P1140 相似基因
题目背景
大家都知道,基因可以看作一个碱基对序列。它包含了4种核苷酸,简记作A,C,G,T。生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物。
在一个人类基因工作组的任务中,生物学家研究的是:两个基因的相似程度。因为这个研究对疾病的治疗有着非同寻常的作用。
题目描述
两个基因的相似度的计算方法如下:
对于两个已知基因,例如AGTGATG和GTTAG,将它们的碱基互相对应。当然,中间可以加入一些空碱基-,例如:
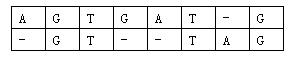
这样,两个基因之间的相似度就可以用碱基之间相似度的总和来描述,碱基之间的相似度如下表所示:
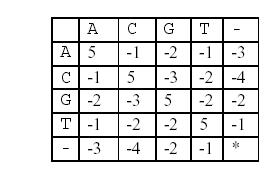
那么相似度就是:(-3)+5+5+(-2)+(-3)+5+(-3)+5=9。因为两个基因的对应方法不唯一,例如又有:
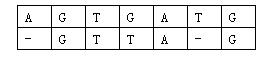
相似度为:(-3)+5+5+(-2)+5+(-1)+5=14。规定两个基因的相似度为所有对应方法中,相似度最大的那个。
输入输出格式
输入格式:
共两行。每行首先是一个整数,表示基因的长度;隔一个空格后是一个基因序列,序列中只含A,C,G,T四个字母。1<=序列的长度<=100。
输出格式:
仅一行,即输入基因的相似度。
输入输出样例
7 AGTGATG
5 GTTAG
14
Solution:
本题是一道比较典型的$DP$。
我们先考虑定义状态,$f[i][j]$表示匹配到了$s1$的$i$位置和$s2$的$j$位置时,能匹配到的最大基因相似度,那么目标状态即$f[n][m]$。
转换碱基,将$A\leftrightarrow 0,C\leftrightarrow 1,G\leftrightarrow 2,T\leftrightarrow 3,-\leftrightarrow 4$,然后把$s1,s2$按上述方法映射为$a,b$,同时建立$w[5][5]$数组,$w[i][j]$表示$i-j$配对的值。
先考虑初始状态,$f[i][j],i\in [1,n],\;j\in [1,m]$初始化为负无穷,因为可以与空碱基匹配,所以初始时$f[i][0]=f[i-1][0]+w[a[i]][4],i\in [1,n]$表示$s1$的每位与空碱基配对的值,$f[0][i]=f[0][i-1]+w[b[i]][4],i\in [1,m]$含义同上。
再考虑中间状态转移,可以发现上一个状态向下一个状态转移时,只有三种情况:
1、$f[i][j]=max(f[i][j],f[i][j-1]+w[b[j]][4])$表示$s1_i$在$s2_j$位置时与空碱基配对;
2、$f[i][j]=max(f[i][j],f[i-1][j]+w[a[i]][4])$表示$s2_j$在$s1_i$位置时与空碱基配对;
3、$f[i][j]=max(f[i][j],f[i-1][j-1]+w[a[i]][b[j]])$表示$s1_i$和$s2_j$配对。
容易想到对于$s1$的每个位置,都可以与$s2$的每个位置匹配一次,所以整体枚举复杂度为$O(nm)$($n$为$s1$长度,$m$为$s2$长度)。
最后输出目标状态$f[n][m]$就$OK$了。
代码:
#include<bits/stdc++.h>
#define il inline
#define ll long long
using namespace std;
const int inf=;
int n,m,f[][],a[],b[];
int w[][]=
{
{,-,-,-,-},
{-,,-,-,-},
{-,-,,-,-},
{-,-,-,,-},
{-,-,-,-,}
};
char s1[],s2[];
il void change(char *s,int *a,int l){
for(int i=;i<=l;i++){
if(s[i]=='A')a[i]=;
if(s[i]=='C')a[i]=;
if(s[i]=='G')a[i]=;
if(s[i]=='T')a[i]=;
}
}
int main()
{
scanf("%d%s%d%s",&n,s1+,&m,s2+);
for(int i=;i<=n;i++)
for(int j=;j<=m;j++)f[i][j]=-inf;
change(s1,a,n),change(s2,b,m);
for(int i=;i<=n;i++)f[i][]=f[i-][]+w[a[i]][];
for(int i=;i<=m;i++)f[][i]=f[][i-]+w[b[i]][];
for(int i=;i<=n;i++)
for(int j=;j<=m;j++){
f[i][j]=max(f[i][j],f[i][j-]+w[b[j]][]);
f[i][j]=max(f[i][j],f[i-][j]+w[a[i]][]);
f[i][j]=max(f[i][j],f[i-][j-]+w[a[i]][b[j]]);
}
cout<<f[n][m];
return ;
}
P1140 相似基因的更多相关文章
- 洛谷P1140 相似基因 (DP)
洛谷P1140 相似基因 题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了44种核苷酸,简记作A,C,G,TA,C,G,T.生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物. ...
- 洛谷 P1140 相似基因(DP)
传送门 https://www.cnblogs.com/violet-acmer/p/9852294.html 参考资料: [1]:https://www.cnblogs.com/real-l/p/9 ...
- 洛谷P1140 相似基因【线性dp】
题目:https://www.luogu.org/problemnew/show/P1140 题意: 给定两串基因串(只包含ATCG),在其中插入任意个‘-’使得他们匹配.(所以一共是5种字符) 这5 ...
- P1140 相似基因(字符串距离,递推)
题目链接: https://www.luogu.org/problemnew/show/P1140 题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了44种核苷酸,简记作A,C,G,TA,C, ...
- P1140 相似基因 (dp)
题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了44种核苷酸,简记作A,C,G,TA,C,G,T.生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物. 在一个人类基因工作组的任务 ...
- P1140 相似基因 这个和之前有一个题目特别像 dp
题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了444种核苷酸,简记作A,C,G,TA,C,G,TA,C,G,T.生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物. 在一个人类 ...
- P1140 相似基因 最长公共子序列
思路 类似于最长公共子序列 把一段基因和另外一段基因匹配 不够长的用空基因替换 #include<bits/stdc++.h> using namespace std; const in ...
- luogu P1140 相似基因
题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了4种核苷酸,简记作A,C,G,T.生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物. 在一个人类基因工作组的任务中,生物学家研究 ...
- P1140 相似基因 (动态规划)
题目背景 大家都知道,基因可以看作一个碱基对序列.它包含了4种核苷酸,简记作A,C,G,T.生物学家正致力于寻找人类基因的功能,以利用于诊断疾病和发明药物. 在一个人类基因工作组的任务中,生物学家研究 ...
随机推荐
- ASP.NET成员资格和角色管理
一.成员资格管理 1.成员资格管理模型 ASP.NET提供的成员资格管理功能,其核心是利用内置的成员库表(SQL Server).成员资格管理API(Membership.MembershipUser ...
- 【TCP/IP实现磁盘资源的分享-----ISCSI(互联网最小应用程序接口)】
Iscsi server: 首先把多块磁盘合并为RAID5,便于后期iscis client访问以及服务端的管理 安装 targted服务端包,以及targtedcli创建iscsi TCP/IP共享 ...
- QQ群排名霸屏技术居然是这样简单
最近做了一些收费的QQ群,收多少钱,一块钱的入门费,也就是说进入我的QQ群必须要1块钱的会费. 我的QQ群主要是干嘛呢,放些电影,比如说市面上电影院,正在播放的,最新最热门的,火爆的一些电影. 先前呢 ...
- php实现redis
<?php //实例化Redis对象 $red=new Redis(); //链接redis服务 $red->connect('localhost','6379'); //具体操作 $re ...
- hive 学习系列四(用户自定义函数)
如果入参是简单的数据类型,直接继承UDF,实现一个或者多个evaluate 方法. 具体流程如下: 1,实现大写字符转换成小写字符的UDF package com.example.hive.udf; ...
- MongoDB修改数据库名,collection名
利用dropDatabase,copyDatabase修改Database名称 db.copyDatabase('old_name', 'new_name'); use old_name db.dro ...
- haproxy + keepalived 实现高可用负载均衡集群
1. 首先准备两台tomcat机器,作为集群的单点server. 第一台: 1)tomcat,需要Java的支持,所以同样要安装Java环境. 安装非常简单. tar xf jdk-7u65-lin ...
- Linux(CentOS)安装Node.JS
源码安装 比使用yum安装灵活 1.创建目录 cd /opt mkdir program cd program 2.下载安装包 wget https://nodejs.org/dist/v8.12.0 ...
- HBase配置和使用
参考官方文档 整体实现框架 图1 以下几个为组成部件 21892 HMaster 22028 HRegionServer 21553 QuorumPeerMain 2366 NameNode 2539 ...
- 20145202马超 2016-2017-2 《Java程序设计》第四周学习总结
20145202马超 2016-2017-2 <Java程序设计>第四周学习总结 教材学习内容总结 继承:打破了封装性 extends 1.提高了代码的复用性. 2.让类与类之间产生了关系 ...