HIVE-执行distribute by时报错的解决过程---之如何分析hive执行的错误并解决
在执行一条HIVE语句的时候报了以下错误,重新检查了所有步骤,重启所有服务,发现没有问题。 但发现一个有趣的事情
1,select sno,sname,sex,sage,sdept from student可以正常执行
2,sno,sname,sex,sage,sdept from student distribute by(sname) 不可以执行报错
在/tmp/用户名下查看系统hive.log,发现信息并不多。网上有其他方法可以查看更多日志,但太麻烦,速度很慢所以就没尝试。
select sno,sname,sex,sage,sdept from student distribute by(sname)
> ;
Query ID = root_20171108131253_43a3d026-0e04-44f2-8312-c92d1c0b6125
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1510116443491_0001, Tracking URL = http://server71:8088/proxy/application_1510116443491_0001/
Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1510116443491_0001
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2017-11-08 13:13:34,560 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1510116443491_0001 with errors
Error during job, obtaining debugging information...
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
原因分析
上面1,2的区别表明了一件事情,单纯的select语句是不通过mapreduce的,加上distribute by后调用了yarn程序。打开8088端口的yarn端口
可怕的是没有错误信息,非常高兴看到了下面错误,表明了两件事。
1,刚才的sql用到了yarn,2,在使用yarn的时候无法启动container报错。这里需要了解yarn的基本知识。
解决方法:百度后得知这个是因为namenode和datanode时间不一致导致。简单说就是几台虚拟机的时间不一致。
用date查看四台机器,果然不一致。可能是因为某台曾经还原过快照,所以时间不一致。
org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
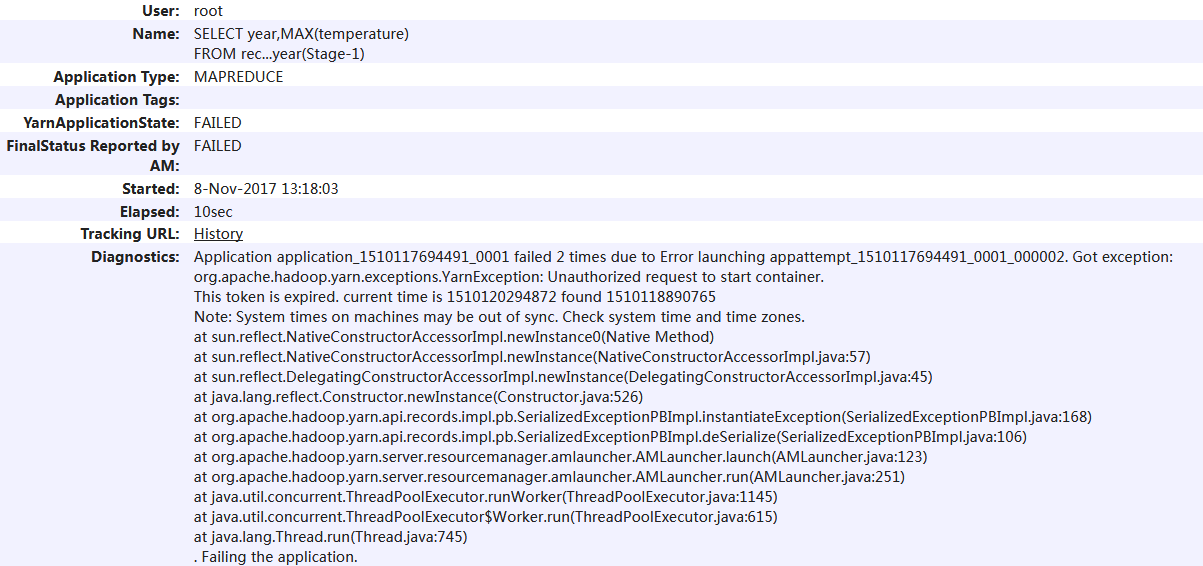
解决过程
虽然知道了原因,但还不是很顺利,这也是很多人遇到的问题,我们的问题和其他人虽然是一个问题。但因为环境不同的原因,同样的方法并不好用。
首先,我尝试了ntpdate pool.ntp.org,但这个命令无效,报了name server问题,后来明白我电脑不联网,而刚才命令是同步网络时间的。所以我需要找到直接修改时间的方法
最后成功修改我的机器的时间的命令是下面的
date -s 15:55:33 (15点55分33秒) 时间可以自己修改
修改时间的其他方法,大家可以都尝试一下,问题关键在于修改了机器时间,把问题简化就是解决问题的基本步骤。
http://www.xitongzhijia.net/xtjc/20150219/38844.html
以上,希望对大家找到解决问题的思路有所帮助,问题有时候会让我们崩溃和绝望。但总是有解决办法的,比如终极方法:重装系统
HIVE-执行distribute by时报错的解决过程---之如何分析hive执行的错误并解决的更多相关文章
- python3.x执行post请求时报错“POST data should be bytes or an iterable of bytes...”的解决方法
使用python3.5.1执行post请求时,一直报错"POST data should be bytes or an iterable of bytes. It cannot be of ...
- Laravel5.5执行 npm run dev时报错,提示cross-env找不到(not found)的解决办法
Laravel 5.4 Mix & Laravel5.5执行 npm run dev时报错,提示cross-env找不到(not found)的解决办法 首先进入package.json文 ...
- 执行rpm -ivh 时报错:error rpmdb BDB0113 Threadprocess 11690140458095421504 failed
执行rpm -ivh 时报错:error rpmdb BDB0113 Threadprocess 11690140458095421504 failed 1.具体报错如下: [root@heyong ...
- (转)Linux安装SwfTools-0.9.2安装事,在执行make install时报错
系统:CentOS6.5 安装SwfTools-0.9.2的时候,在执行make install时报错, rm -f /usr/local/share/swftools/swfs/default_vi ...
- svn执行clean up 操作时报错 "Previous operation has not finished; run 'cleanup' if it was interrupted"解决如下!
今天在项目中更新的时候,突然间爆了一个svn的这个错误,当时提示我去clean up操作,结果我执行clean up操作时候,还是报错,后来坚持出来,是因为ios项目中的一个图标出了问题,使svn进入 ...
- hive 使用where条件报错 java.lang.NoSuchMethodError: org.apache.hadoop.hive.ql.ppd.ExprWalkerInfo.getConvertedNode
hadoop 版本 2.6.0 hive版本 1.1.1 错误: java.lang.NoSuchMethodError: org.apache.hadoop.hive.ql.ppd.ExprWalk ...
- 伪分布模式下执行wordcount实例时报错解决办法
问题1.不能分配内存,错误提示如下: FAILEDjava.lang.RuntimeException: Error while running command to get file permiss ...
- 安装redis 执行make命令时报错解决方法
一.未安装GCC 解决方法:执行yum install gcc-c++命令安装GCC,完成后再次执行make命令 yum install gcc-c++ Linux无法连接网络 http://www. ...
- RobotFramework+Appium 升级Appium v1.10.0后,执行click element时报错:InvalidSelectorException: Message: Locator Strategy 'css selector' is not supported for this session,解决办法
报错信息如下: debug] [35m[XCUITest][39m Connection to WDA timed out[debug] [35m[XCUITest][39m Connection t ...
随机推荐
- 学好 Python 的 11 个优秀资源
Python是目前最流行.最易学最强大的编程语言之一,无论你是新手还是老鸟,无论是用于机器学习还是web开发(Pinterest就是案例),Python都是一件利器.此外,Python不但人气日益高涨 ...
- 【HackerRank】 Find Digits
Find Digits Problem Statement Given a number you have to print how many digits in that number exactl ...
- ES6 随记(1)-- let 与 const
1. const(声明一个只读的常量) 这个是很好理解的,且声明时就必须赋值而不能以后再赋,不然会报错. 而个人认为它最大的用处还是在于 {} 和 [] 上,const 保证了它的内存地址(指针)不变 ...
- PHP面向对象之对象和引用
在PHP中对象类型和简单变量类型表现可以说是大相径庭,很多数据类型都要可以在写时进行复制,如当写代码$a=$b时,两个变量因为赋予相同的值而告终.所以需要注意的是,这种情况用在对象时就会完全不同了. ...
- matplotlib模块之子图画法
一般化的子图布局 首先要创建各个子图的坐标轴,传入一个四元列表参数:[x,y,width,height],用来表示这个子图坐标轴原点的x坐标.y坐标,以及宽和高.值得注意的是,这四个值的取值范围都是[ ...
- python的pexpect详解
Pexpect 是一个用来启动子程序并对其进行自动控制的纯 Python 模块. Pexpect 可以用来和像 ssh.ftp.passwd.telnet 等命令行程序进行自动交互.继第一部分< ...
- C#中的转义字符verbatim string
In a verbatim string (a string starting with @"") to escape double quotes you use double q ...
- CentOS/Linux 卸载MATLAB
rm -rf /usr/local/MATLAB/R2012arm /usr/local/bin/matlab /usr/local/bin/mcc /usr/local/bin/mex /usr/l ...
- php-fpm docker 容器 搭建
继续上一篇文章(centos 7 容器的搭建) 下面构建一个php-fpm镜像: dockerfile 文件如下: # # MAINTAINER # DOCKER-VERSION # # Docker ...
- HDU 5925 离散化
东北赛的一道二等奖题 当时学长想了一个dfs的解法并且通过了 那时自己也有一个bfs的解法没有拿出来 一直没有机会和时ji间xing来验证对错 昨天和队友谈离散化的时候想到了 于是用当时的思路做了一下 ...