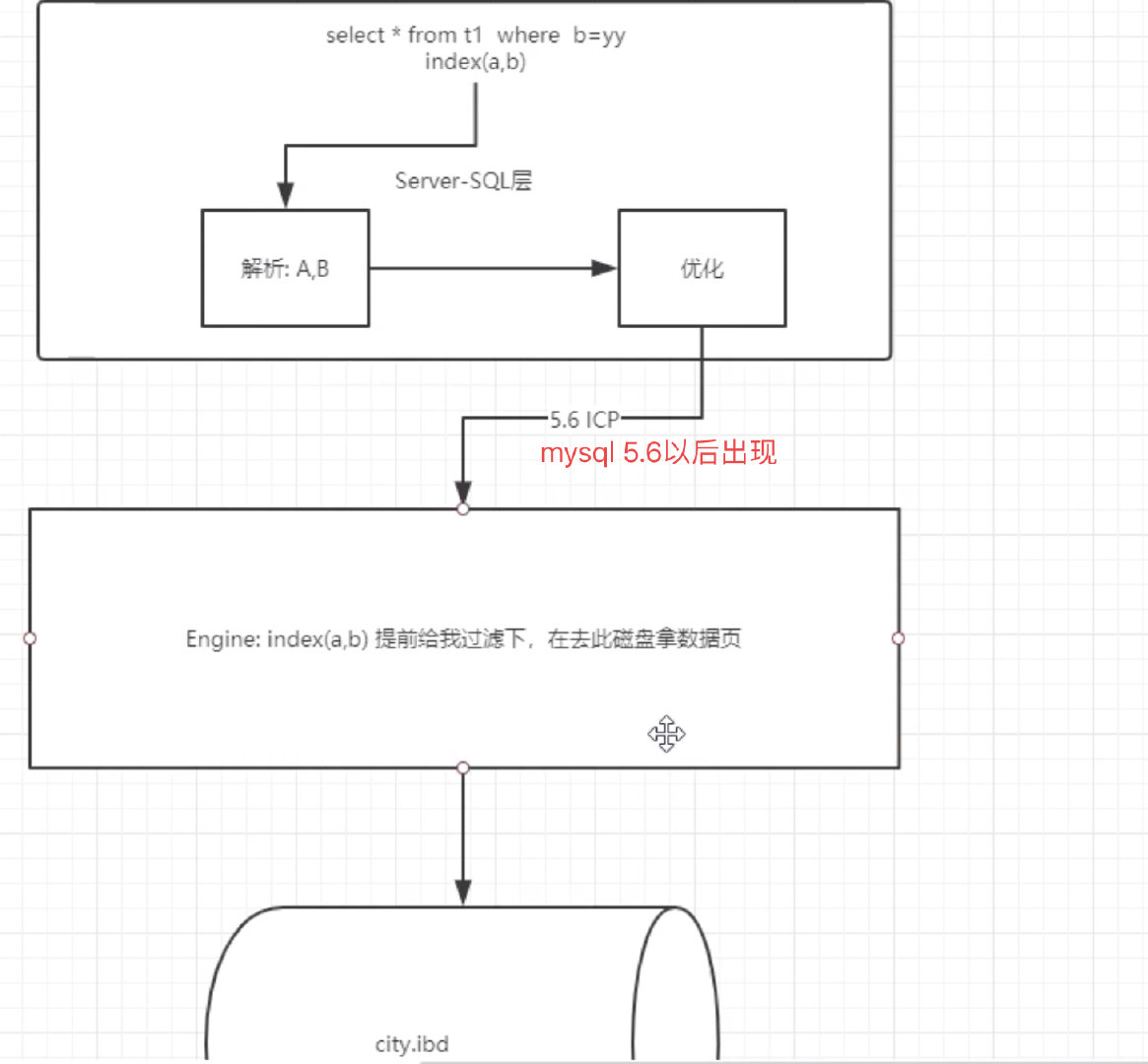
10.3 ICP:索引下推
# 原理:
select 查询语句在sql层解析后,由优化器选择好方案,进入引擎层后,再由引擎层进行一次过滤,过滤好后再访问硬盘的页的数据
ICP是在引擎层又进行一次过滤,把索引优化的能力,下推到了引擎层
# 作用:
减少无关数据页的扫描,最大程度使用索引,解决了联合索引只能部分应用的情况
将不走索引的条件,在engine层取出数据之前做二次过滤
过滤掉一些无关数据
### 举个例子
假设有索引:index(a,b,c) 、
查询数据:select * from t1 where a= and c =
正常是在server层通过优化器优化,只能走a的索引,所以查a的数据走了索引,查c的数据还需要再全表扫描,这样导致扫描数据量很大(a走索引,c在a的结果集上走全表)
通过ICP,把索引优化下推到引擎层,在引擎层再做一次过滤,得到更少量的数据,从而提高io速度(本来是要拿出满足a条件的数据,然后在结果集上过滤c,现在拿出a的数据集之前再做一次过滤,数据集更少,然后再过滤c条件)
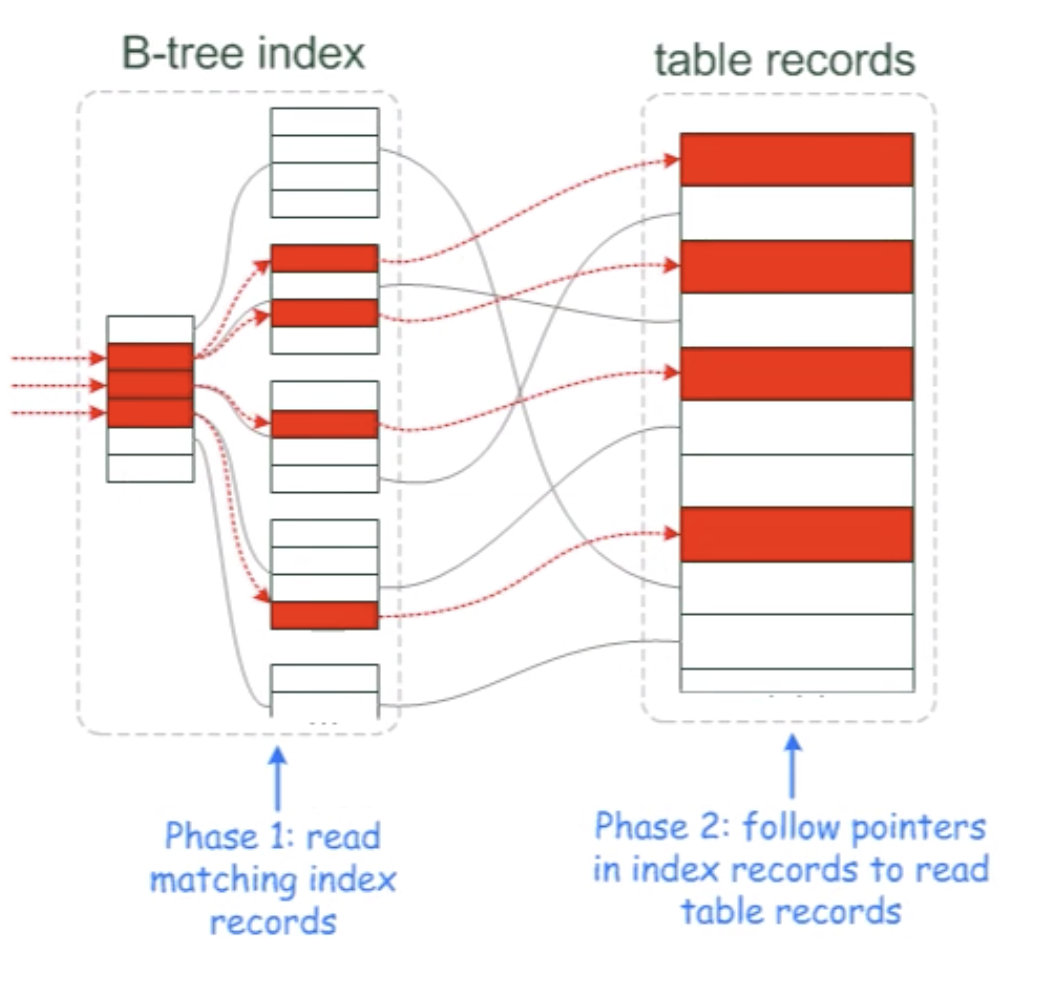
没有ICP的情况
server 层在做完索引优化以后,需要去磁盘上取4个数据页(红色的),但是实际上满足条件的只有一个,没有icp会多余读取3个没用的数据页
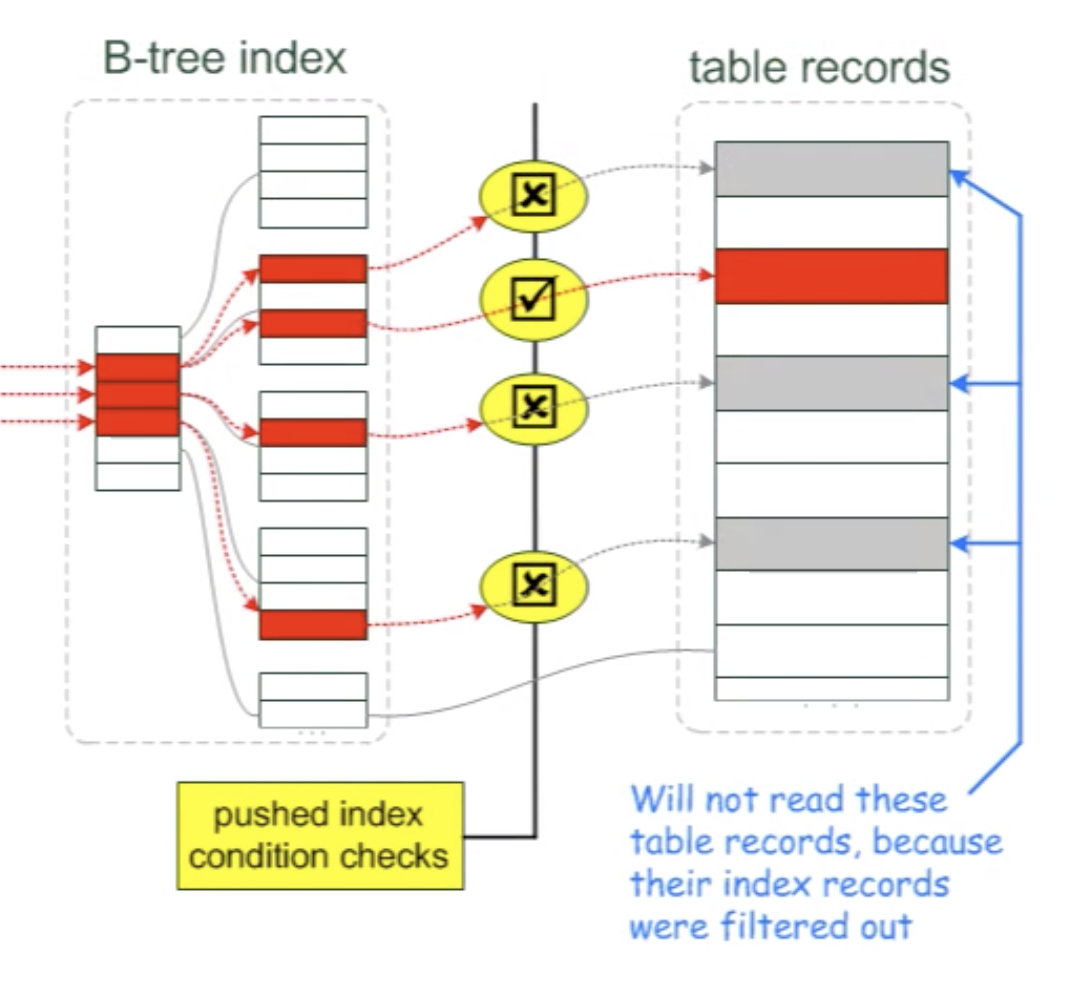
有ICP的情况
server 层在做完索引优化以后,需要去磁盘上取4个数据页(红色的),但是实际上满足条件的只有一个,到达engin层后,再做一次过滤,发现满足条件的只有一个页,所以,只取有用的那个页(其实就是引擎层又加了一个判断,减少无关数据页的扫描)
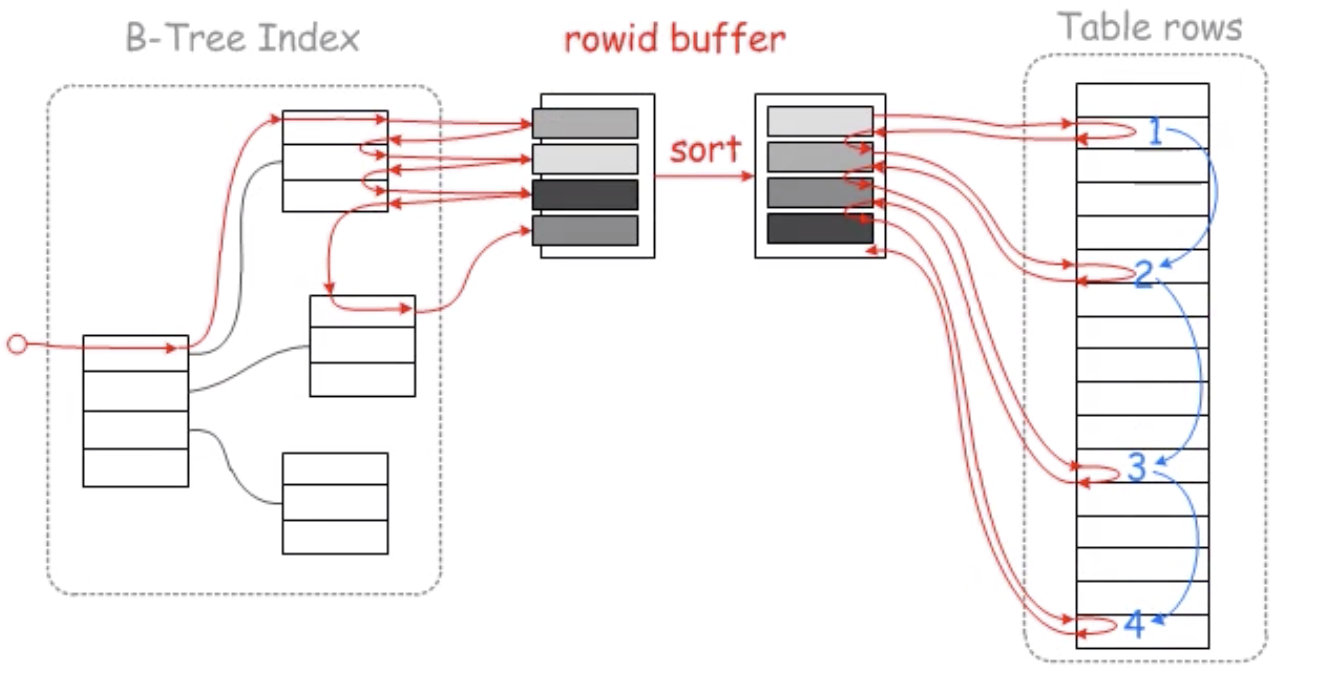
10.4 MRR-multi range read
mrr=on, # 开启
mrr_cost_based=on, #关闭,是否通过cost base的方式来启用MRR,由系统判断是否值得,我们关闭
set global optimizer_switch='mrr=on,mrr_cost_based=off';
# 原理
范围查询 (大于,小于)
like查询
有重复值
从辅助索引得到一个id值就要回表一次
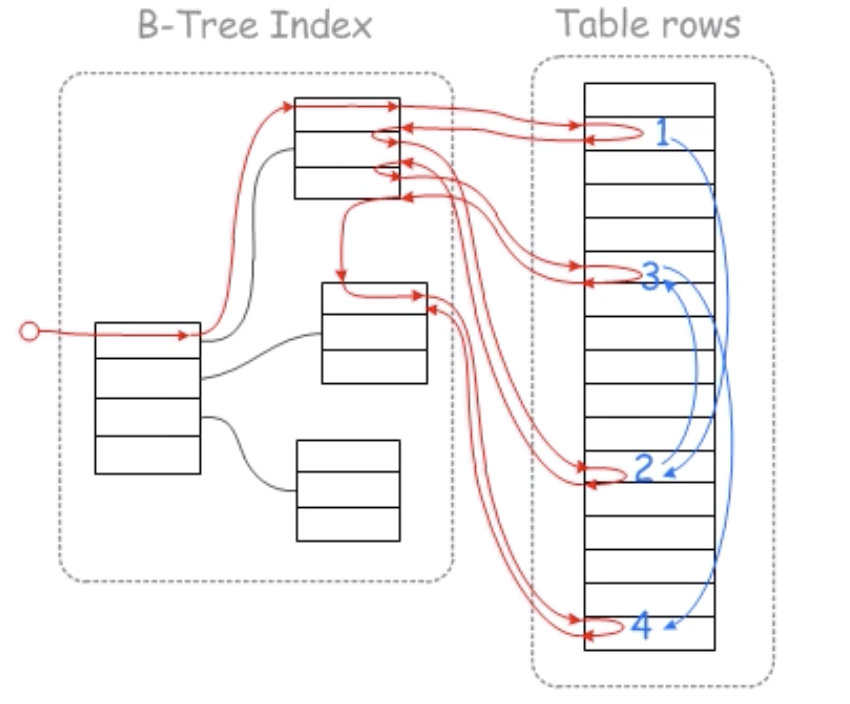
在回表之前,先把id预存一下(缓冲区),排一下序(sort id),最后一次性回表(这样有顺序的就可以通过B+树的neighbour直接顺序取)
mrr之前
mrr之后
10.5 SNLJ
10.6 BNLJ
10.7 BKA
十一 问题汇总
11.1 怎样减少回表
11.2 更新数据时,会对索引有影响吗,数据的变化索引实时更新吗?
insert delete一行数据
聚簇索引会立即更新
辅助索引不是实时更新
update 一行数据
看是不是更新辅助索引字段(聚簇索引字段不会改),辅助索引不会立即变化
# 补充
在InnoDB内存结构中(内存空间),加入了insert buffer(会话缓冲区),现在叫change buffer
原来主要针对insert操作,现在修改插入删除都会走
1 聚簇索引,辅助索引,数据都在磁盘上存,innodb 存到ibd(表空间文件:有段,区,页)文件中
2 当去查询select * from t1 where name='zs',会把辅助索引的数据页加载到内存(buffer pool)
3 回表,需要聚簇索引,也加载到内存中
4 新录入数据,会更新聚簇索引,立即更新到磁盘
5 对于辅助索引,不是立即更新,先把变更放到change buffer(独立内存区域)中,这样磁盘上的辅助索引是旧数据
6 假设要读新插入的一行,mysql会在内存中把change buffer中的变更的辅助索引和原来内存中的辅助索引merge(合并)一下,这个过程叫index merge(在内存中合并到一起)
7 这样搜新插入的数据,是能搜到的
8 辅助索引没有实时更新,减少了更新的频次
9 当有查询操作查询这条数据后,辅助索引的数据会落到磁盘上(因为有查询需求)
10 一旦涉及到更新磁盘,就会有一定程度的阻塞
11 每个会话(每个链接上来)都会有一个change buffer,大小可以调,通过调change buffer来优化大量的update和删除等操作
12 当我们要查询新insert的数据,会在内存中将辅助索引合并,这样辅助索引就是最新的了(就是为了减少频繁磁盘更新)
新数据时,会对索引有影响吗,数据的变化索引实时更新吗?
insert delete一行数据
聚簇索引会立即更新
辅助索引不是实时更新
update 一行数据
看是不是更新辅助索引字段(聚簇索引字段不会改),辅助索引不会立即变化
# 补充
在InnoDB内存结构中(内存空间),加入了insert buffer(会话缓冲区),现在叫change buffer
原来主要针对insert操作,现在修改插入删除都会走
1 聚簇索引,辅助索引,数据都在磁盘上存,innodb 存到ibd(表空间文件:有段,区,页)文件中
2 当去查询select * from t1 where name='zs',会把辅助索引的数据页加载到内存(buffer pool)
3 回表,需要聚簇索引,也加载到内存中
4 新录入数据,会更新聚簇索引,立即更新到磁盘
5 对于辅助索引,不是立即更新,先把变更放到change buffer(独立内存区域)中,这样磁盘上的辅助索引是旧数据
6 假设要读新插入的一行,mysql会在内存中把change buffer中的变更的辅助索引和原来内存中的辅助索引merge(合并)一下,这个过程叫index merge(在内存中合并到一起)
7 这样搜新插入的数据,是能搜到的
8 辅助索引没有实时更新,减少了更新的频次
9 当有查询操作查询这条数据后,辅助索引的数据会落到磁盘上(因为有查询需求)
10 一旦涉及到更新磁盘,就会有一定程度的阻塞
11 每个会话(每个链接上来)都会有一个change buffer,大小可以调,通过调change buffer来优化大量的update和删除等操作
12 当我们要查询新insert的数据,会在内存中将辅助索引合并,这样辅助索引就是最新的了(就是为了减少频繁磁盘更新)
MySQL系列之——索引作用、索引的种类、B树、聚簇索引构建B树、辅助索引(S)构建B+树、辅助索引细分、索引树的高度、索引的基本管理、执行计划获取及分析、索引应用规范、优化器针对索引、问题汇总的更多相关文章
- 0104探究MySQL优化器对索引和JOIN顺序的选择
转自http://www.jb51.net/article/67007.htm,感谢博主 本文通过一个案例来看看MySQL优化器如何选择索引和JOIN顺序.表结构和数据准备参考本文最后部分" ...
- Explain执行计划与索引优化实践
一.何为explain执行计划? 使用explain关键字可以模拟优化器执行SQL语句,从而知道MySQL是如何使用索引来处理你的SQL查询语句以及连接表,可以分析查询语句或是结构的性能瓶颈,帮助我们 ...
- MySQL优化之执行计划
前言 研究SQL性能问题,其实本质就是优化索引,而优化索引,一个非常重要的工具就是执行计划(explain),它可以模拟SQL优化器执行SQL语句,从而让开发人员知道自己编写的SQL的运行情况. 执行 ...
- 五分钟,让你明白MySQL是怎么选择索引《死磕MySQL系列 六》
系列文章 二.一生挚友redo log.binlog<死磕MySQL系列 二> 三.MySQL强人"锁"难<死磕MySQL系列 三> 四.S 锁与 X 锁的 ...
- 《Mysql - 优化器是如何选择索引的?》
一:概念 - 在 索引建立之后,一条语句可能会命中多个索引,这时,索引的选择,就会交由 优化器 来选择合适的索引. - 优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句. 二: ...
- Mongodb 3 查询优化(语句优化、建索引)
一.explain(),语句分析工具 MongoDB 3.0之后,explain的返回与使用方法与之前版本有了很大的变化,介于3.0之后的优秀特色和我们目前所使用给的是3.0.7版本,本文仅针对Mon ...
- SQL Server索引的执行计划
如何知道索引有问题,最直接的方法就是查看执行计划.通过执行计划,可以回答表上的索引是否被使用的问题. (1)包含索引:避免书签查找 常见的索引方面的性能问题就是书签查找,书签查找分为RID查找和键值查 ...
- mysql之优化器、执行计划、简单优化
mysql之优化器.执行计划.简单优化 2018-12-12 15:11 烟雨楼人 阅读(794) 评论(0) 编辑 收藏 引用连接: https://blog.csdn.net/DrDanger/a ...
- 如何干涉MySQL优化器使用hash join
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. GreatSQL是MySQL的国产分支版本,使用上与MySQL一致. 前言 实验 总结 前言 数据库的优化器相当于人类的大 ...
- MySQL优化器join顺序
前一篇介绍了cost的计算方法,下面测试一下两表关联的查询: 测试用例 CREATE TABLE `xpchild` ( `id` int(11) NOT NULL, `name` varchar(1 ...
随机推荐
- 了解基于模型的元学习:Learning to Learn优化策略和Meta-Learner LSTM
摘要:本文主要为大家讲解基于模型的元学习中的Learning to Learn优化策略和Meta-Learner LSTM. 本文分享自华为云社区<深度学习应用篇-元学习[16]:基于模型的元学 ...
- 深度学习中的循环神经网络”在Transformer中的应用
目录 深度学习中的"循环神经网络"在Transformer中的应用 背景介绍 文章目的 目标受众 技术原理及概念 基本概念解释 相关技术比较 实现步骤与流程 准备工作:环境配置与依 ...
- 【FAQ】关于CP反馈的联运应用的常见结算问题小结
问题一:为什么在"我的账户">>"收益"里面的金额和支付报表中的金额对不上 ? 关于联运类应用付费产品在华为平台上结算问题,您可以详细参考一下&qu ...
- sharding-jdbc分库连接数优化
一.背景: 配运平台组的快递订单履约中心(cp-eofc)及物流平台履约中心(jdl-uep-ofc)系统都使用了ShardingSphere生态的sharding-jdbc作为分库分表中间件, 整个 ...
- 安装Hadoop单节点伪分布式集群
目录 安装Hadoop单节点伪分布式集群 系统准备 开启SSH 安装JDK 安装Hadoop 下载 准备启动 伪分布式模式安装 配置 配饰SSH免密登录本机 测试启动 单节点安装YARN 伪分布式集群 ...
- Centos使用keepalived配置MySQL双主热备集群
目录 安装MySQL 下载安装包 卸载mariadb-lib 安装依赖 安装gcc 安装perl 永久关闭selinux 安装 配置 创建mysql数据库管理用户和组 创建数据目录 修改my.cnf配 ...
- 【Mybatis】动态SQL
目录 动态SQL if语句 动态SQL if+where语句 动态SQL if+set语句 动态SQL choose(when,otherwise)语句 动态SQL trim语句 动态SQL SQL片 ...
- 在行情一般的情况下,就说说23级应届生如何找java工作
Java应届生找工作,不能单靠背面试题,更不能在简历中堆砌和找工作关系不大的校园实践经历,而是更要在面试中能证明自己的java相关商业项目经验.其实不少应届生Java求职者不是说没真实Java项目经验 ...
- 自学前端-HTML5+CSS-综合案例一-热词
综合案例一-热词 目录 综合案例一-热词 1.设计需求 2.设计所需标签和CSS样式 3.设计具体步骤 4.遇到的问题 设计图如下 1.设计需求 ①需要鼠标放上去有显示透明 ②需要点击后跳转到相应页面 ...
- 统一观测丨使用 Prometheus 监控 Cassandra 数据库最佳实践
作者:元格 本篇内容主要包括四部分:Cassandra 概览介绍.常见关键指标解读.常见告警规则解读.如何通过 Prometheus 建立相应监控体系. Cassandra 简介 Cassandra ...